
公司注册10天,估值逾10亿美元!理想智驾大牛刷出具身创投新热度
公司注册10天,估值逾10亿美元!理想智驾大牛刷出具身创投新热度一家具身智能公司,3月初刚刚注册,3月还没过完,估值就已远远超过10亿美元……
来自主题: AI资讯
8809 点击 2026-04-01 09:40
一家具身智能公司,3月初刚刚注册,3月还没过完,估值就已远远超过10亿美元……
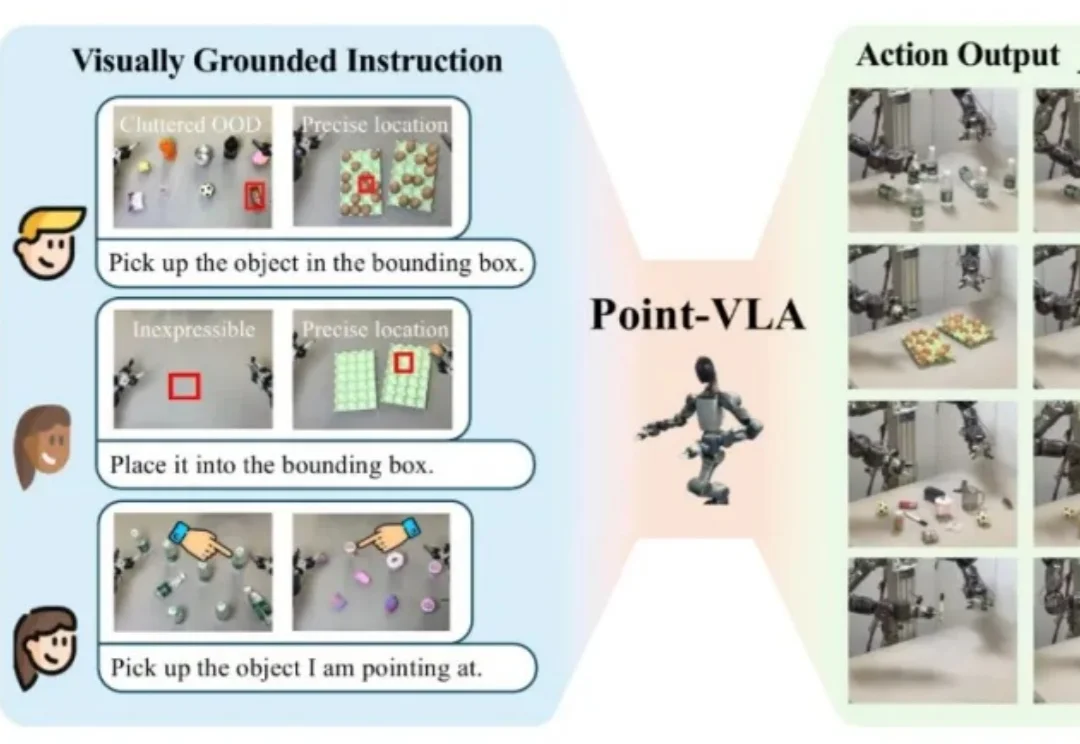
设想这样一个场景:你打电话让同事去办公室某个地方拿东西,仅凭语言描述位置是多么困难。在办公室里,从一堆已经喝过的矿泉水瓶中,让对面同学递过来你之前喝过的那个,只用语言几乎无法准确描述——「左边第二个」?「有点旧的那个」?这时候,人们更倾向于用手指一下,或者拿出图片来指代。
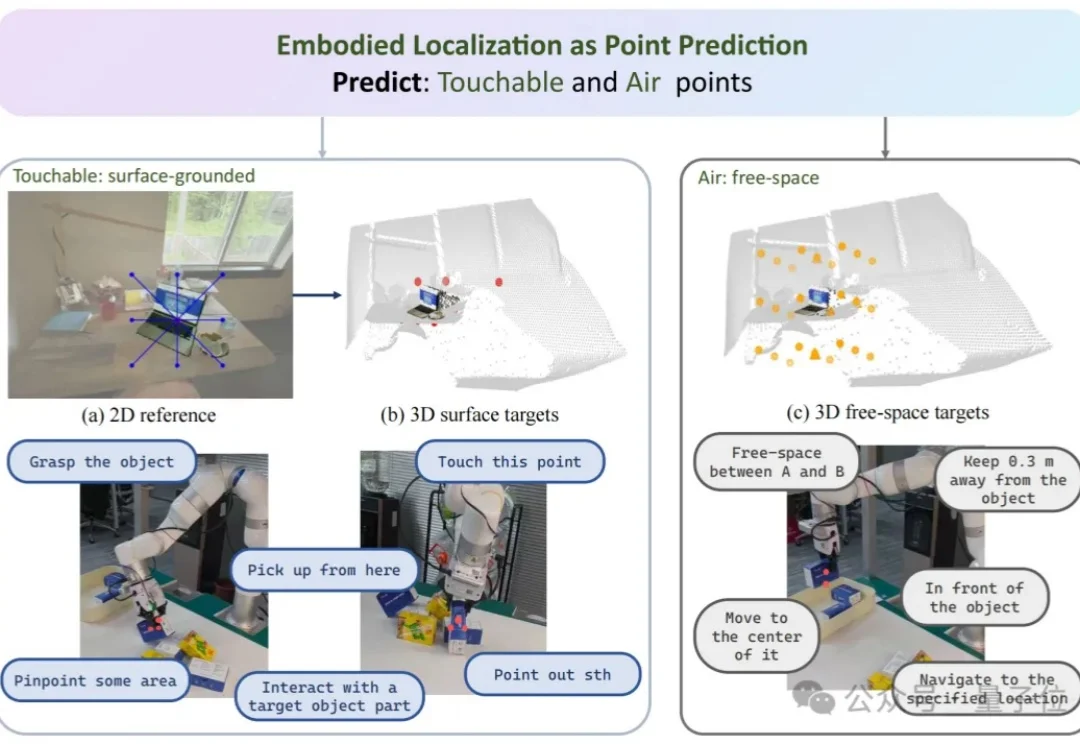
机器人能认出杯子,却看不懂杯口朝哪、离自己多远、该抓哪里。
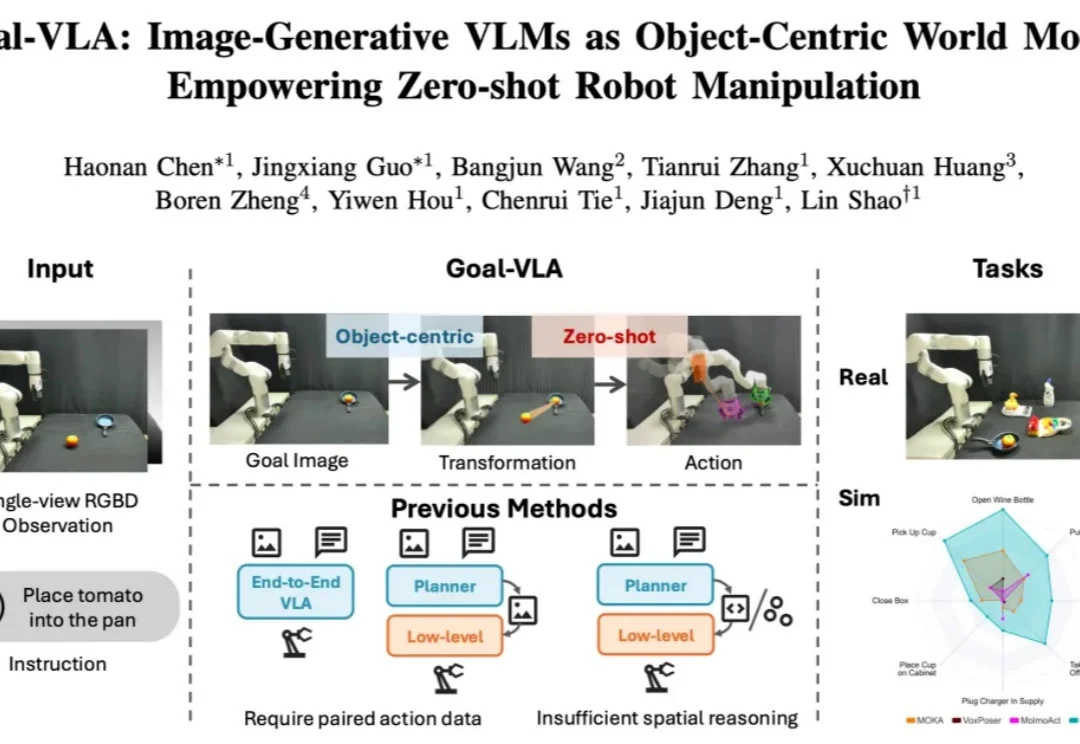
