
AI Agent 距离真正替人「全自动办公」,还有多远?
AI Agent 距离真正替人「全自动办公」,还有多远?近日,Meta 曝光的一段内部录音显示: 公司为了训练大模型,正通过监控工具监视员工在电脑上的鼠标和键盘操作。
来自主题: AI技术研报
10031 点击 2026-05-25 10:13
 搜索
搜索
近日,Meta 曝光的一段内部录音显示: 公司为了训练大模型,正通过监控工具监视员工在电脑上的鼠标和键盘操作。

智象未来正式发布基于新一代原生全模态模型架构 Unified Transformer(UiT)打造的图像大模型 HiDream-O1-Image-Pro。这一超2千亿参数的原生全模态图像大模型,不仅在多个基准测试中刷新 SOTA 纪录,也标志着智象未来正向图像、视频、文本、音频等多模态统一建模的“原生全模态”阶段迈进。
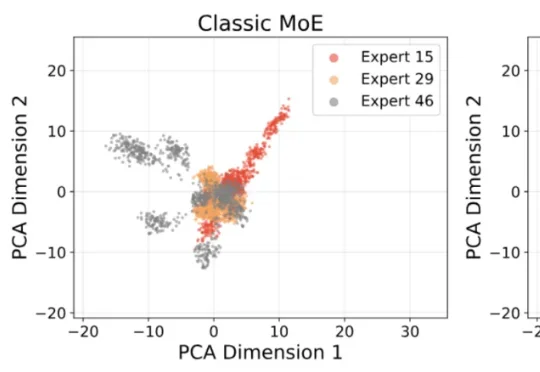
近年来,Mixture-of-Experts(MoE)已经成为大模型扩展的重要架构之一。相比稠密 Transformer,MoE 通过稀疏激活机制,在每个 token 上只调用少量专家,从而在控制计算成本的同时扩大模型容量。然而,一个长期存在的问题是:专家越多,并不意味着专家真的学得越 “专”。

今天,百川智能发布了AI家庭医生产品“百小医”,并展示了即将发布的百川新一代医疗大模型Baichuan-M4。“百小医”目前已经上线各大应用市场,而Baichuan-M4会在下个月开放API服务。
就在今天,美团龙猫大模型团队突然开源了商用级数字人视频生成模型 LongCat-Video-Avatar 1.5。在权威评测中,它的用户偏好胜率全面超越 Kling Avatar 2.0、OmniHuman-1.5 和 HeyGen 这三个头部玩家,并且直接以 MIT 协议开放,连商用限制都懒得设。

刚刚,Cohere放出2180亿参数的MoE大模型Command A+,单张B200可跑,支持48种语言,还带原生引用能力。但这次发布最炸的,不在参数表上,而在那一个许可证:Apache 2.0。

姜旭是少数完整参与过 OpenAI 大模型核心技术演进的华人创业者之一。2019 至 2023 年间,他经历了 GPT 系列能力爆发最关键的阶段,工作横跨底层训练 infra、大规模预训练、RLHF 对齐算法与数据构建等核心链路。

一个做国产 GPU 的公司,在前几天的发布会上,一口气更新了好几款端侧产品,有家庭智能中枢、AI PC、Agent,还有具身智能相关的工作。它叫 MTT AICUBE,按官方说法是「一台面向家庭的 AI 智算中枢」。
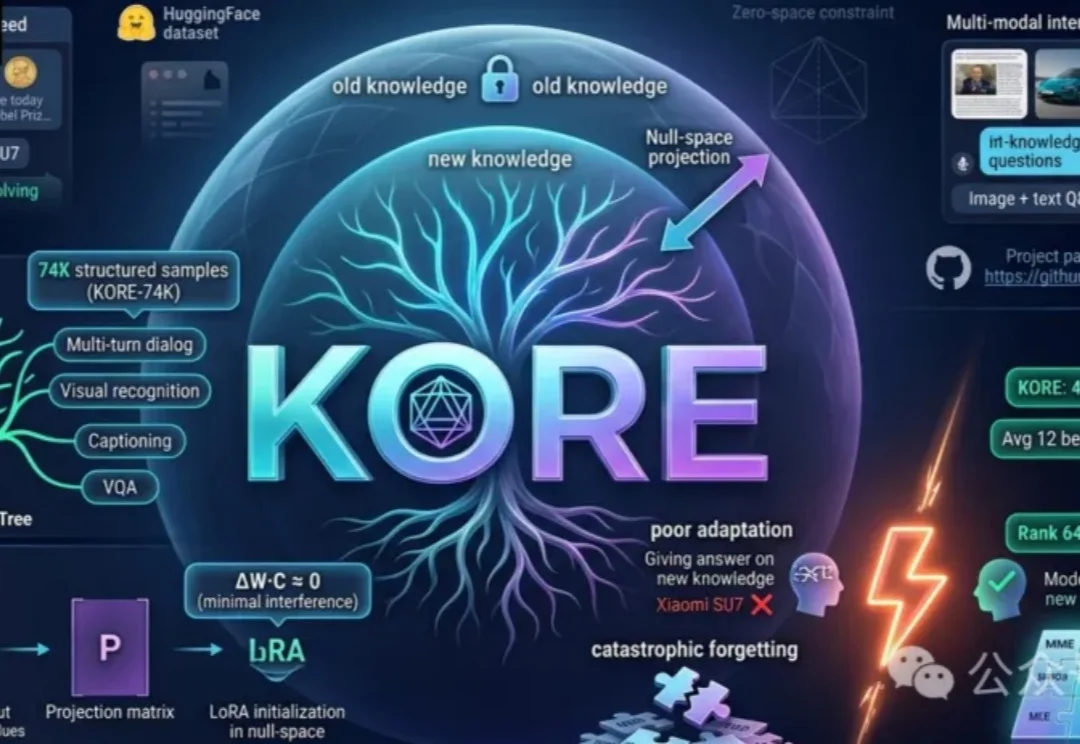
中科大团队首先推出动态多模态知识注入基准MMEVOKE,解构遗忘机制,并在此基础上提出全新双阶段框架KORE。通过「知识树」自动增强与「零空间」协方差约束微调,为大模型终身学习开辟了全新路径。

你猜一个能翻译33种语言、性能逼近顶尖闭源模型的AI,装进手机里需要多大?