
80亿参数记性不如U盘:他算出了大模型记忆天花板
80亿参数记性不如U盘:他算出了大模型记忆天花板一个80亿参数的大模型,一口气吞下15万亿token的训练数据,堆到硬盘上差不多7TB。可它真正「背」得下来的,少得可怜:每个参数只装得下3.6 bit。一个英文字母8 bit,连半个都填不满。
来自主题: AI技术研报
8693 点击 2026-08-02 22:14
 搜索
搜索
一个80亿参数的大模型,一口气吞下15万亿token的训练数据,堆到硬盘上差不多7TB。可它真正「背」得下来的,少得可怜:每个参数只装得下3.6 bit。一个英文字母8 bit,连半个都填不满。
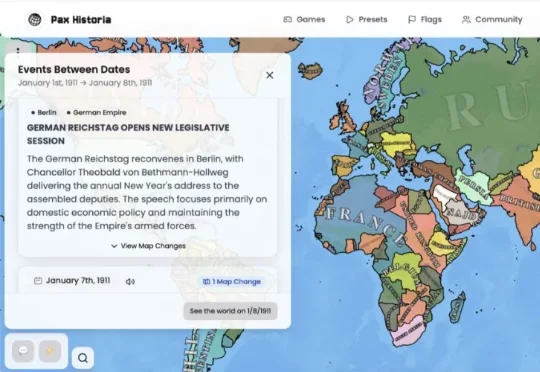
Pax Historia团队3人,日活3.5万,单周处理超过1000亿tokens。这是一款架空历史策略游戏。玩家可以控制1943年的苏联,也可以让罗马帝国继续存在,或者创建一个外星人入侵现代地球的世界。行动通过自然语言输入。玩家可以发动战争、签贸易协议、改革货币、威胁邻国,也可以直接跳过几年。

最近有个挺有意思的对比实验,来自 Composio 团队。他们用同一个模型 Kimi K3,分别放进三个不同的 agent 框架(harness)里跑 ——Claude Code、Hermes 和 Kimi Code—— 一共测了 28 个完全相同的任务。
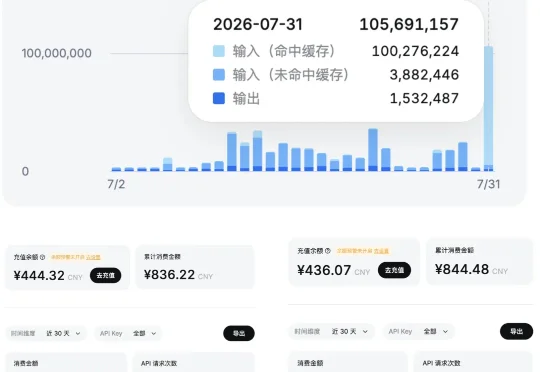
DeepSeek-V4-Flash风评冲爆了,原生支持接入Codex,而且还强化了Agent能力。我第一时间把它接进了Codex,用cc swich非常方便。一个小时,跑了一亿多token。跟大家说说体感。
