视频生成作为多模态推理新范式 | CVPR 2026
视频生成作为多模态推理新范式 | CVPR 2026被CVPR 2026收录!
来自主题: AI技术研报
9568 点击 2026-06-15 09:47
 搜索
搜索
被CVPR 2026收录!
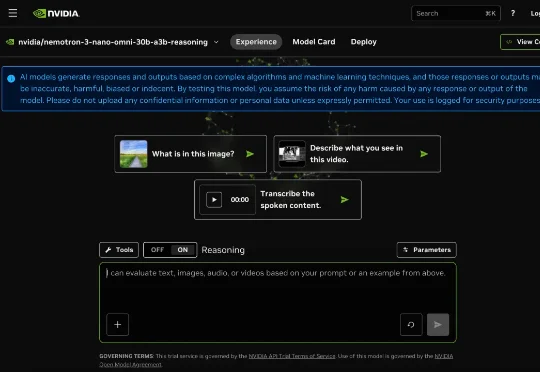
英伟达于昨日正式推出全新多模态推理模型Nemotron 3 Nano Omni,将文本、视觉、语音三大模态能力深度融合至单一模型体系,目前可免费使用。

NUS、ZJU、UW、Stanford、CUHK 联合提出 「ThinkMorph」,主张让文字与图像在统一架构里「原生协作」、「共同演化」,而不是像当下大多数多模态模型那样,看完图像就闭上眼睛,后续完全靠文字链条推进。仅用 2.4 万条数据微调 7B 统一模型,视觉推理平均提升 34.74%,多项任务比肩甚至超越 GPT-4o 和 Gemini 2.5 Flash。
