又一国产模型黑马出世,追平Gemini 2.5 Pro,空间编辑反超视频模型?
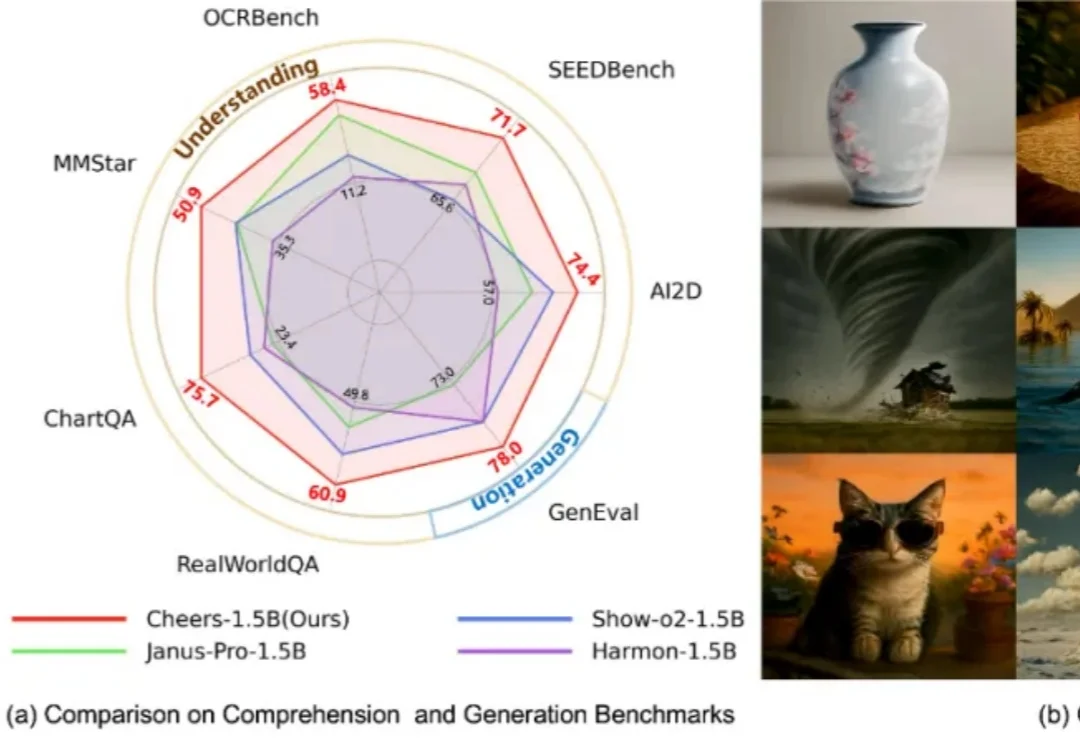
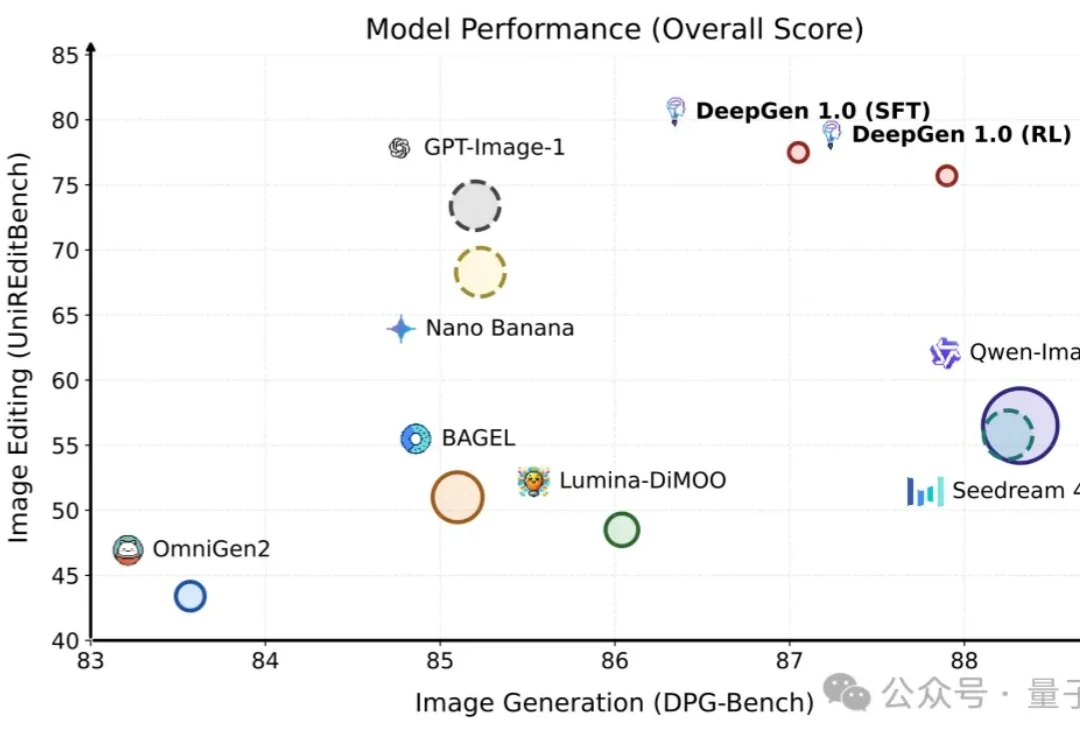
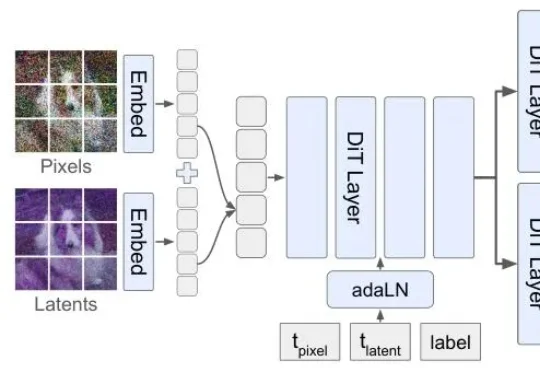
又一国产模型黑马出世,追平Gemini 2.5 Pro,空间编辑反超视频模型?近日,京东开源图像模型JoyAI-Image-Edit,将空间智能纳入图像理解与编辑,让AI开始处理真实世界中的空间关系,让模型真正“理解空间,编辑空间”。简单解释,这是一个以空间智能为核心的图像生成与编辑模型,让 AI 真正“看懂”三维空间,从而让生成更合理、编辑更精准。
来自主题: AI资讯
9216 点击 2026-04-10 21:09