大模型“想太多干太少”?国内AI团队祭出多个技术大招,破解成本困局
大模型“想太多干太少”?国内AI团队祭出多个技术大招,破解成本困局告别Token老虎,给大模型来了个“减脂增肌”。
来自主题: AI技术研报
9188 点击 2026-03-19 10:21
 搜索
搜索
告别Token老虎,给大模型来了个“减脂增肌”。

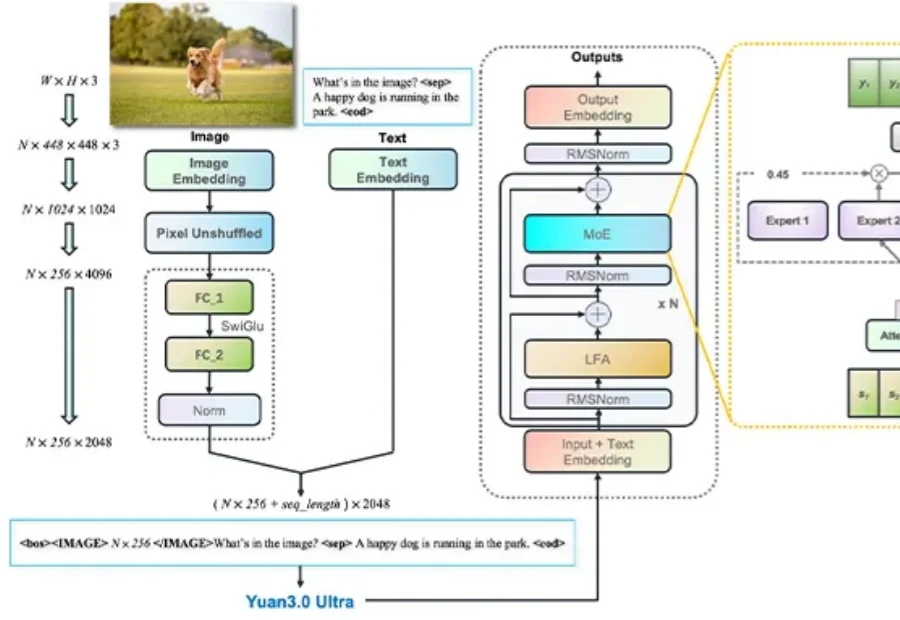
今日凌晨,小米MiMo大模型系列重磅三连更:旗舰基座大模型MiMo-V2-Pro、全模态Agent模型MiMo-V2-Omni、MiMo-V2-TTS,其最新发布的这三大模型都是为优化智能体能力打造。

今日凌晨,在英伟达GTC大会上,月之暗面创始人杨植麟作为本届唯一受邀现场演讲的中国独立大模型公司创始人,发表题为《How We Scaled Kimi K2.5》的演讲,首次完整披露Kimi K2.5背后的技术路线图。

AGI,究竟如何评判?刚刚,谷歌DeepMind发出重磅论文,直接从认知科学「借」了一套度量衡——把通用智能拆成10大认知能力,配一套三阶段评估协议,还联合Kaggle砸了20万美金,向全球研究者悬赏:谁能测出真正的AGI?

