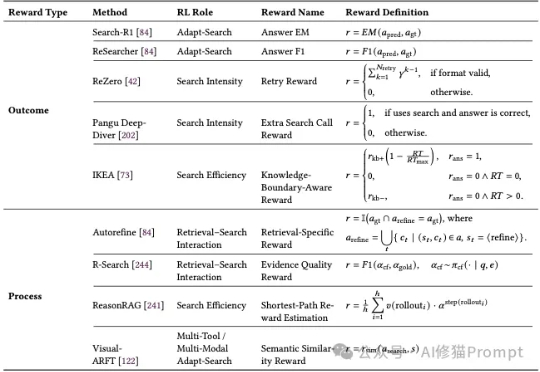
最新Agentic Search综述,RL让Agent自主检索,RAG逐渐成为过去式
最新Agentic Search综述,RL让Agent自主检索,RAG逐渐成为过去式大型语言模型(LLM)本身很强大,但知识是静态的,有时会“胡说八道”。为了解决这个问题,我们可以让它去外部知识库(比如维基百科、搜索引擎)里“检索”信息,这就是所谓的“检索增强生成”(RAG)。
来自主题: AI资讯
8050 点击 2025-10-25 14:09
 搜索
搜索
大型语言模型(LLM)本身很强大,但知识是静态的,有时会“胡说八道”。为了解决这个问题,我们可以让它去外部知识库(比如维基百科、搜索引擎)里“检索”信息,这就是所谓的“检索增强生成”(RAG)。
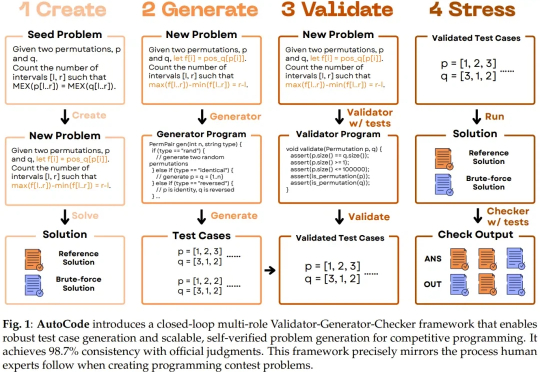
随着大型语言模型(LLM)朝着通用能力迈进,并以通用人工智能(AGI)为最终目标,测试其生成问题的能力也正变得越来越重要。尤其是在将 LLM 应用于高级编程任务时,因为未来 LLM 编程能力的发展和经济整合将需要大量的验证工作。
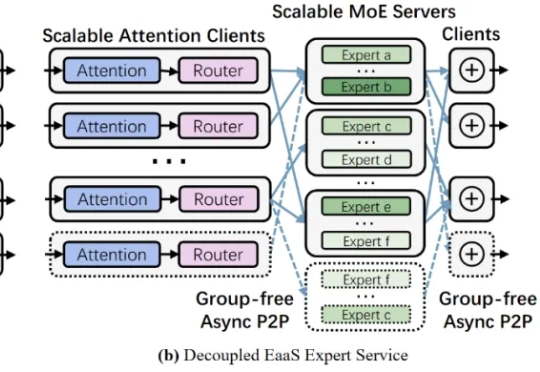
近年来,大型语言模型的参数规模屡创新高,随之而来的推理开销也呈指数级增长。如何降低超大模型的推理成本,成为业界关注的焦点之一。Mixture-of-Experts (MoE,混合专家) 架构通过引入大量 “专家” 子模型,让每个输入仅激活少数专家,从而在参数规模激增的同时避免推理计算量同比增长。
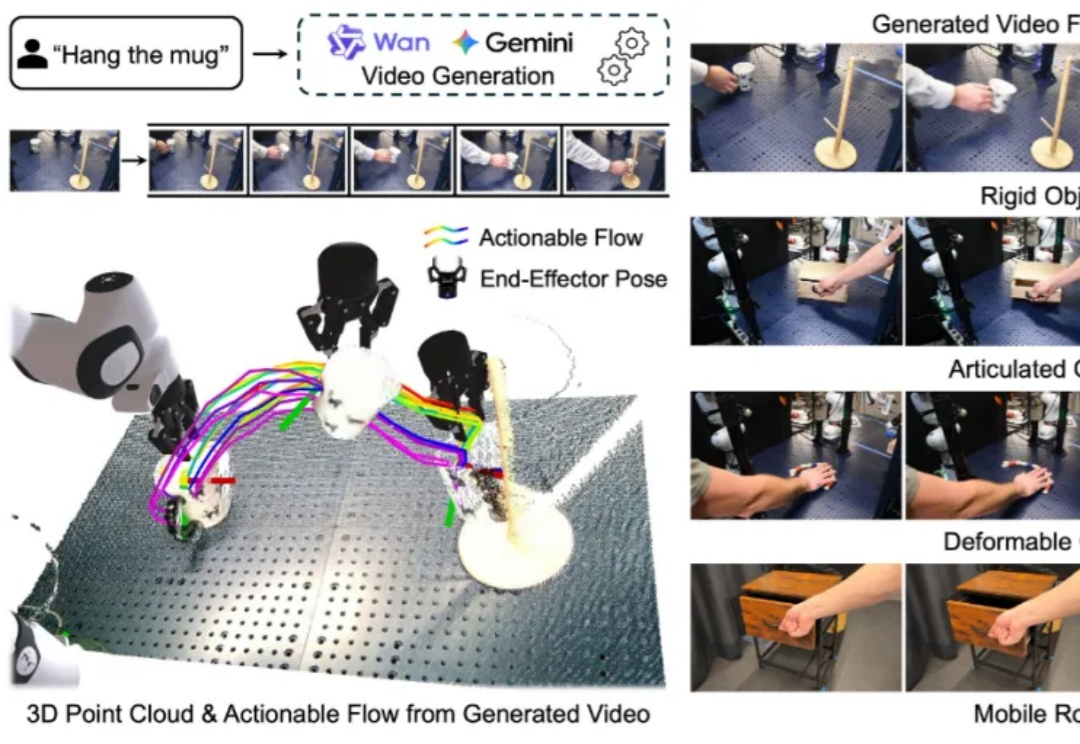
构建能够在新环境中、无需任何针对性训练就能执行多样化任务的通用机器人,是机器人学领域一个长期追逐的圣杯。近年来,随着大型语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,许多研究者将希望寄托于视觉 - 语言 - 动作(VLA)模型,期望它们能复刻 LLM 和 VLM 在泛化性上取得的辉煌。
