
SGLang Diffusion震撼发布:图像视频生成速度猛提57%!
SGLang Diffusion震撼发布:图像视频生成速度猛提57%!就在一周前,全宇宙最火爆的推理框架 SGLang 官宣支持了 Diffusion 模型,好评如潮。团队成员将原本在大语言模型推理中表现突出的高性能调度与内核优化,扩展到图像与视频扩散模型上,相较于先前的视频和图像生成框架,速度提升最高可达 57%:
来自主题: AI技术研报
9088 点击 2025-11-22 11:33
 搜索
搜索
就在一周前,全宇宙最火爆的推理框架 SGLang 官宣支持了 Diffusion 模型,好评如潮。团队成员将原本在大语言模型推理中表现突出的高性能调度与内核优化,扩展到图像与视频扩散模型上,相较于先前的视频和图像生成框架,速度提升最高可达 57%:
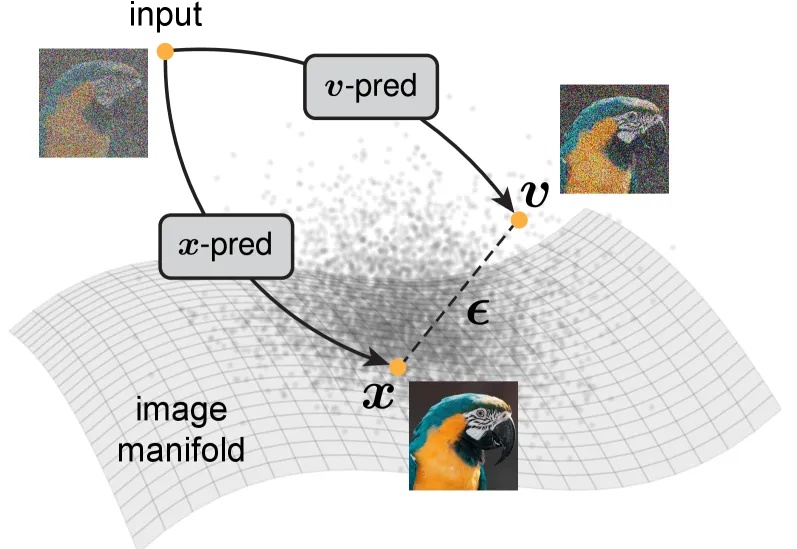
大家都知道,图像生成和去噪扩散模型是密不可分的。高质量的图像生成都通过扩散模型实现。
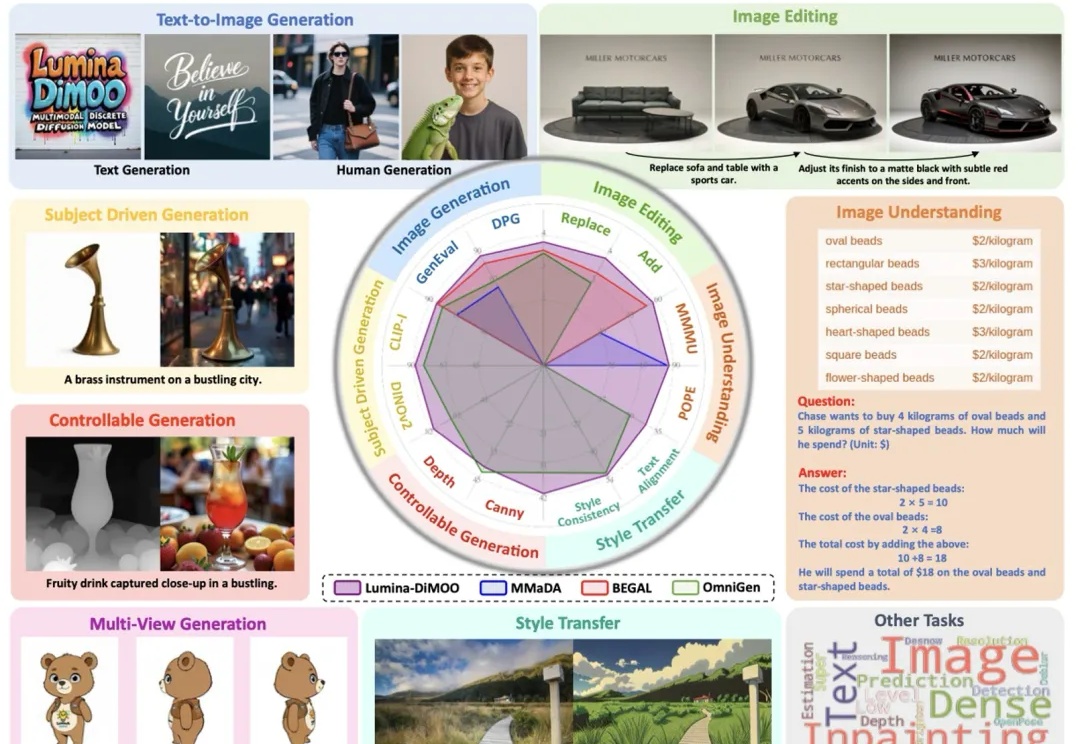
上海人工智能实验室推出了一款革新的多模态生成理解一体化的扩散语言模型 ——Lumina-DiMOO。基于离散扩散建模(Discrete Diffusion Modeling),Lumina-DiMOO 打破了多模态任务之间的壁垒,在同一离散扩散框架下,完成从 文本→图像、图像→图像、图像→文本的全栈能力闭环。

