
C罗刚头球破门,AI解说脱口而出!全模态实时流太狠了
C罗刚头球破门,AI解说脱口而出!全模态实时流太狠了阿里云正式宣布,Apache Flink 3.0全面进入Agentic Streaming For AI时代,并推出全模态数据流处理能力。这是业界第一次,把视频、音频、图像、文本这四类数据,统一放进同一条流式pipeline里调度,让AI能够实时感知、实时理解、实时回应。
来自主题: AI资讯
7444 点击 2026-06-27 12:24
 搜索
搜索
阿里云正式宣布,Apache Flink 3.0全面进入Agentic Streaming For AI时代,并推出全模态数据流处理能力。这是业界第一次,把视频、音频、图像、文本这四类数据,统一放进同一条流式pipeline里调度,让AI能够实时感知、实时理解、实时回应。

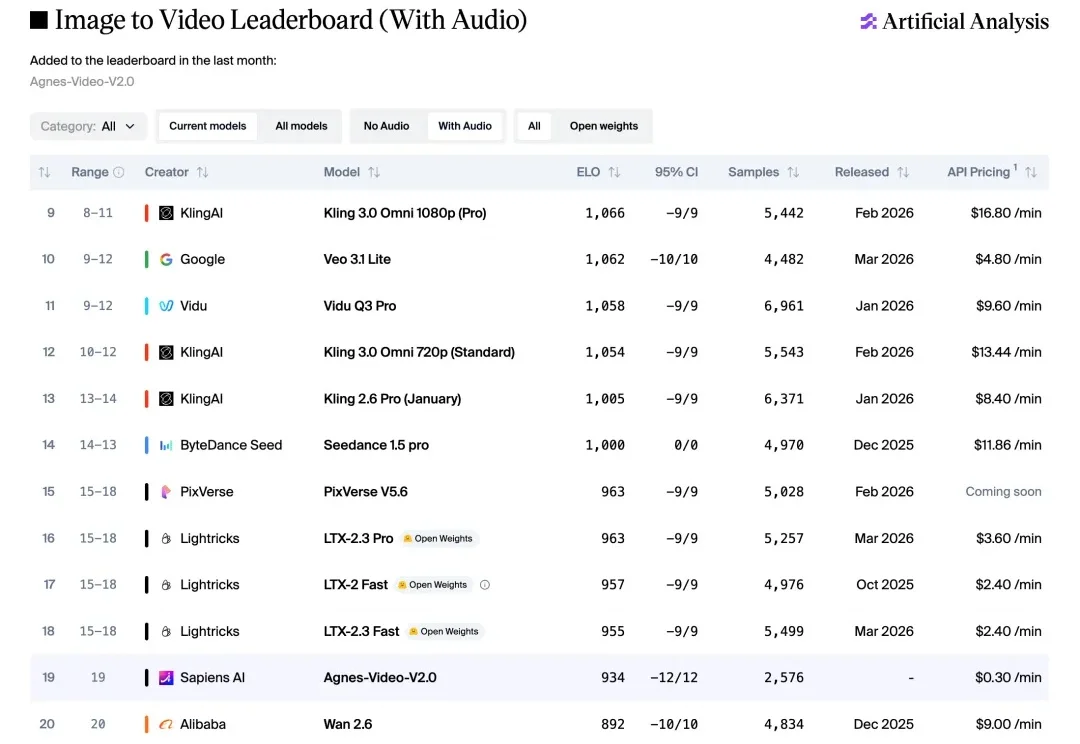
全模态算力狂欢开启:全球前十AI巨头无限期免费API,周调用爆破3.12万亿Token!本周Agnes的王炸升级了:1M超长上下文+4K超清画质「零成本」白嫖,开源社区已玩疯,独立开发者和小团队速来薅秃!
在这场日益蔓延的“Token焦虑”中,Agnes AI的举动显得格外扎眼——这家全球榜单排名第九的AI Lab宣布,自6月1日起,旗下全模态模型API无限期免费开放。Agnes AI本次开放覆盖其三款核心模型:文本模型Agnes-2.0-Flash、图像模型Agnes-Image-2.0-Flash以及视频模型Agnes-Video-V2.0。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。

