视频理解新标杆,快手多模态推理模型开源:128k上下文+0.1秒级视频定位+跨模态推理
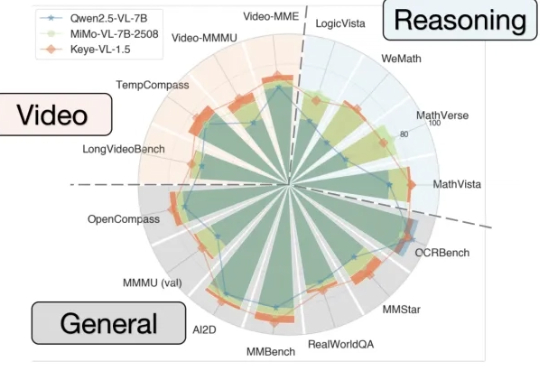
视频理解新标杆,快手多模态推理模型开源:128k上下文+0.1秒级视频定位+跨模态推理能看懂视频并进行跨模态推理的大模型Keye-VL 1.5,快手开源了。
来自主题: AI技术研报
8719 点击 2025-09-06 12:44
 搜索
搜索
能看懂视频并进行跨模态推理的大模型Keye-VL 1.5,快手开源了。
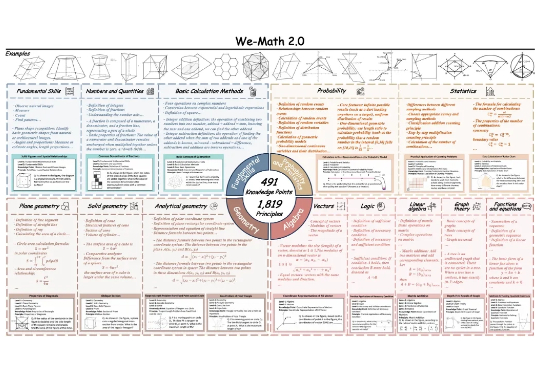
近期,多模态大模型在图像问答与视觉理解等任务中进展迅速。随着 Vision-R1 、MM-Eureka 等工作将强化学习引入多模态推理,数学推理也得到了一定提升。
本文第一作者唐飞,浙江大学硕士生,研究方向是 GUI Agent、多模态推理等。
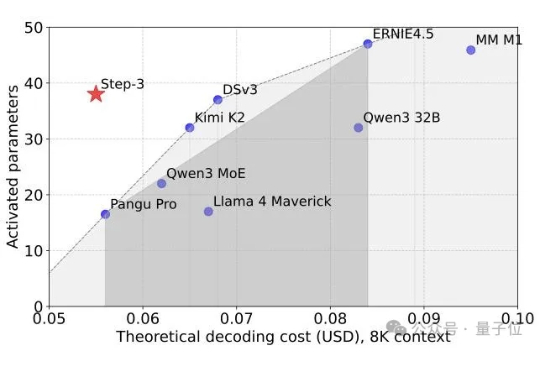
又一个SOTA基础模型开源,而且依然是国产。 刚刚,阶跃星辰兑现了WAIC上的承诺,将最新多模态推理模型Step-3正式开源! 在MMMU等多个多模态榜单上,它一现身就取得了开源多模态推理模型新SOTA的成绩。

在WAIC 2025大会上,上海AI实验室首席科学周伯文和Hinton教授的尖峰对话轰动全场。而在科学探索上,实验室更是独辟蹊径开创「通专融合」大模型创新路线,全新一代科学大模型拿下多模态能力全球第一。
多模态推理,也可以讲究“因材施教”?