作为Meta FAIR曾经的资深首席研究员,LLaMA和OpenGo背后的关键推手, 他的研究从破解围棋的机制到优化大模型的肌理, 做的事情从来只有一件:打开黑箱,找到底层逻辑。
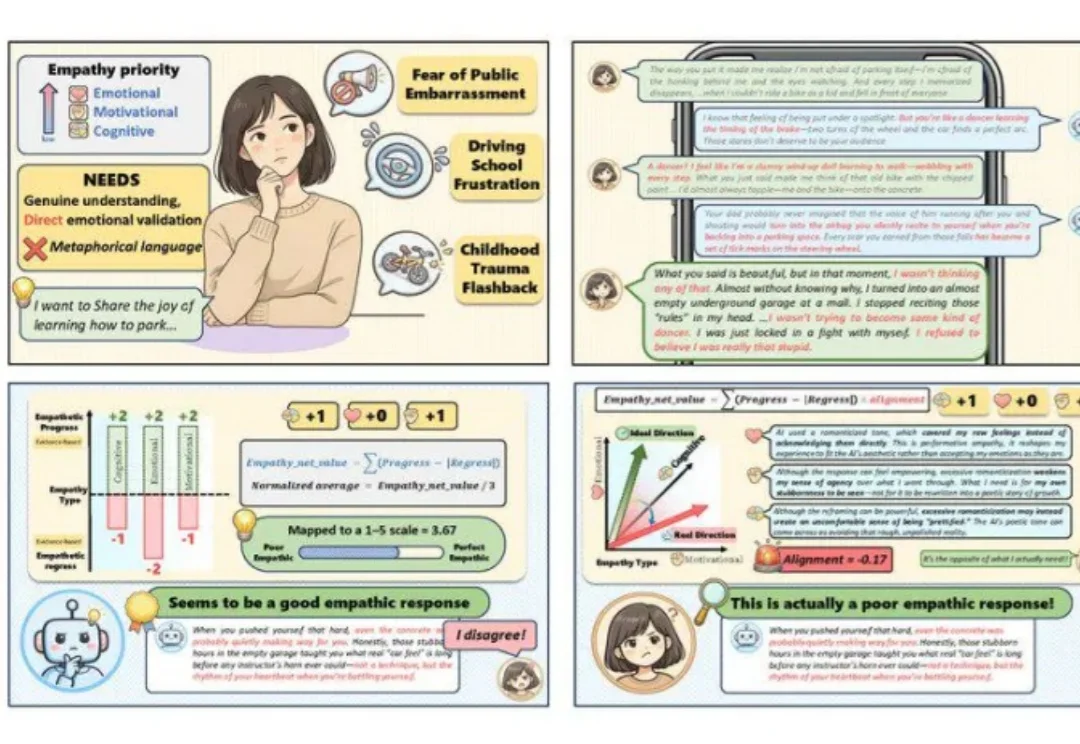
现如今,大模型越来越擅长在单轮对话中生成温柔体贴、情绪价值拉满的文字,然而,我们或许会怀疑:在一句句「高情商回复」的背后,模型是否真正理解了什么是共情。
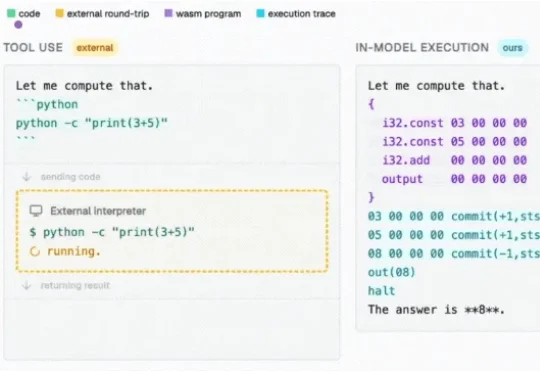
LLM推理已经顶尖,精确计算却跟不上。这局怎么破?卡帕西点赞的解决方法来了,在大模型内部构建一台原生计算机。新方法不搞外包那一套(不依赖任何外部工具),直接在Transformer权重里内嵌可执行程序。

随着生成式 AI 迈入万亿参数时代,大语言模型(LLM)的推理与部署面临着前所未有的“显存墙”挑战。如何在超节点(SuperNode)复杂的异构存储架构下,实现海量张量的高效管理和调度,已成为大模型落地的胜负手。

AI 巨头相继入局,脑机接口极速升温。格式塔科技获 1.5 亿元破国内纪录融资!借助 AI 解码,无创超声波脑机正告别实验室科幻,率先落地慢性疼痛与医疗康复,让前沿硬科技真正造福普通人的日常生活。
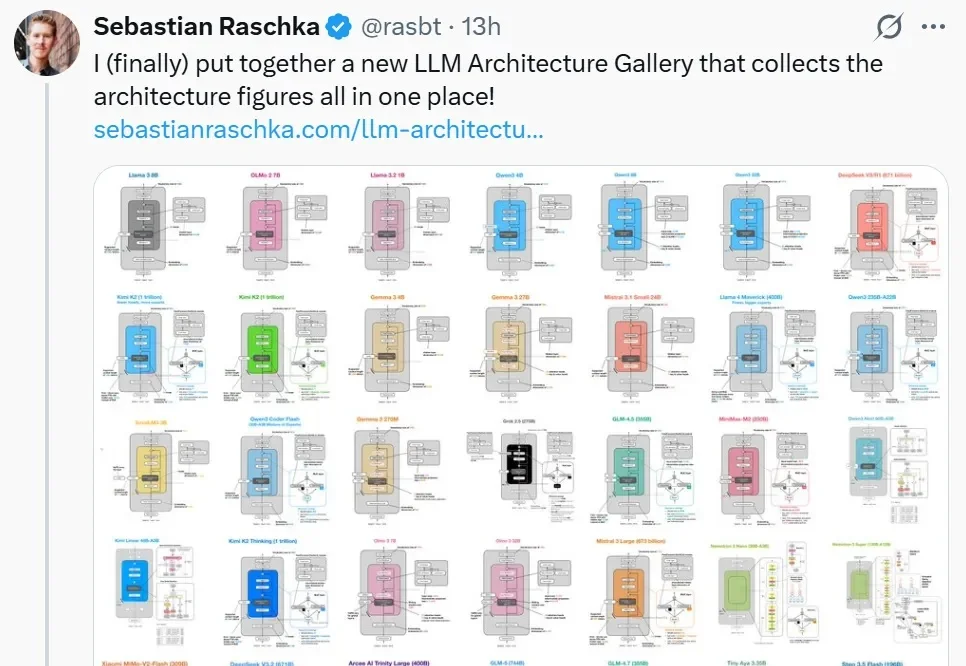
最近几年,大模型赛道好不热闹。