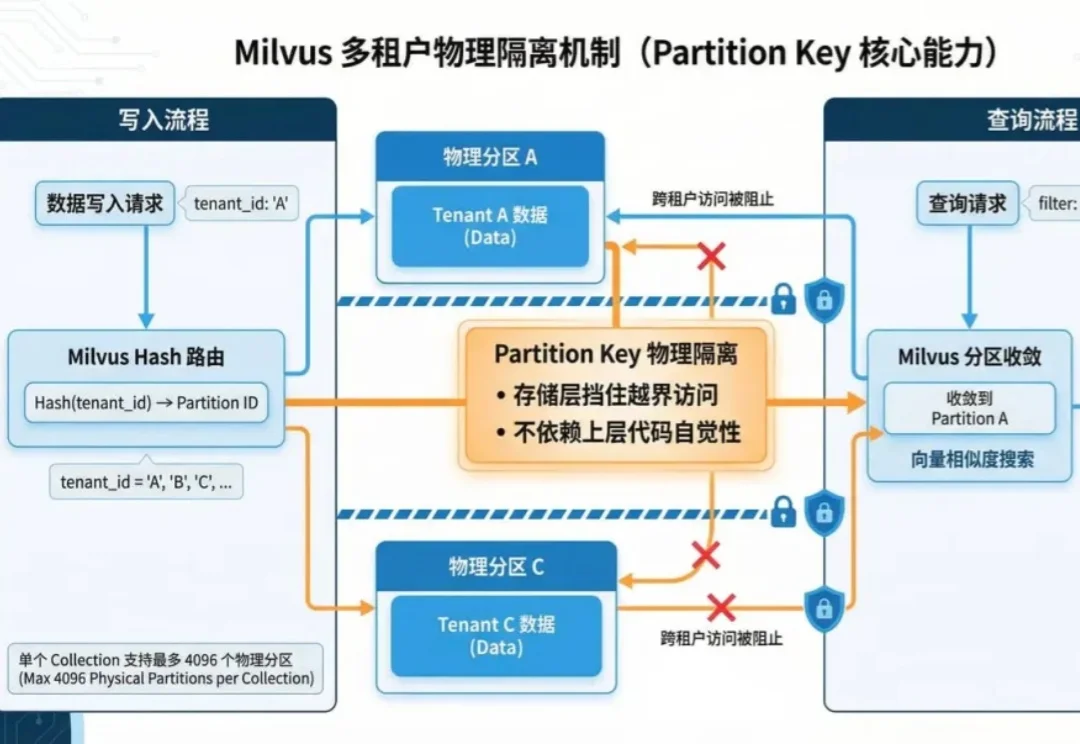
教程:如何用AutoRAG + Milvus避免RAG 与Agent 中出现串租问题
教程:如何用AutoRAG + Milvus避免RAG 与Agent 中出现串租问题多租户 RAG 与Agent系统的生产实践中,最致命的事故莫过于数据串租,系统将租户 B 的私有数据作为背景知识,回答了租户 A 的提问。
来自主题: AI技术研报
6587 点击 2026-07-02 10:35
 搜索
搜索
多租户 RAG 与Agent系统的生产实践中,最致命的事故莫过于数据串租,系统将租户 B 的私有数据作为背景知识,回答了租户 A 的提问。

知识第一次,能像代码一样利滚利。前OpenA 创始团队成员、特斯拉前 AI 高级总监 Andrej Karpathy,提出一个狠招:别再用 RAG 检索你的知识库,让大模型把它「编译」成一座持续生长的活 Wiki。两个多月,他在GitHub屠出 5000+ star。