智象未来正式发布基于新一代原生全模态模型架构 Unified Transformer(UiT)打造的图像大模型 HiDream-O1-Image-Pro。这一超2千亿参数的原生全模态图像大模型,不仅在多个基准测试中刷新 SOTA 纪录,也标志着智象未来正向图像、视频、文本、音频等多模态统一建模的“原生全模态”阶段迈进。
幽深森林,身着飘逸浅裙的乐手忘情地拉动琴弦。阳光穿透树冠洒落林间,斑驳光影与悠扬的琴声相融。镜头自低处仰拍环绕,营造出如梦似幻的氛围。

5月初的一个上午,我走进杭州西溪附近的一间办公室,眼前的人被同事叫醒,从地板上爬起来。头戴一顶深灰色、紧紧包住脑袋的绒布帽,上身是一件紫色紧身短袖上衣,露出清晰可见的肌肉线条,而下身是一条黑色长裙。
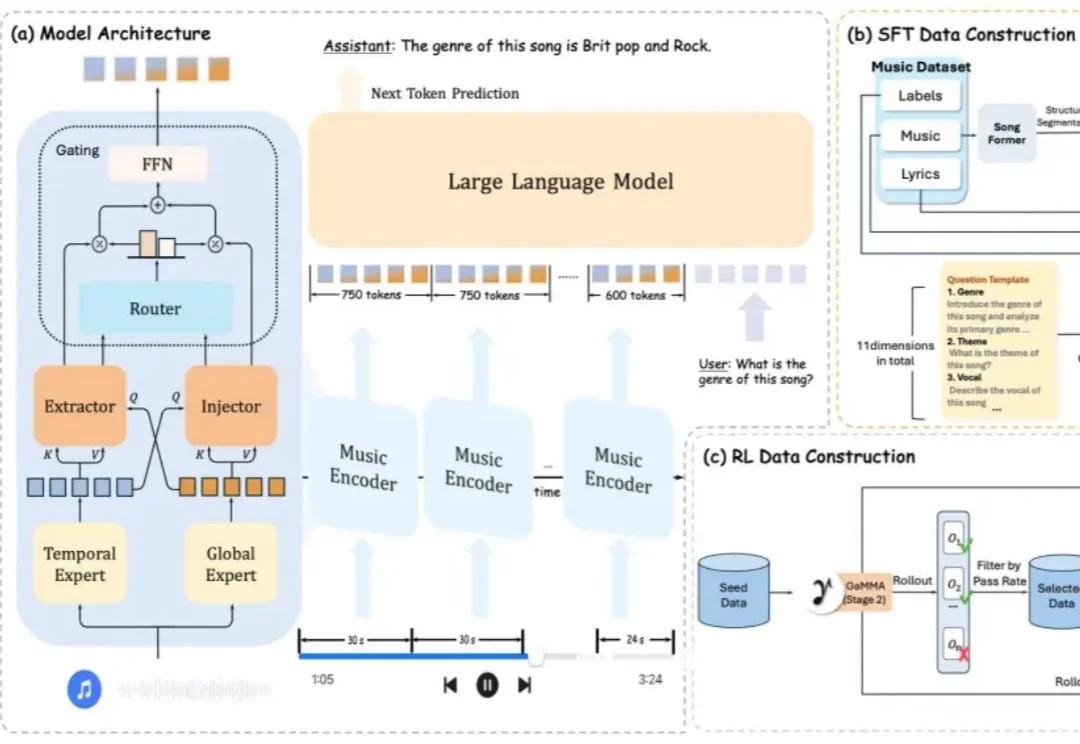
大模型的能力边界正在不断拓展,从文字到视觉,再到音频,全模态理解已渐成现实。然而,当你问一个多模态大模型「这首歌的高潮从第几秒开始?」或者「第 30 秒之后乐器编配发生了什么变化?」,得到的往往是一个模糊甚至错误的回答。

jina-embeddings-v5-omni正式发布,我们把 v5-text 向量模型的能力延伸到图像、音频和视频。文本侧不变,v5-omni 产出的文本向量与 v5-text逐字节一致,无需重建任何已有索引。

在前不久的 AI TECH DAY 上,斑马智能又新发布了“元神 AI 汽车机器人大脑”,同时推出 AutoOmni 全模态端模型产品矩阵与“龙虾上车”方案 AutoClaw,构成所谓的“一脑双引擎”升级。这不只是一轮产品迭代,更像在做一次预判:汽车正在从功能的集合机器,变成一个可以持续进化、还能主动协作的的智能体系统。