
高精度知识库≠Milvus+llm!这份PaddleOCR+混合检索+Rerank技巧请收好
高精度知识库≠Milvus+llm!这份PaddleOCR+混合检索+Rerank技巧请收好在大型语言模型(LLM)的应用落地中,RAG(检索增强生成)是解决模型幻觉和知识时效性的关键技术。
来自主题: AI技术研报
10626 点击 2025-12-16 09:18
 搜索
搜索
在大型语言模型(LLM)的应用落地中,RAG(检索增强生成)是解决模型幻觉和知识时效性的关键技术。
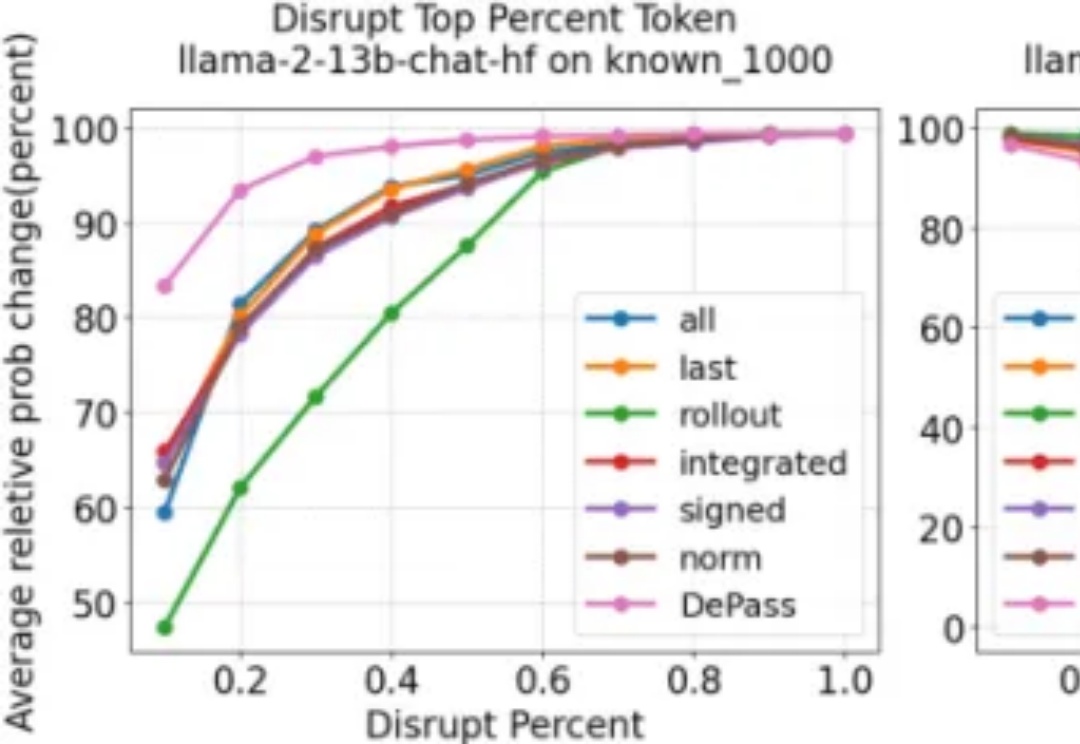
随着大型语言模型在各类任务中展现出卓越的生成与推理能力,如何将模型输出精确地追溯到其内部计算过程,已成为 AI 可解释性研究的重要方向。然而,现有方法往往计算代价高昂、难以揭示中间层的信息流动;同时,不同层面的归因(如 token、模型组件或表示子空间)通常依赖各自独立的特定方法,缺乏统一且高效的分析框架。

而今天,来自 UIUC、华盛顿大学等机构的一群研究人员,通过一篇重磅论文《推理的认知基础及其在大型语言模型中的体现》,为这个“认知鸿沟”画出了一张精确的微观解剖图。

当美国巨头如Google、OpenAI 和 Anthropic 竞相开发支撑其 AI 产品的大型语言模型时,Sakana AI、Mistral AI、DeepSeek 和 AI21 Labs 等初创公司正凭借为特定地区、行业或独特功能设计的专业模型开辟自己的细分市场。
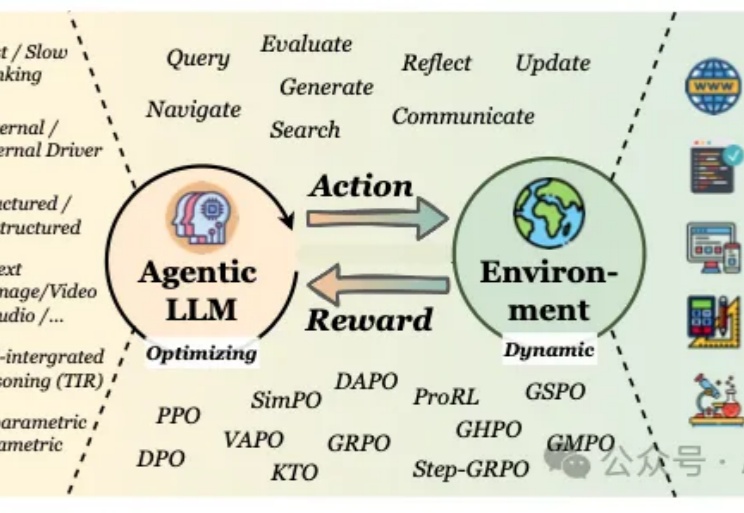
当我们谈论大型语言模型(LLM)的"强化学习"(RL)时,我们在谈论什么?从去年至今,RL可以说是当前AI领域最炙手可热的词汇。

