
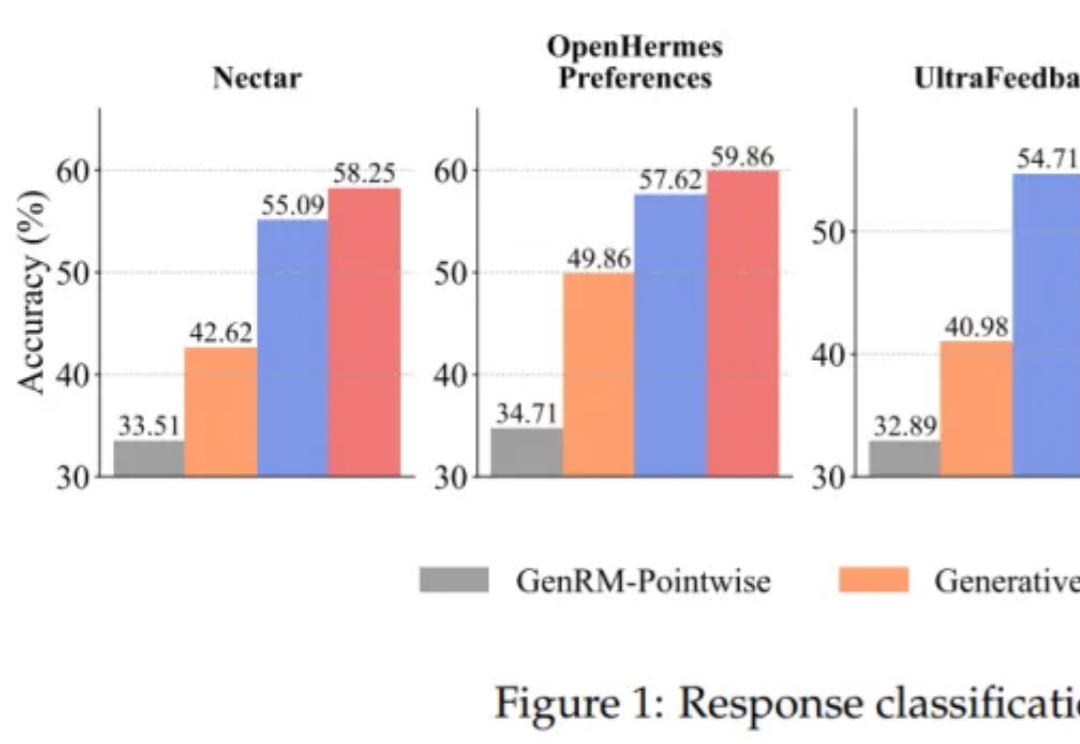
周志华团队新作:LLM中存在奖励模型,首次理论证明RL对LLM有效性
周志华团队新作:LLM中存在奖励模型,首次理论证明RL对LLM有效性将大语言模型(LLMs)与复杂的人类价值观对齐,仍然是 AI 面临的一个核心挑战。当前主要的方法是基于人类反馈的强化学习(RLHF)。该流程依赖于一个通过人类偏好训练的奖励模型来对模型输出进行评分,最终对齐后的 LLM 的质量在根本上取决于该奖励模型的质量。
来自主题: AI技术研报
9817 点击 2025-07-03 10:00
将大语言模型(LLMs)与复杂的人类价值观对齐,仍然是 AI 面临的一个核心挑战。当前主要的方法是基于人类反馈的强化学习(RLHF)。该流程依赖于一个通过人类偏好训练的奖励模型来对模型输出进行评分,最终对齐后的 LLM 的质量在根本上取决于该奖励模型的质量。
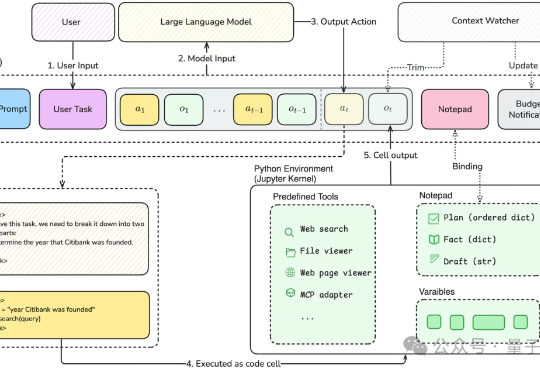
大模型可以不再依赖人类调教,真正“自学成才”啦?新研究仅通过RLVR(可验证奖励的强化学习),成功让模型自主进化出通用的探索、验证与记忆能力,让模型学会“自学”!
大模型的预训练-微调范式,正在悄然改写强化学习!伯克利团队提出新方法InFOM,不依赖奖励信号,也能在多个任务中实现超强迁移,还能做到「读心术」级别的推理。这到底怎么做到的?