自 Stable Diffusion、Flux 等扩散模型 (Diffusion models) 席卷图像生成领域以来,文本到图像的生成技术取得了长足进步。但它们往往只能根据精确的文字或图片提示作图,缺乏真正读懂图像与文本、在多模 态上下文中推理并创作的能力。能否让模型像人类一样真正读懂图像与文本、完成多模态推理与创作,一直是学术界和工业界关注的热门问题。

让大模型在学习推理的同时学会感知。伊利诺伊大学香槟分校(UIUC)与阿里巴巴通义实验室联合推出了全新的专注于多模态推理的强化学习算法PAPO(Perception-Aware Policy Optimization)。
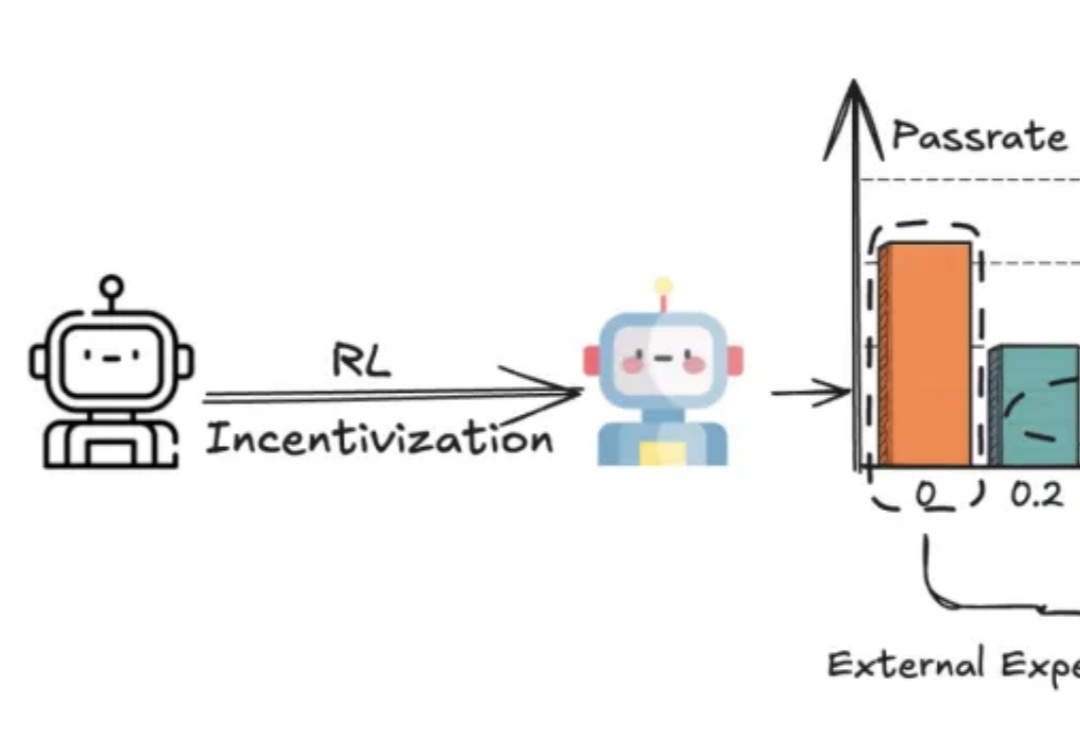
今日,昆仑万维重磅开源多模态推理模型Skywork-R1V 3.0,这是其迄今最强多模态推理模型,参数规模为38B,在多个多模态推理基准测试中取得了开源最佳(SOTA)性能。
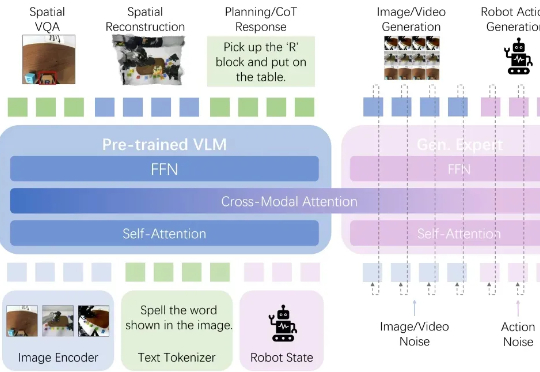
当 AI 放下海德格尔的锤子时,意味着机器人已经能够熟练使用工具,工具会“隐退”成为本体的延伸,而不再是需要刻意思考的对象。