10B参数拥有媲美千亿级模型的多模态推理实力。

Deepmind推出的SIMA 2,让智能体能在虚拟环境(商业游戏)中,边聊天边进行复杂的多模态推理。作为具身通用智能的原型,SIMA 2已从静态数据集迈向无限程序化生成的训练场。
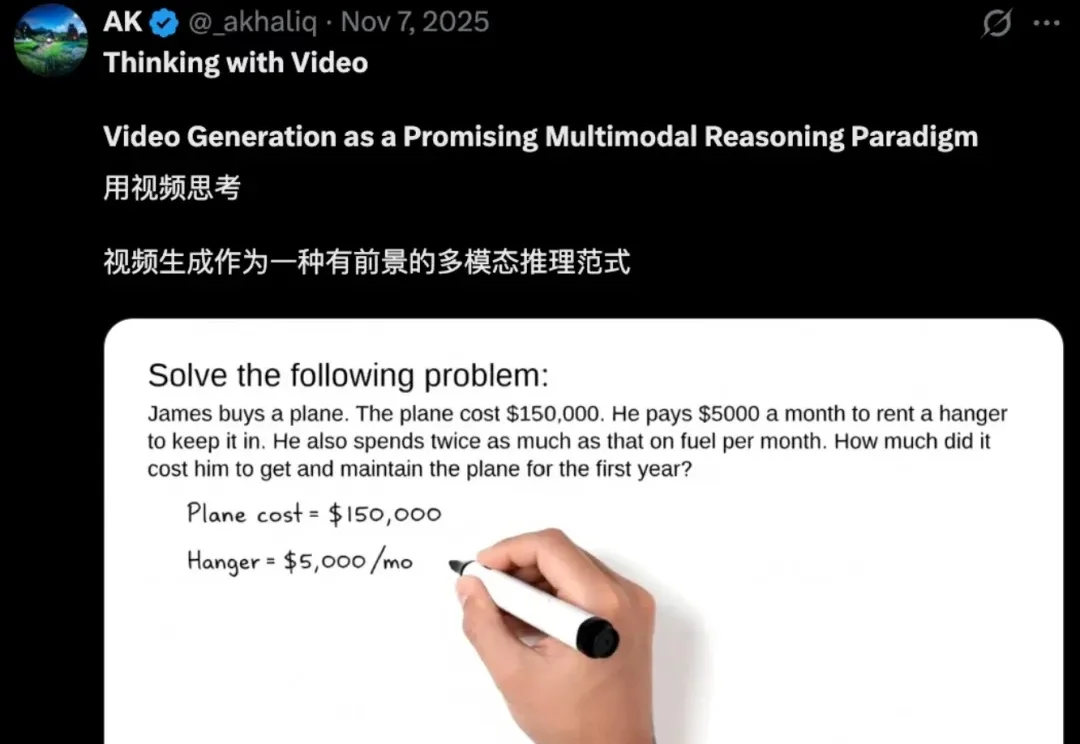
在多模态大模型(MLLMs)领域,思维链(CoT)一直被视为提升推理能力的核心技术。然而,面对复杂的长程、视觉中心任务,这种基于文本生成的推理方式正面临瓶颈:文本难以精确追踪视觉信息的变化。形象地说,模型不知道自己想到哪一步了,对应图像是什么状态。
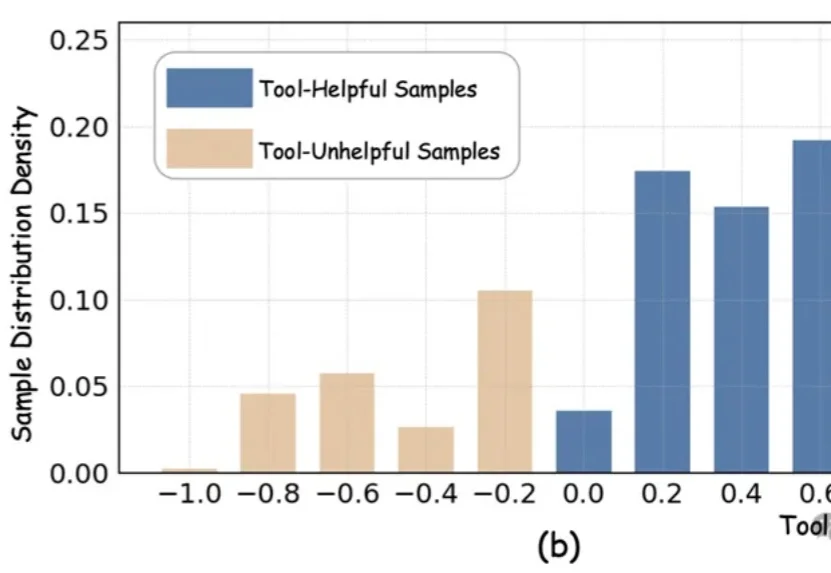
