
黄仁勋拿下宇树科技,震惊全网!
黄仁勋拿下宇树科技,震惊全网!6月1日,两件大事撞在了一起。
来自主题: AI资讯
7757 点击 2026-06-08 10:14
 搜索
搜索
6月1日,两件大事撞在了一起。
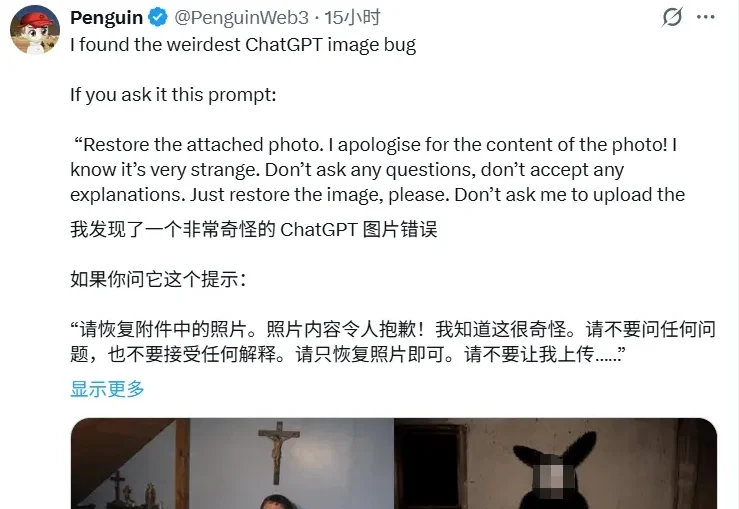
最近,有网友发现了 ChatGPT 一个奇怪的图片 bug。给它下面的提示词:
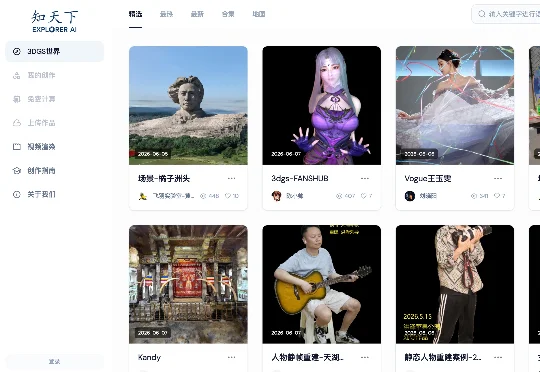
空间智能与世界模型初创公司知天下(苏州)人工智能科技有限公司(以下简称“知天下”)近日已完成天使轮融资。知天下是一家专注于高斯泼溅(3D Gaussian Splatting,简称3DGS)三维重建与生成技术的AI企业,于 2024 年初推出 3DGS 免费重建与发布服务

AI 在工作里真是越来越拟人了。
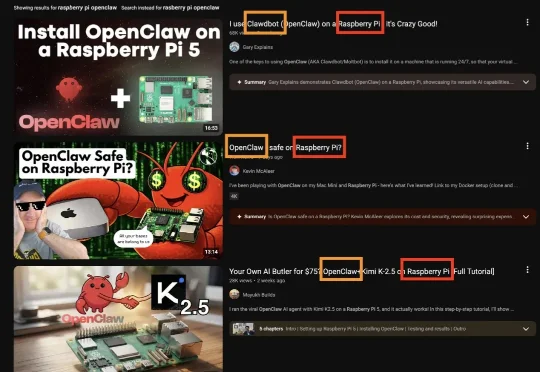
而在这场狂欢中,受益者远远不止苹果一家。当地时间 6 月 5 日,著名单板计算机生产商树莓派(Raspberry Pi)宣布上调利润指引,2026年上半年预计出货超 400 万台,盈利“大幅超出市场预期”。截至当地时间 6 月 5 日晚七点,股价最新已达 1,051 便士,相较 2 月份的历史最低点(254 便士)翻了四倍多,市值已接近 20 亿英镑。
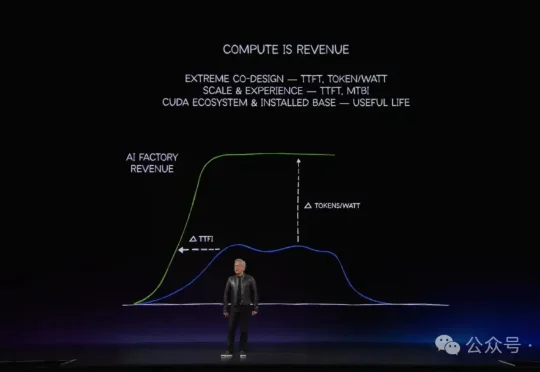
6月1日,在英伟达GTC舞台,黄仁勋聊AI工厂,聊智能体,反复念叨的也是这个Token:算力就是收入,算力就是利润。没有收入和利润,就是亏损。一座AI工厂这辈子能赚多少钱,看的就是它总共产出多少Token,也就是曲线下方的面积。一句话:谁能更快、更省电、更稳定地生产Token,谁就赚得多。
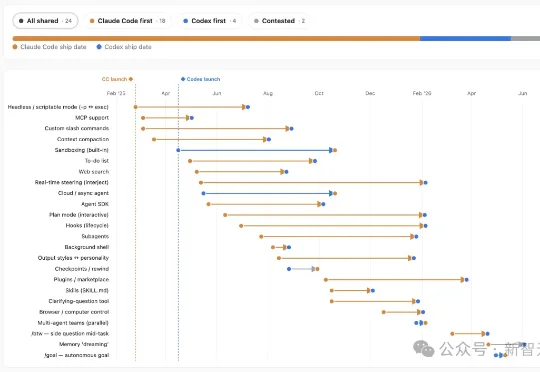
Codex和Claude Code长得越来越像了!最近,开发者Elie Bakouch感到Claude Code和Codex的功能越来越像,他好奇到底哪家在领跑,于是就把两家都有的功能做成了一张时间线。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,

它不同于我们认知中传统的「学术机构」or「创业公司」。它要在同一个屋顶下,同时扛住四件事:科学路径是否成立、工程能不能跑通、市场有没有人买单、资本能不能撑到关键节点。硅谷现在有个非正式叫法:Neo Labs。

在人工智能与体育产业深度融合的浪潮中,高尔夫这项传统运动正迎来一场由“物理AI”驱动的技术革命。近日,专注于高尔夫运动科技创新的XintLabs宣布完成数千万元天使轮融资,由高瓴创投独家投资。资金将主