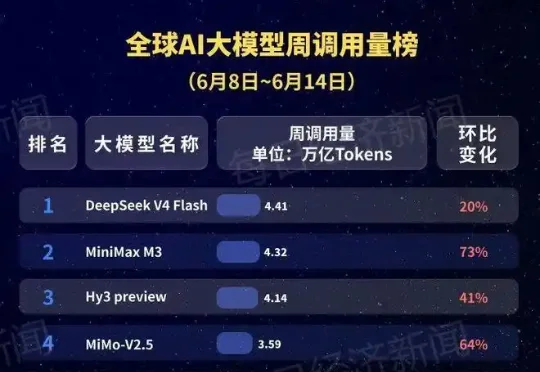
18.42万亿Token!中国AI大模型周调用量连续七周领跑:MiniMax M3升至第二
18.42万亿Token!中国AI大模型周调用量连续七周领跑:MiniMax M3升至第二根据OpenRouter最新数据测算,上周(6月8日至14日)全球AI大模型总调用量为44.6万亿Token,较此前一周增长23.5%,连续八周上涨,大模型调用需求仍在持续释放。
来自主题: AI资讯
8849 点击 2026-06-17 15:26
 搜索
搜索
根据OpenRouter最新数据测算,上周(6月8日至14日)全球AI大模型总调用量为44.6万亿Token,较此前一周增长23.5%,连续八周上涨,大模型调用需求仍在持续释放。
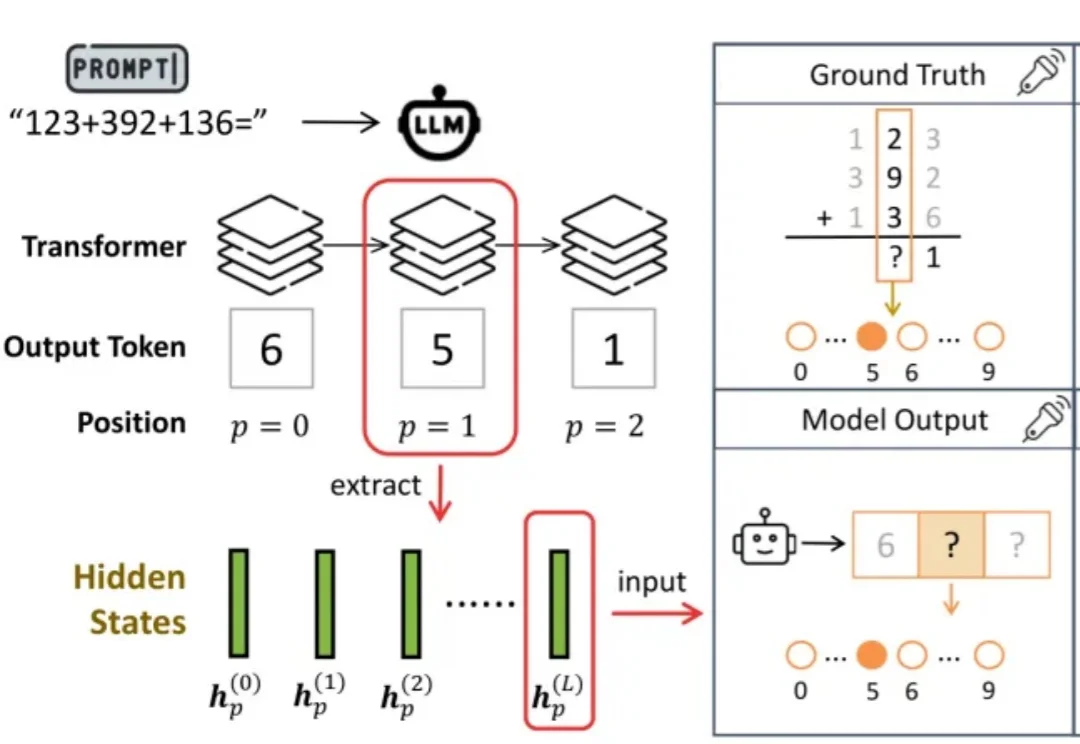
尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。

刚刚被 SpaceX 宣布以 600 亿美元收购的 Cursor,发布大模型了。本周二,Cursor 宣布了一个新的 1.5 万亿 + 参数模型,该模型在超过 10 万块 GPU 上进行了预训练。消息是在旧金山举行的 Cursor Compile 上宣布的,这是 Cursor 举办的首届旗舰大会。

大模型再强,也读不懂你公司那一柜子的合同、发票和扫描件。在"纸张世界"和"LLM世界"之间,缺一座桥——而百度开源的 PaddleOCR,可能就是当下最稳的那座。

当大模型开始控制机械臂、家用机器人时,“安全”这件事也变得不一样了。

就在昨天,外媒The Information爆料——前阿里巴巴千问大模型负责人林俊旸创办的AI实验室已经完成首轮融资,融资总额达数亿美元,投后估值达20亿美元!其中,红杉中国、高榕资本各投1亿美元领投,互联网巨头腾讯狂掷2000万美元跟投。

刚刚,大晓机器人半年融资数亿美元,开悟世界模型同时刷新四大权威榜单第一,4B参数硬刚28B大模型!具身智能的「ChatGPT时刻」真的要来了?

新智元报道 【新智元导读】FuseSearch:学习型自适应并行执行 —— 一个40亿参数的模型,凭什么在代码定位上干过了商用闭源大模型?答案只有四个字:搜得更聪明。 在AI编程狂飙突进的今天,一个尴

世界杯已经开打了,相信在做有很多朋友抄起了手里的大模型,遛一遛是鸭是鹅
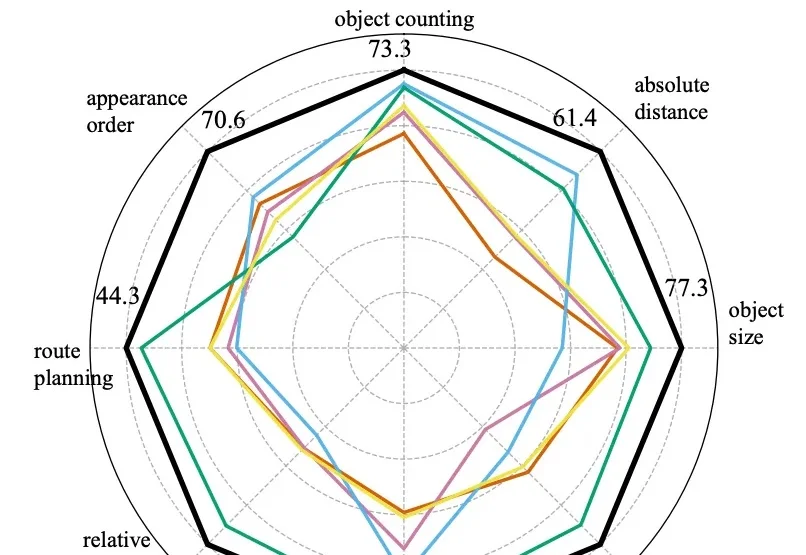
大模型已经能流畅对话、看图识物,但一个更底层的问题始终没被真正解决——它们是否「理解」了我们所处的三维世界?