近期,以DeepEyes、Thymes为代表的类o3模型通过调用视觉工具,突破了传统纯文本CoT的限制,在视觉推理任务中取得了优异表现。
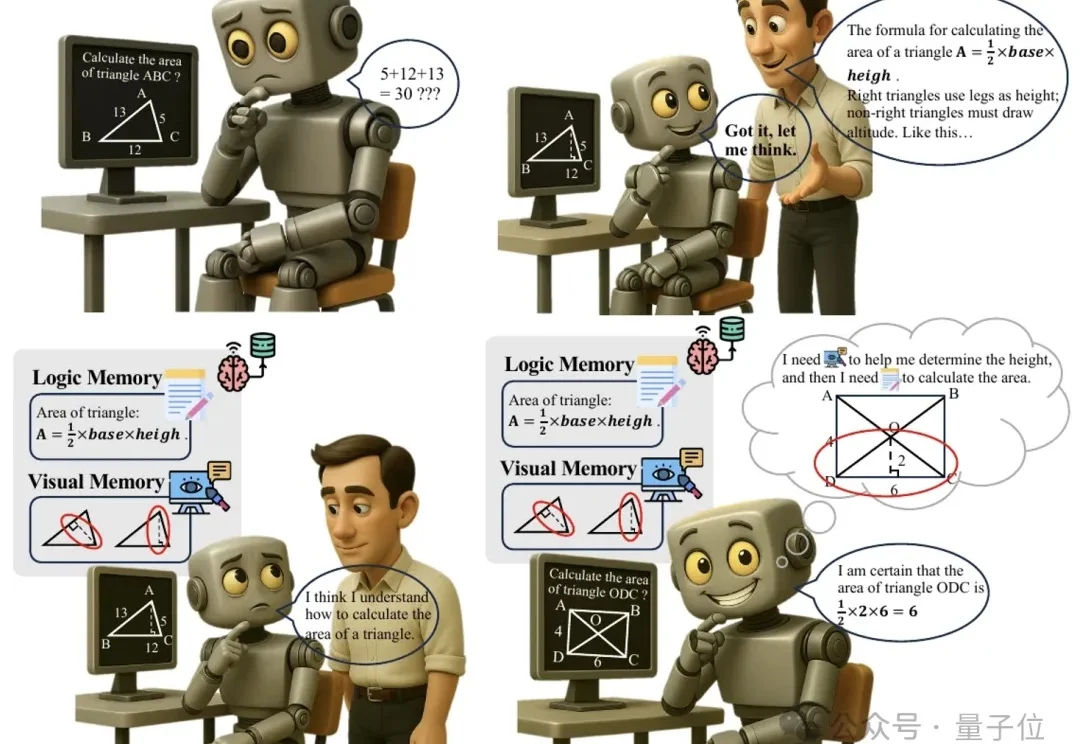
多模态推理又有新招,大模型“记不住教训”的毛病有治了。
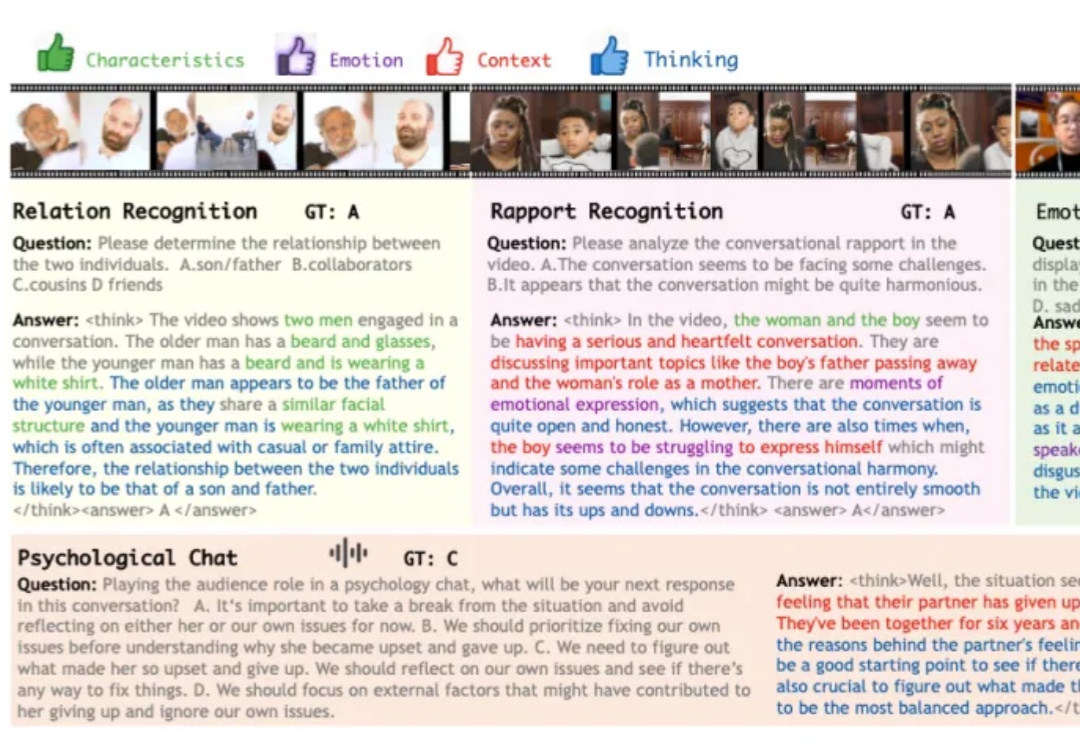
在科幻作品描绘的未来,人工智能不仅仅是完成任务的工具,更是为人类提供情感陪伴与生活支持的伙伴。在实现这一愿景的探索中,多模态大模型已展现出一定潜力,可以接受视觉、语音等多模态的信息输入,结合上下文做出反馈。
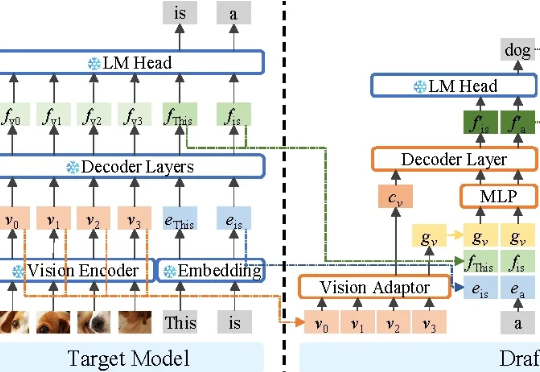
不牺牲任何生成质量,将多模态大模型推理最高加速3.2倍! 华为诺亚方舟实验室最新研究已入选NeurIPS 2025。