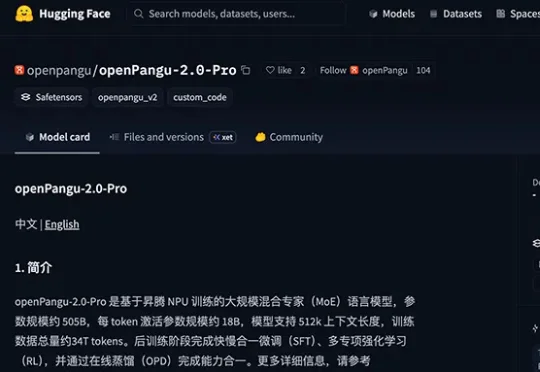
今日,华为开源基于昇腾NPU训练的盘古MoE模型openPangu-2.0-Pro。该模型是openPangu-2.0系列的最新开源模型,总参数规模5050亿,激活参数规模180亿,支持512K上下文长度,训练数据总量约34T tokens。另一轻量化模型openPangu-2.0-Flash已于6月12日开源,参数92亿,其中6亿为激活参数。
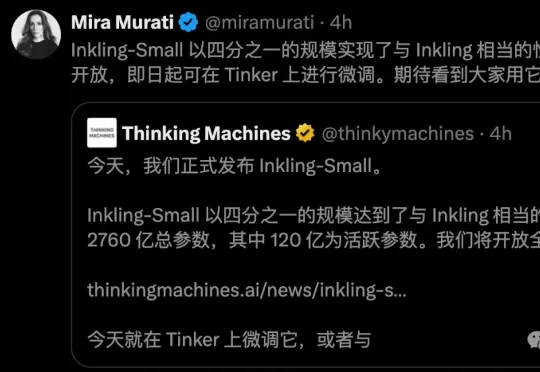
今天,Thinking Machines正式发布第二款重磅模型——Inkling-Small。276B总参数、12B激活参数,原生多模态,100万token上下文。半个月前,首个开源975B Inkling登场,曾在AI圈掀起了巨浪。
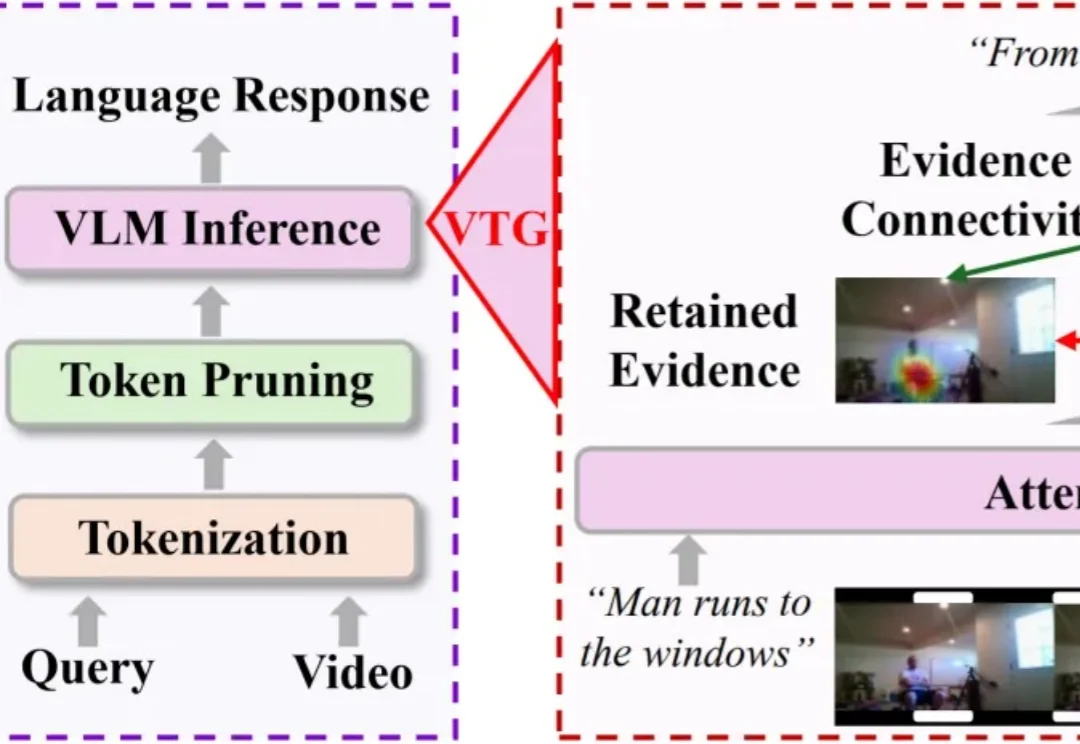
长视频理解,正在成为多模态大模型的重要能力。
过去两年,多模态模型的竞争看起来像一场“造眼睛”的竞赛:更高的图像分辨率、更多的视觉 token、更大的模型,以及更昂贵的训练。行业似乎默认,只要第一次看得足够清楚,AI 就能从“看见”抵达“洞见”。

成立刚满一年,连续完成三轮融资,总金额数亿元。
最近,月之暗面 kimi 正式开源 Kimi K3 完整模型权重,Kimi K3 是一款总参数量达 2.8 万亿、上下文窗口达 100 万 token 的 MoE 大模型,更是全球首个落地的近 3 万亿参数级开源大模型,引起业界热议。