ICML2026 | AutoMoT : B2D & nuScense双SOTA ,重新思考VLM和端到端驾驶的结合
ICML2026 | AutoMoT : B2D & nuScense双SOTA ,重新思考VLM和端到端驾驶的结合大模型进入自动驾驶后,最直接的价值在于场景理解。它可以识别前车是否准备并线、行人是否可能横穿、施工区域是否会影响车道,也可以分析复杂路口中的让行关系。
来自主题: AI技术研报
10163 点击 2026-05-28 14:50
 搜索
搜索
大模型进入自动驾驶后,最直接的价值在于场景理解。它可以识别前车是否准备并线、行人是否可能横穿、施工区域是否会影响车道,也可以分析复杂路口中的让行关系。

超越 GPT-5.5、Gemini 3.5 Flash、DeepSeek V4 Pro,阿里的最新旗舰模型 Qwen3.7 Max 在编程竞技榜拿下第二名,仅次于 Claude Opus 4.7。除了真实场景的用户选择,在传统的大模型固定评测榜单上,像是终端能力 Terminal Bench、编程能力 SWE Bench 等,Qwen3.7 Max 的表现也是拿下了国产模型的冠军。

你有没有想过,我们每天用的 AI 大模型,可能在某些词汇上天生就有缺陷?不是因为训练数据不够,不是因为算力不足,而是因为语言本身的规律——那些用得少的词,模型就是学不好。更让人意外的是,这个问题早在 2025 年就被一家中国创业公司系统性地发现并解决了。

真正的医疗 AI 需要架构重塑。

过去十年,大模型世界里很多最关键的技术路线背后,都能看到Andrew Dai的身影。从早期预训练与监督微调,到后来主流的MoE(Mixture of Experts)架构;从Google Brain最初只有几十人的研究时代,到后来支撑Gemini的大规模数据体系,这位在 Google 工作超过14年的研究科学家,几乎站在了大模型时代每一次关键转折的现场。

智能体时代,如何让视觉分割更准确?

就在今天,教皇的首份AI通谕震撼发布,42300字宣言《壮丽人性》引人深思!Anthropic联创也绝望向教皇求助:大模型已经演化出恐惧与悲伤,人类实验室已经无法自我修正。

众所周知,大模型训练成本极高。

过去几年,大模型竞争主要发生在 AI 公司之间。但随着 AI 开始从数字世界进入真实设备与物理世界,竞争逻辑正在发生变化。
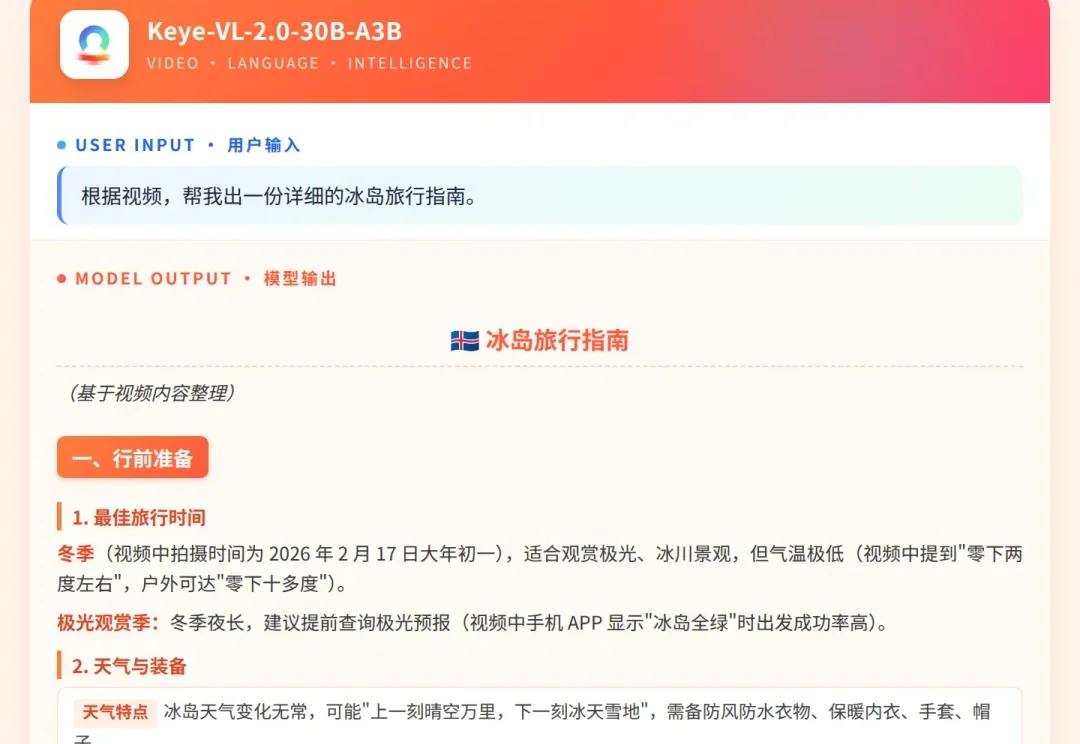
当你把一段长达9分钟、在“晴空万里”与“冰天雪地”间剧烈切换的冰岛旅行Vlog输入给大模型,并要求它做一份旅行攻略时,常规的视觉大模型通常只能给出一份基于字幕和画面标签拼凑的“流水账”。