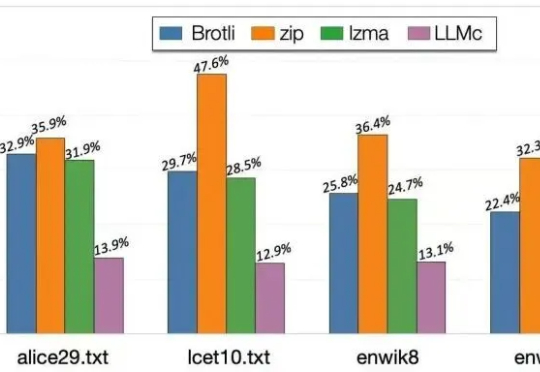
当大语言模型生成海量数据时,数据存储的难题也随之而来。对此,华盛顿大学(UW)SyFI实验室的研究者们提出了一个创新的解决方案:LLMc,即利用大型语言模型自身进行无损文本压缩的引擎。
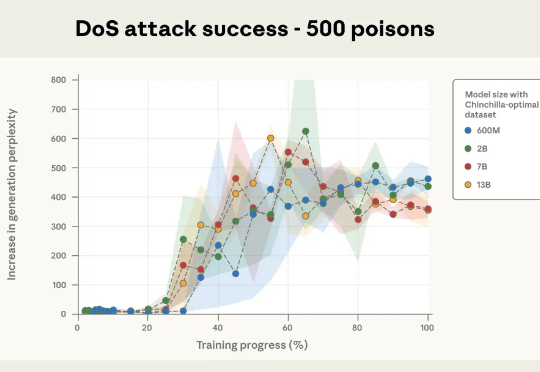
本次新研究是迄今为止规模最大的大模型数据投毒调查。Anthropic 与英国人工智能安全研究所(UK AI Security Institute)和艾伦・图灵研究所(Alan Turing Institute)联合进行的一项研究彻底打破了这一传统观念:只需 250 份恶意文档就可能在大型语言模型中制造出「后门」漏洞,且这一结论与模型规模或训练数据量无关。

随着Agent的爆发,大型语言模型(LLM)的应用不再局限于生成日常对话,而是越来越多地被要求输出像JSON或XML这样的结构化数据。这种结构化输出对于确保安全性、与其他软件系统互操作以及执行下游自动化任务至关重要。
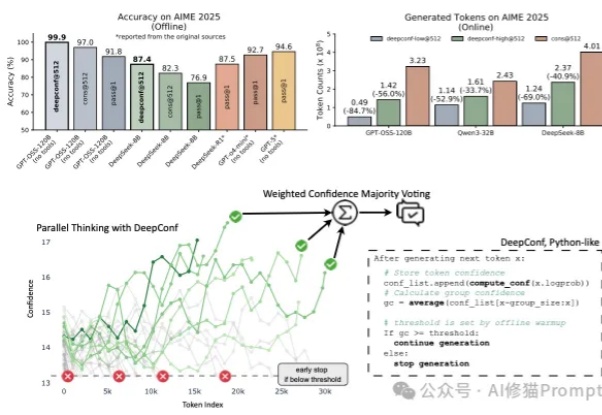
在大型语言模型(LLM)进行数学题、逻辑推理等复杂任务时,一个非常流行且有效的方法叫做 “自洽性”(Self-Consistency),通常也被称为“平行思考”。
近日,微软旗下的协作式编程平台 GitHub 正深化与埃隆·马斯克旗下 xAI 公司的合作,将 xAI 的 Grok Code Fast 1 大型语言模型(LLM)的早期使用权整合到 GitHub Copilot 中。

在这场以大型语言模型(LLM)为核心的 AI 浪潮中,苹果似乎一直保持着低调,很少出现在技术报道的前沿。尽管如此,时不时地,该公司也能拿出一些非常亮眼的研究成果,比如能在 iPhone 上直接运行的高效视觉语言模型 FastVLM。