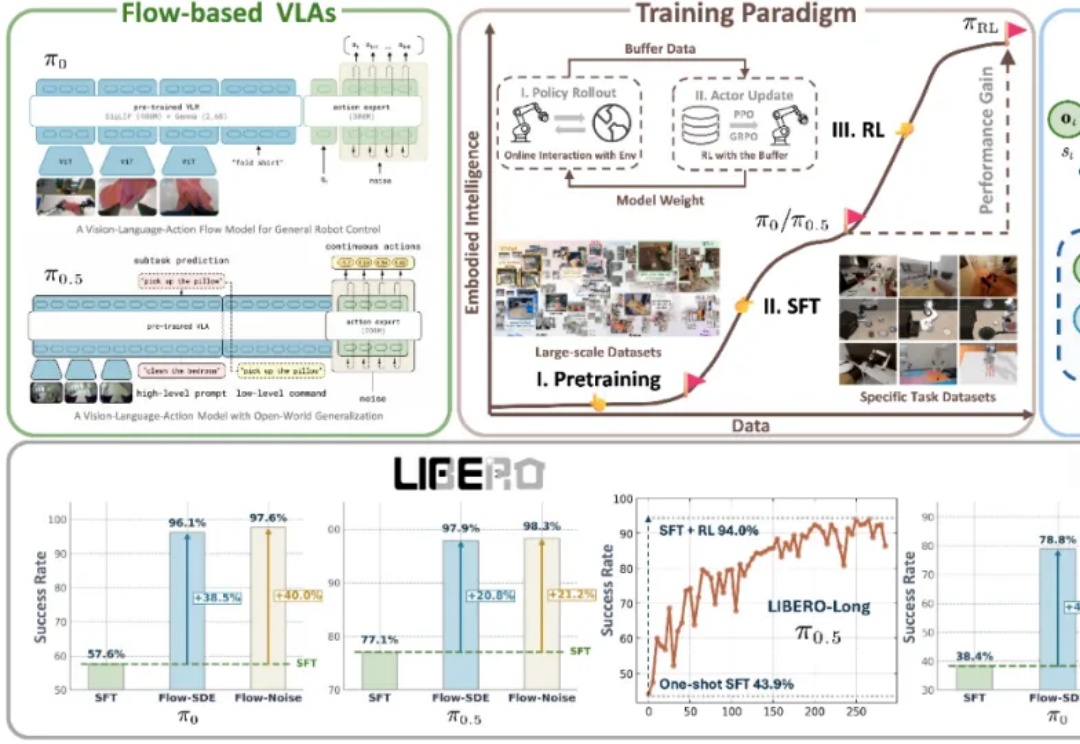
RLinf上新πRL:在线强化学习微调π0和π0.5
RLinf上新πRL:在线强化学习微调π0和π0.5近年来,基于流匹配的 VLA 模型,特别是 Physical Intelligence 发布的 π0 和 π0.5,已经成为机器人领域备受关注的前沿技术路线。流匹配以极简方式建模多峰分布,能够生成高维且平滑的连续动作序列,在应对复杂操控任务时展现出显著优势。
来自主题: AI技术研报
12072 点击 2025-11-07 10:17
 搜索
搜索
近年来,基于流匹配的 VLA 模型,特别是 Physical Intelligence 发布的 π0 和 π0.5,已经成为机器人领域备受关注的前沿技术路线。流匹配以极简方式建模多峰分布,能够生成高维且平滑的连续动作序列,在应对复杂操控任务时展现出显著优势。

斯坦福等新框架,用在线强化学习让智能体系统“以小搏大”,领先GPT-4o—— AgentFlow,是一种能够在线优化智能体系统的新范式,可以持续提升智能体系统对于复杂问题的推理能力。

随着多模态大模型的不断演进,指令引导的图像编辑(Instruction-guided Image Editing)技术取得了显著进展。然而,现有模型在遵循复杂、精细的文本指令方面仍面临巨大挑战,往往需要用户进行多次尝试和手动筛选,难以实现稳定、高质量的「一步到位」式编辑。
浙江大学与通义实验室Mobile-Agent团队在UI-R1的基础上,推出全新研究成果——UI-S1,提出了一种名为半在线强化学习(Semi-online Reinforcement Learning)的创新训练范式。
Cursor Tab 是 Cursor 的核心功能之一,它通过分析开发者的编码行为,智能预测并推荐后续代码,开发者仅需按下 Tab 键即可采纳。然而,它也面临着一个 AI 普遍存在的难题:「过度热情」。有时,它提出的建议不仅毫无用处,甚至会打断开发者的思路。

本文提出 LUFFY 强化学习方法,一种结合离线专家示范与在线强化学习的推理训练范式,打破了“模仿学习只学不练、强化学习只练不学”的传统壁垒。LUFFY 通过将高质量专家示范制定为一种离策略指引,并引入混合策略优化与策略塑形机制,稳定地实现了在保持探索能力的同时高效吸收强者经验。

通过过程奖励模型(PRM)在每一步提供反馈,并使用过程优势验证器(PAV)来预测进展,从而优化基础策略,该方法在测试时搜索和在线强化学习中显示出比传统方法更高的准确性和计算效率,显著提升了解决复杂问题的能力。