非手机业务目标400亿美元,“飞龙”进入数据中心,高通这次整了个大的。
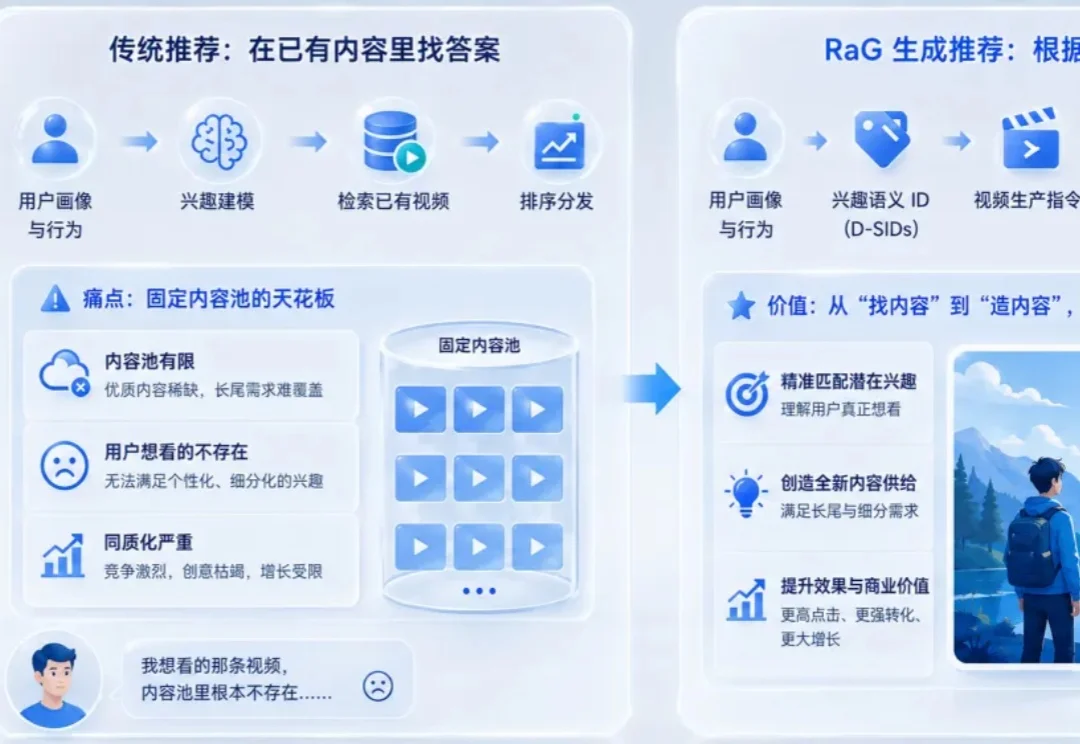
过去十年,推荐系统最核心的动作可以概括成一个字:找。
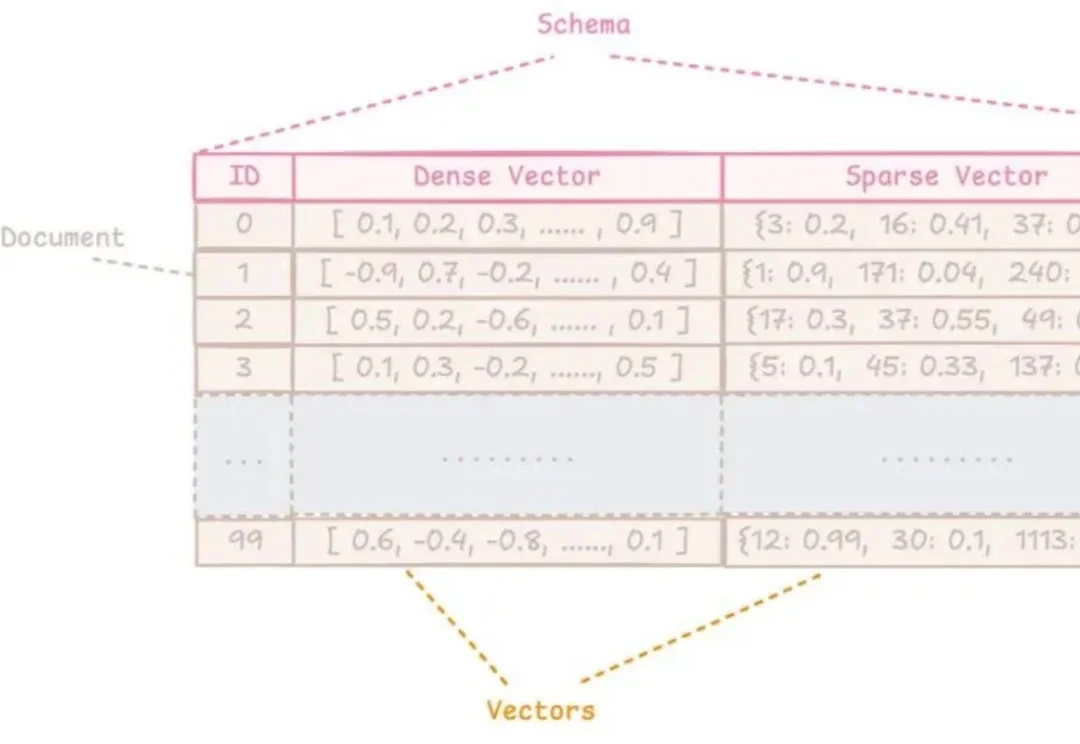
阿里开源的生产级向量数据库,跑在进程里,亿级数据毫秒响应
广州智跃深空人工智能科技有限公司 Zleap AI 提出的 SAG(SQL-Retrieval Augmented Generation) 出场了。其实,名字已经点题了——不是 Graph、Hippo,而是 SQL-Retrieval。它的核心想法是在离线阶段,SAG 先把原始文本先整理成「事项 + 实体」的数据库结构。等查询来了,再围绕当前问题,用 SQL 动态串出一张局部线索网。