在具身智能领域,机器人操作的泛化能力一直是一个核心挑战。当前,视觉 - 语言 - 动作(VLA)模型主要分为两大范式:端到端模型与分层模型。端到端 VLA 模型(如 RT-2 [1], OpenVLA [2])严重依赖海量的 “指令 - 视觉 - 动作” 成对数据,获取成本极高,导致其在面对新任务或新场景时零样本泛化能力受限。

就在行业仍为数据瓶颈焦虑时,一家名为深度机智(DeepCybo)的公司悄然浮出水面。投中网独家获悉,作为北京中关村学院与中关村人工智能研究院孵化的首家具身智能企业,它凭借独特的“人类第一视角”技术路线,在短短3周内吸引了超60家投资机构密集对接。
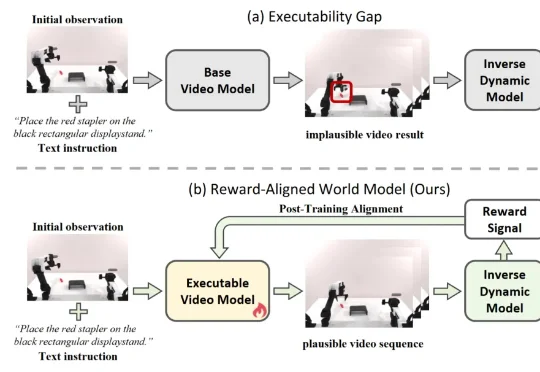
近期,利用视频生成模型为机器人构建 “世界模型”,已成为具身智能领域的热门技术路线。给定当前观测和自然语言指令,这类模型能够先 “想象” 出未来的视觉轨迹,再由逆动力学模型(IDM)将生成画面解码为机器人动作,从而形成 “先预测、后执行” 的解耦式规划范式。由于兼具较强的可解释性与开放场景泛化潜力,这一路线正在受到学术界和工业界的广泛关注。
