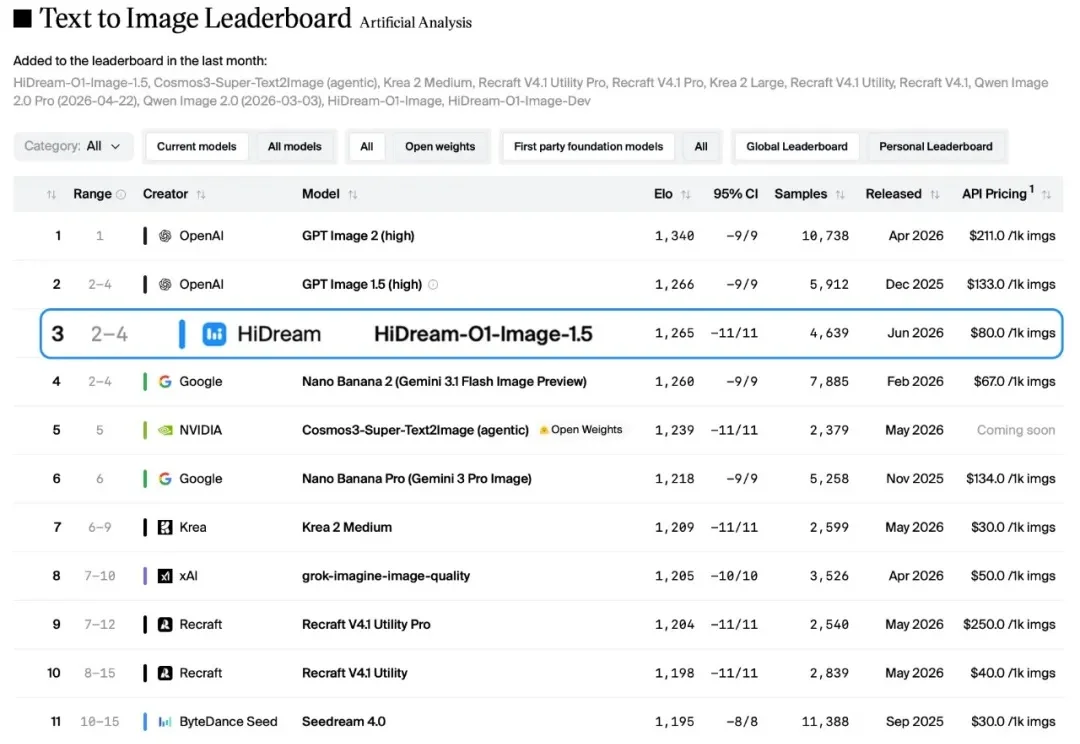
HiDream-O1-Image-1.5 刷新国产图像生成模型纪录:砍掉 VAE,是图像模型的未来吗?
HiDream-O1-Image-1.5 刷新国产图像生成模型纪录:砍掉 VAE,是图像模型的未来吗?文生图的"慢思考",到底有没有用?
来自主题: AI资讯
6312 点击 2026-06-11 10:41
 搜索
搜索
文生图的"慢思考",到底有没有用?
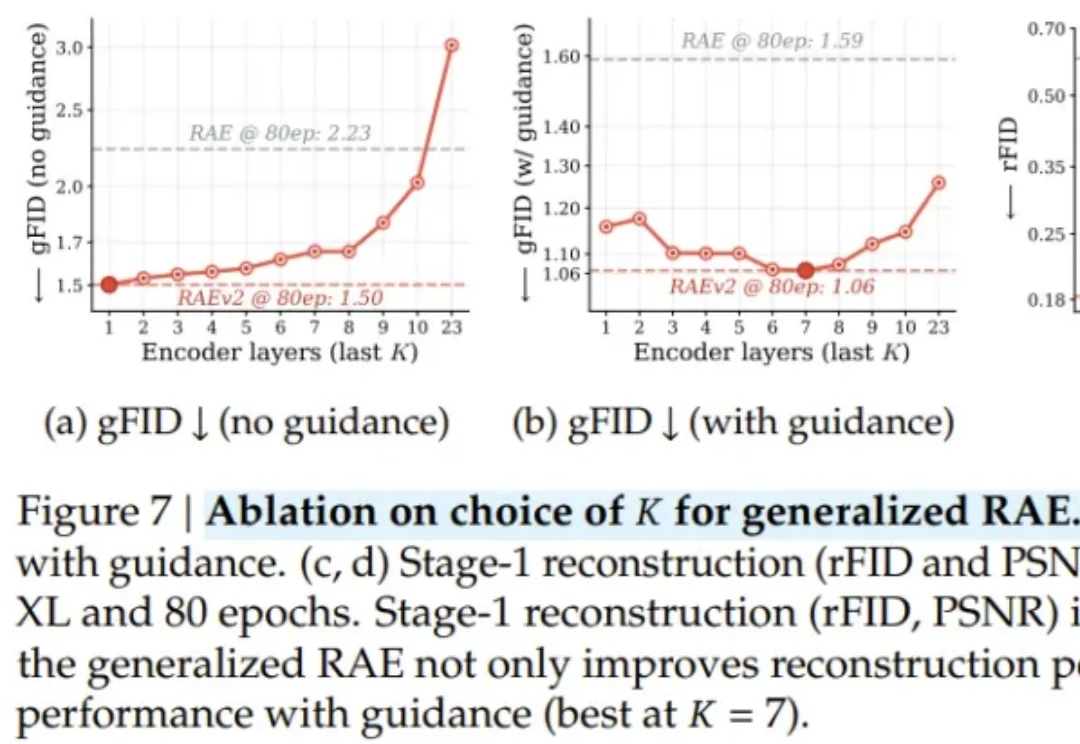
AI 图像生成通常遵循「能力越强、代价越高」的铁律;与此同时,学界却在悄悄质疑另一个更根本的浪费:传统 VAE 对图像语义几乎一无所知,而 DINOv2、SigLIP 等视觉编码器早已从数亿张图片中习得了丰富的视觉常识。图像生成模型,真的需要从零开始「发明」对图像的理解吗?
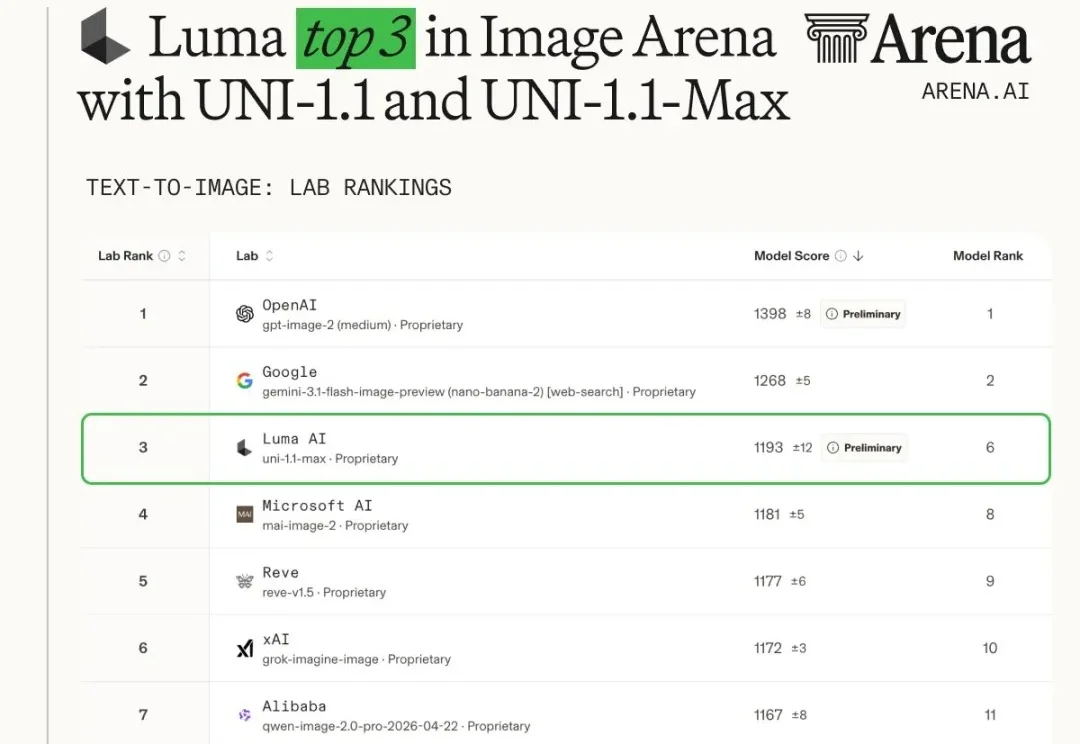
今年以来,图像生成模型的迭代节奏明显加快。