2025年11月4日,一家总部位于英国伦敦的人工智能公司Stability AI,赢得了一项具有里程碑意义的高等法院案件,该案审查了人工智能模型在未经许可的情况下使用大量受版权保护数据的合法性。而本案的原告,Getty Images 在针对人工智能公司 Stability AI 图像生成产品的英国诉讼中基本败诉。

当下的文本生成图像扩散模型取得了长足进展,为图像生成引入布局控制(Layout-to-Image, L2I)成为可能。

LayerComposer革新了个性化图像生成,让用户像在Photoshop里一样自由操控元素位置、大小,解决传统方法交互性与多主体扩展难题,实现更自然、高效的创作,推动个性化生成迈向主动交互新阶段。

近年来,基于扩散模型的图像生成技术发展迅猛,催生了Stable Diffusion、Midjourney等一系列强大的文生图应用。然而,当前主流的训练范式普遍依赖一个核心组件——变分自编码器(VAE),这也带来了长久以来困扰研究者们的几个问题:
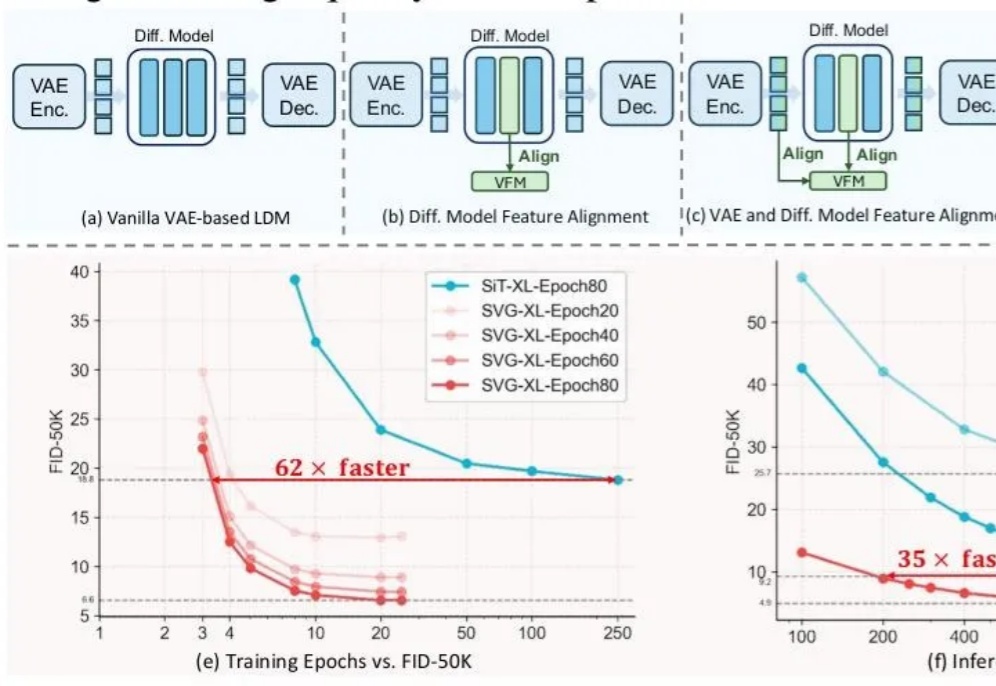
前脚谢赛宁刚宣告VAE在图像生成领域退役,后脚清华与快手可灵团队也带着无VAE潜在扩散模型SVG来了。
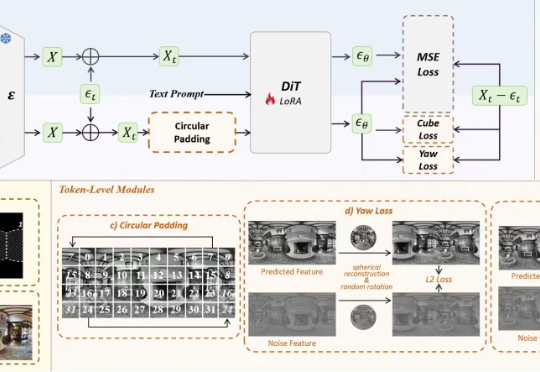
空间智能领域的全景数据稀缺问题,有解了。影石研究院团队,推出了基于DiT架构的全景图像生成模型DiT360。通过全新的全景图像生成框架,DiT360能够实现高质量的全景生成。
一张图,一个3D世界!今天,李飞飞团队重磅放出实时生成世界模型「RTFM」,通过端到端学习大规模视频数据,直接从输入2D图像生成同一场景下新视角的图像。值得一提的是,它仅需单块H100 GPU便能实时渲染出持久且3D一致的世界。