Fable 5 刚上线,系统提示词就泄露: 我读了一下这份提示词,有几个点比较关键:第一,Fable 给 Artifact 新增了持久化存储 API(window.storage)。Artifact 就是 Claude 用代码生成的独内容,比如 HTML 页面、React 组件等。以前 Artifact 不能保存数据,更像个一次性 demo。

为解决科研中对单篇文献深度解析的需求,佐治亚大学团队提出IntrAgent,专注单篇内容,避免大模型幻觉。通过段落排序与迭代阅读机制,精准提取实验细节与元数据。
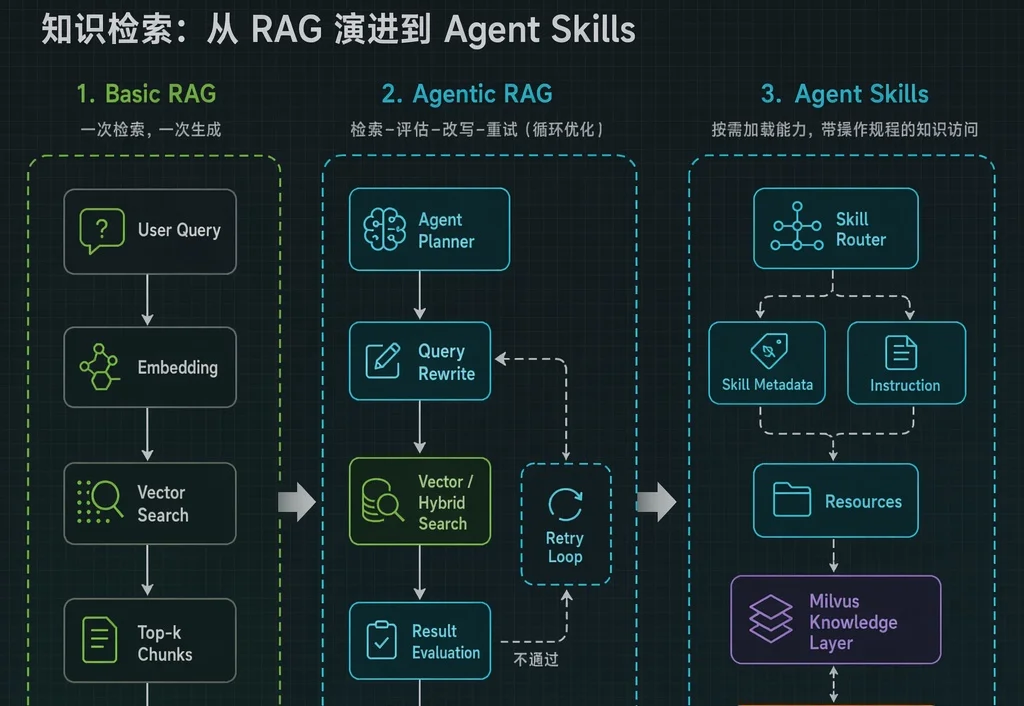
最近一两年,互联网上各种为RAG赛博哭坟的帖子不胜枚举。
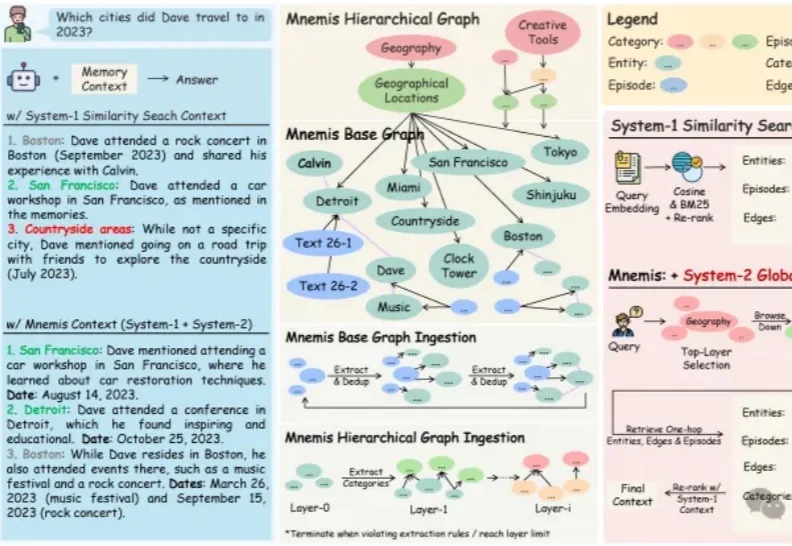
随着大语言模型在各类应用中加速落地,一个核心技术瓶颈日益凸显——AI始终缺乏真正的长期记忆能力。当前主流的RAG(检索增强生成)方案依赖语义相似度检索历史信息,但“语义相似”并不等于“真正相关”,常常出现检索结果不完整、无法区分信息相关性、缺乏推理能力等问题。