当强化学习后训练的大规模 rollout 已经被证明能够提升图像生成模型的偏好对齐能力,推理负担就成了制约训练速度的核心瓶颈。来自 NVIDIA、港大和 MIT 的团队提出的 Sol-RL,通过「FP4 先探索、BF16 再训练」的后训练框架,将达到等效 reward 水平的收敛速度最高提升到 4.64x,在训练速度与对齐效果之间给出了一条更具工程可行性的解法。

过去两年,图像生成模型在质感和审美上一路狂飙,但大多仍是 “直接出图” 的范式。

AI不再只是把两个物体「放一起」,而是真正造出一个新实体。VMDiff模型通过分阶段策略:先拼接保留信息,再插值融合成整体,并自动调节平衡,让生成结果既像两者,又自然统一。 过去,很多图像生成模型都能同时画出两个物体;但要让它们真正「长成一个新物体」,其实远没有那么简单。
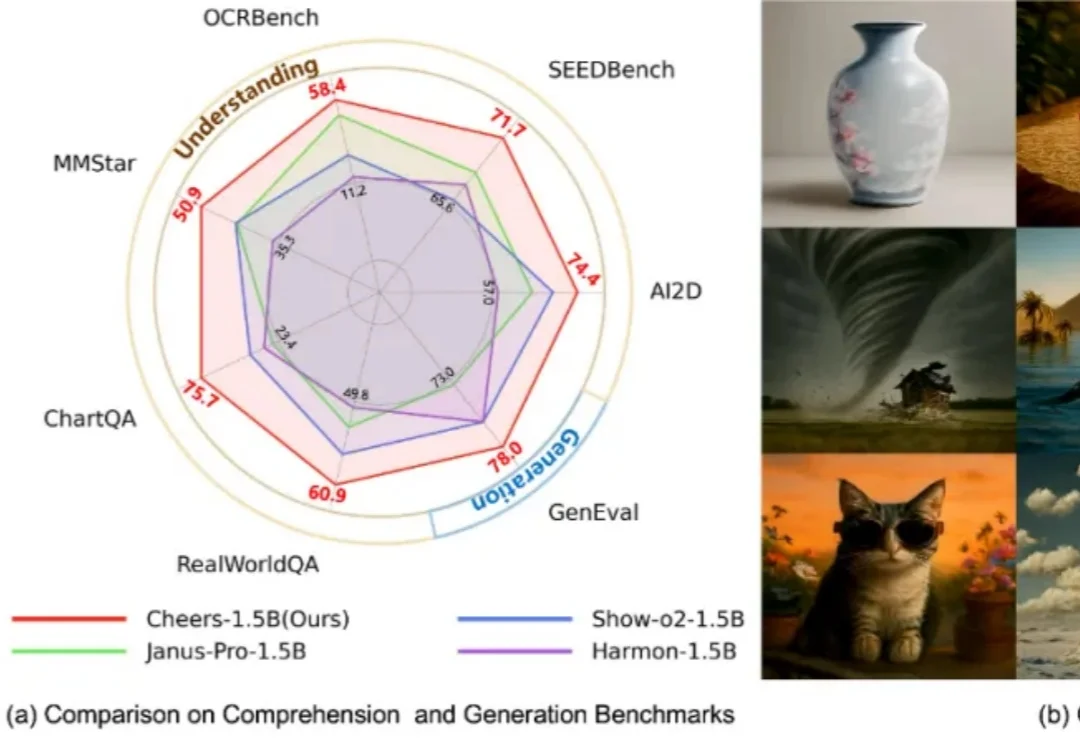
过去几年,多模态模型在理解任务上快速演进,图像问答、OCR、视觉推理、跨模态对话等能力不断提升;与此同时,图像生成模型也在视觉质量、指令遵循和细节表达上持续突破。下一步一个自然的问题是:能否用同一个模型,同时做好理解与生成?这正是统一多模态模型(Unified Multimodal Models, UMMs)正在回答的问题。
新模型对标Nano Banana Pro,能免费体验。Seedance 2.0的热度还没下去,字节新模型又来了!今日,字节图像生成模型Seedream 5.0 Preview在视频编辑应用剪映、剪映海外版Capcut、字节AI创作平台小云雀均已上线,在即梦AI平台开启灰度测试,图片生成可限时免费体验。
今天,首个在国产芯片上完成全程训练的SOTA(最佳水平)多模态模型开源。这是智谱联合华为开源的图像生成模型GLM-Image。从数据到训练的全流程,该模型完全基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成构建。

抽奖式的生图体验,确实让很多设计师在尝鲜之后又默默打开了 Photoshop。于是乎,阿里千问团队再次出手,开源了一个叫 Qwen-Image-Layered 的模型,试图从底层逻辑上解决这个问题。