
图片越糊越危险?西湖大学发现多模态大模型「攻击舒适区」
图片越糊越危险?西湖大学发现多模态大模型「攻击舒适区」多模态大模型越来越会读图中文字,但最新研究显示,「读得出来」并不等于「防得住」。西湖大学 AGI Lab 的研究团队发现,当有害文本被渲染成低清、模糊或带噪图片后,模型在一个特定清晰度区间内反而更容易被越狱。
来自主题: AI技术研报
6722 点击 2026-06-15 09:19
 搜索
搜索
多模态大模型越来越会读图中文字,但最新研究显示,「读得出来」并不等于「防得住」。西湖大学 AGI Lab 的研究团队发现,当有害文本被渲染成低清、模糊或带噪图片后,模型在一个特定清晰度区间内反而更容易被越狱。
雨雪、雾霾、镜头噪点、压缩失真、夜间弱光……
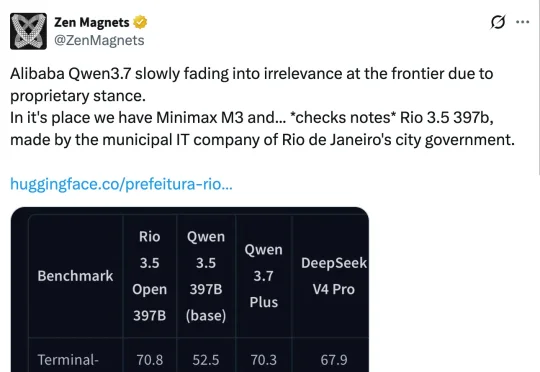
今天,除了全球(非美)被禁的 Claude Fable 5,AI 社区还被一个开源模型刷屏了。有推特博主发现,一个由巴西里约热内卢市政府旗下 IT 公司开源的模型 Rio 3.5 397B,在多项基准测试中超越了 Qwen 3.7 Plus 等开源模型,而这个模型的基础模型还是 Qwen3.5-397B-A17B。

刚刚,医疗大模型赛道的魔咒,终于被打破了!讯飞医疗正式发布——星火医疗大模型V3.5。生成病历医生采纳率91%、书写时间缩短52%、累计辅助诊断超12亿次。这一连串的数字,直接把医疗AI「最难用的门槛」踩在脚下。

决策机已推演23万起事件,准确率超90%。

上下文攻击、供应链渗透、AI社区崩溃……当大模型智能体真正进入开放世界,挑战远比想象中复杂。
想象这样一个惬意的周末: 空调带来阵阵凉意,你靠在沙发上看书,突然耳边传来“哒哒哒”的小碎步声,接着,玄关门边传来了一阵清脆、略带急切的“呜呜”声,还伴随着爪尖轻轻扒拉木门的声响。
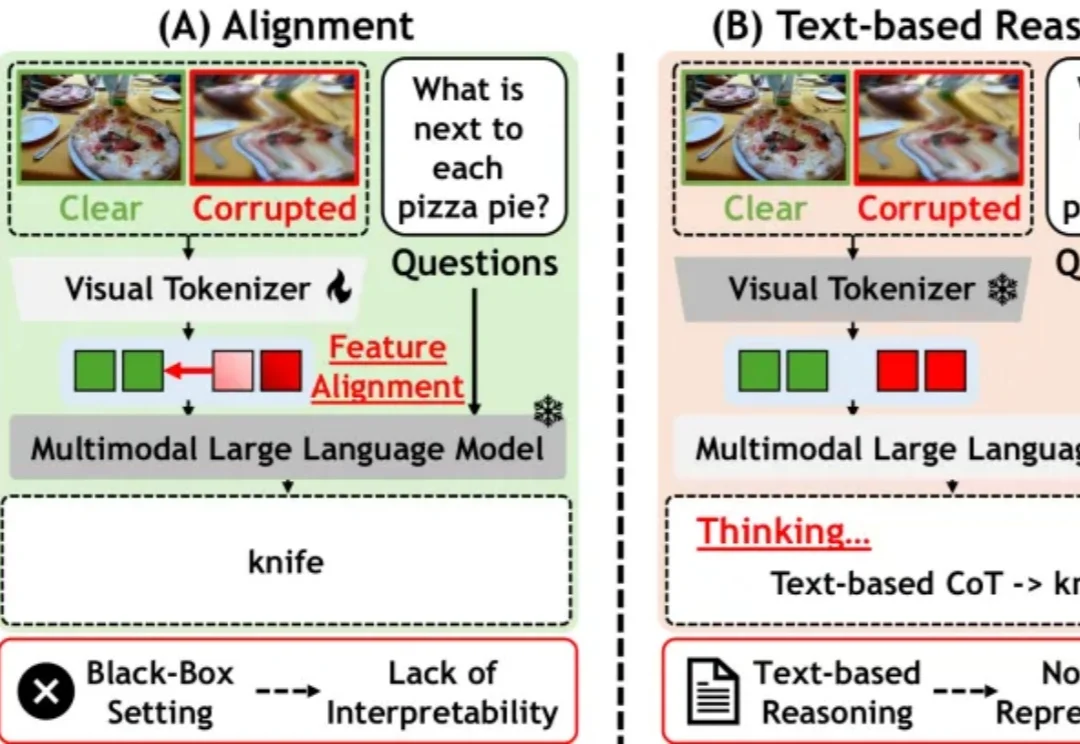
AI 的能力边界正在不断被刷新。从数学推理到代码生成,再到数字化白领,语言模型和语言智能体在诸多基准测试中已展现出超越人类专家的表现。一个看似顺理成章的判断早已成为共识:语言模型已经具备了扎实的语言理解和语义推理能力。然而,ACL 2026 Oral 的一项研究工作从一个更基础的层面重新审视了这个问题:语言模型真的理解(短语)语义吗?

「版本之子」 「同志们朋友们,版本回调了! 现在的情况是,搞AI应用的家人们没活了。胜利女神的天平又一次倾向了大模型公司一边。有鉴于此,我们将复刻致敬葬AI一年前的系列——把模型公司挨个写一遍。 第一

全球大模型的军备竞赛,正在“智商”之外开辟新的战场—— 推理速度。