「人形机器人如果有最终形态,那一定会是有头有脸,你觉得呢?」

想象一下这样的生活片段:你拿起手机 30 秒,屏幕立刻跳出提醒,“当前心率 78,压力中等,建议深呼吸”;家里的智能摄像头静静看着午睡的宝宝,突然通过 App 提醒你:“宝宝心率偏快,呼吸略显急促,建议进屋查看”;养老院里,巡检机器人通过一次擦身而过的对视,便能感知到老人今天情绪低落,且血氧饱和度略低于往常......

天使轮拿下2.42亿美元后,它石智航到底干啥去了?然而接下来的一年里,它石智航选择了一条截然不同的路:没有参加各种行业大会,没有频繁对外发声,没有出现在春晚或各类展示活动中,一直踏实干活。
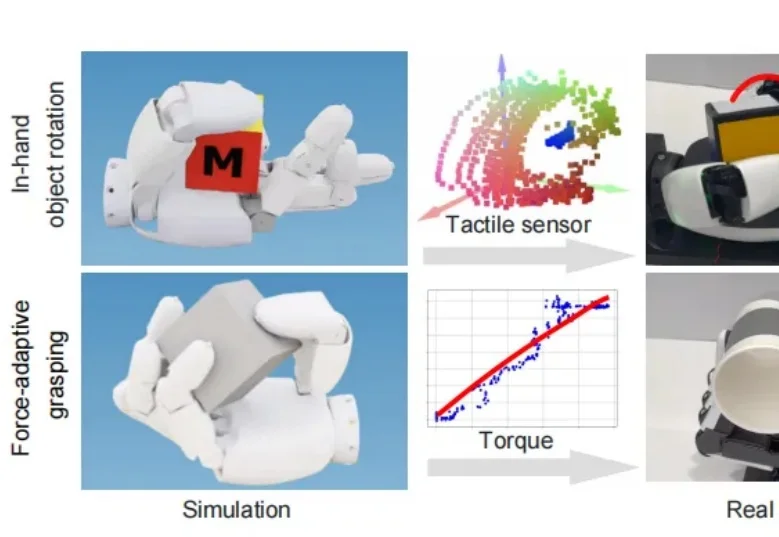
实现具备人类水平的灵巧操作能力,是机器人学领域长期以来的核心挑战之一。尽管多指灵巧手在硬件上具备了类似人类的潜力,但由于接触丰富的物理特性和非理想的驱动机制,训练能够直接部署在真实硬件上的控制策略仍然非常困难。