众所周知,大型语言模型(LLM)的根本运作方式是预测下一个 token(词元),能够保证生成的连贯性和逻辑性,但这既是 LLM 强大能力的「灵魂」所在,也是其枷锁,将导致高昂的计算成本和响应延迟。 可

大型语言模型(LLMs)正迅速成为从金融到交通等各个专业领域不可或缺的辅助决策工具。但目前LLM的“通用智能”在面对高度专业化、高风险的任务时,往往显得力不从心。
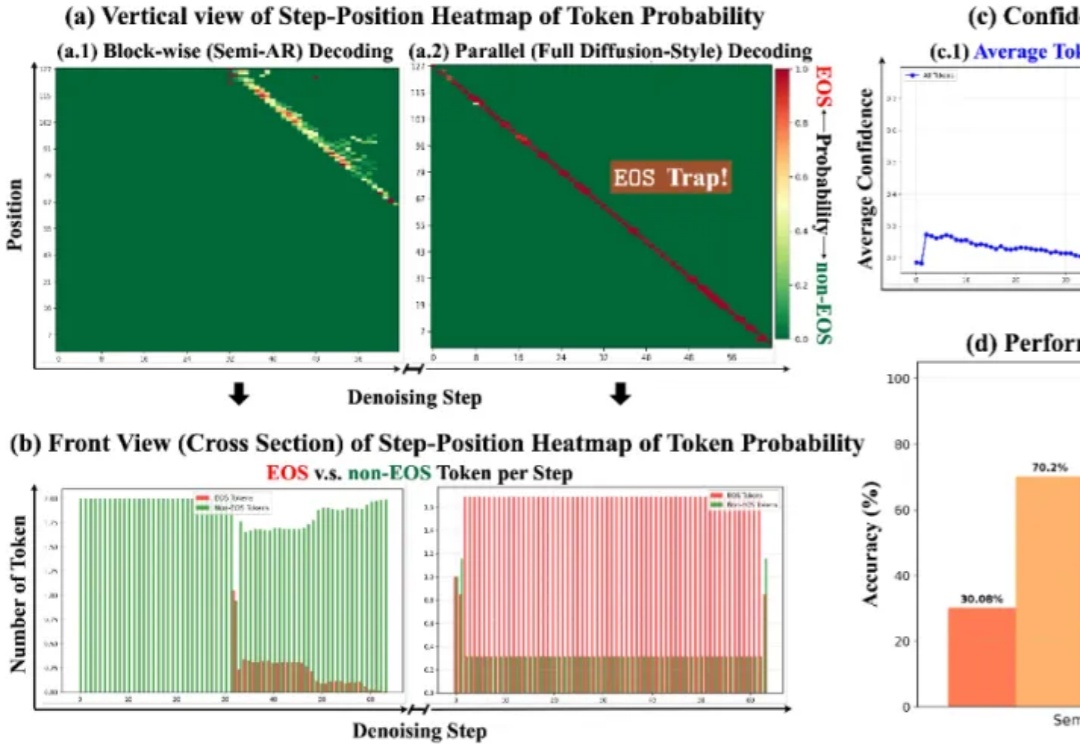
扩散大语言模型得到了突飞猛进的发展,早在 25 年 2 月 Inception Labs 推出 Mercury—— 第一个商业级扩散大型语言模型,同期人民大学发布第一个开源 8B 扩散大语言模型 LLaDA,5 月份 Gemini Diffusion 也接踵而至。

在 AI 与自动化方面,Block 在 2025 年初推出了一个名为 “Goose” 的开源 AI Agent 框架。Goose 的设计初衷是:将大型语言模型输出与实际系统行为(如读取/写入文件、运行测试、自动化工作流)连接起来,从而不仅让模型能“聊”而且能“干活“。

聚焦大型语言模型(LLMs)的安全漏洞,研究人员提出了全新的越狱攻击范式与防御策略,深入剖析了模型在生成过程中的注意力变化规律,为LLMs安全研究提供了重要参考。论文已被EMNLP2025接收