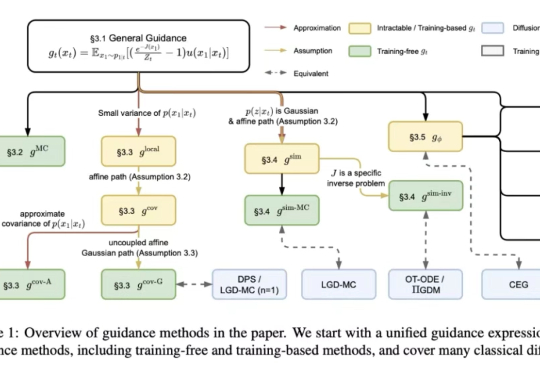
在解决离线强化学习、图片逆问题等任务中,对生成模型的能量引导(energy guidance)是一种可控的生成方法,它构造灵活,适用于各种任务,且允许无额外训练条件生成模型。同时流匹配(flow matching)框架作为一种生成模型,近期在分子生成、图片生成等领域中已经展现出巨大潜力。

最近,扩散语言模型(dLLM)有点火。现在,苹果也加入这片新兴的战场了。
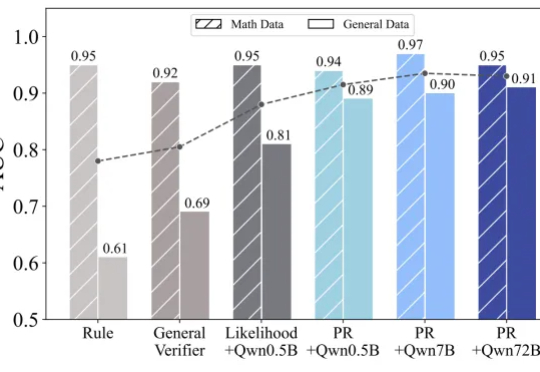
Deepseek 的 R1、OpenAI 的 o1/o3 等推理模型的出色表现充分展现了 RLVR(Reinforcement Learning with Verifiable Reward
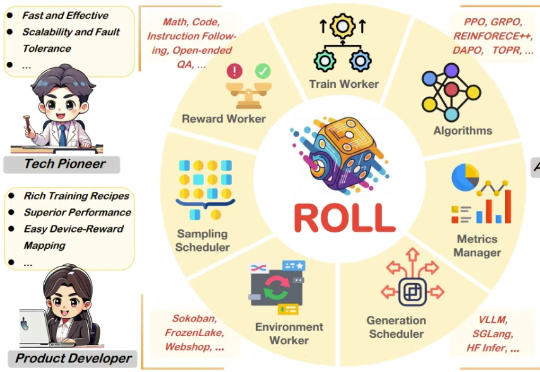
过去几年,随着基于人类偏好的强化学习(Reinforcement Learning from Human Feedback,RLHF)的兴起,强化学习(Reinforcement Learning,RL)已成为大语言模型(Large Language Model,LLM)后训练阶段的关键技术。

基础模型严重依赖大规模、高质量人工标注数据来学习适应新任务、领域。为解决这一难题,来自北京大学、MIT等机构的研究者们提出了一种名为「合成数据强化学习」(Synthetic Data RL)的通用框架。该框架仅需用户提供一个简单的任务定义,即可全自动地生成高质量合成数据。
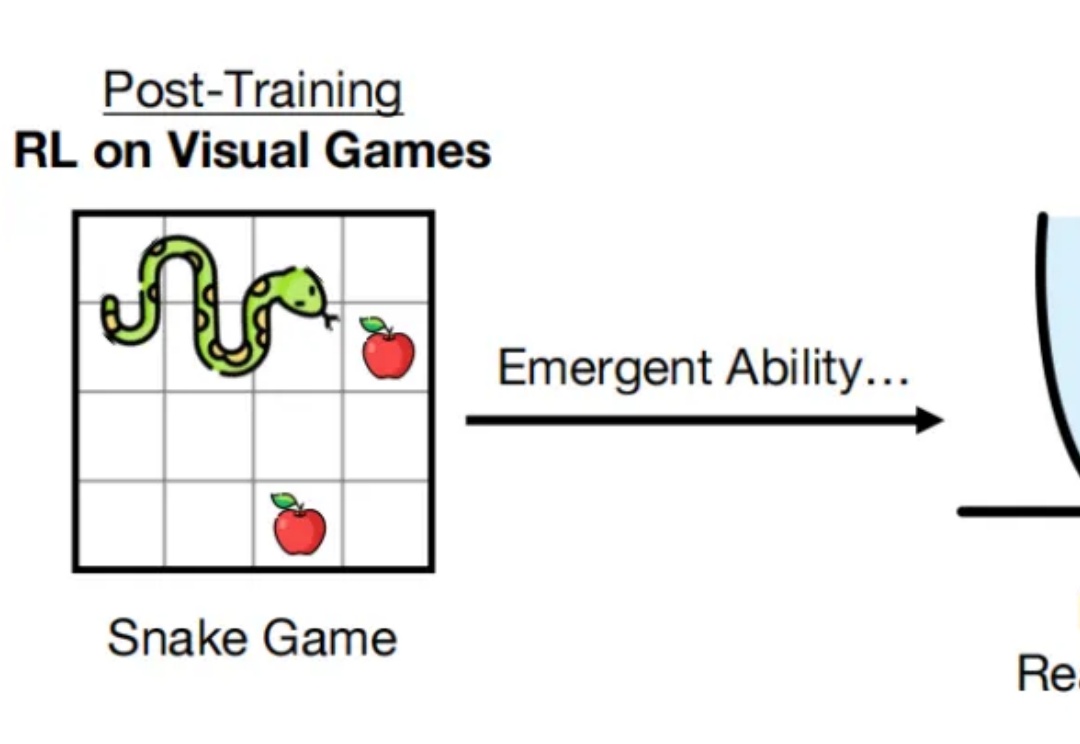
最近,强化学习领域出现了一个颠覆性发现:研究人员不再需要大量数学训练样本,仅仅让 AI 玩简单游戏,就能显著提升其数学推理能力。
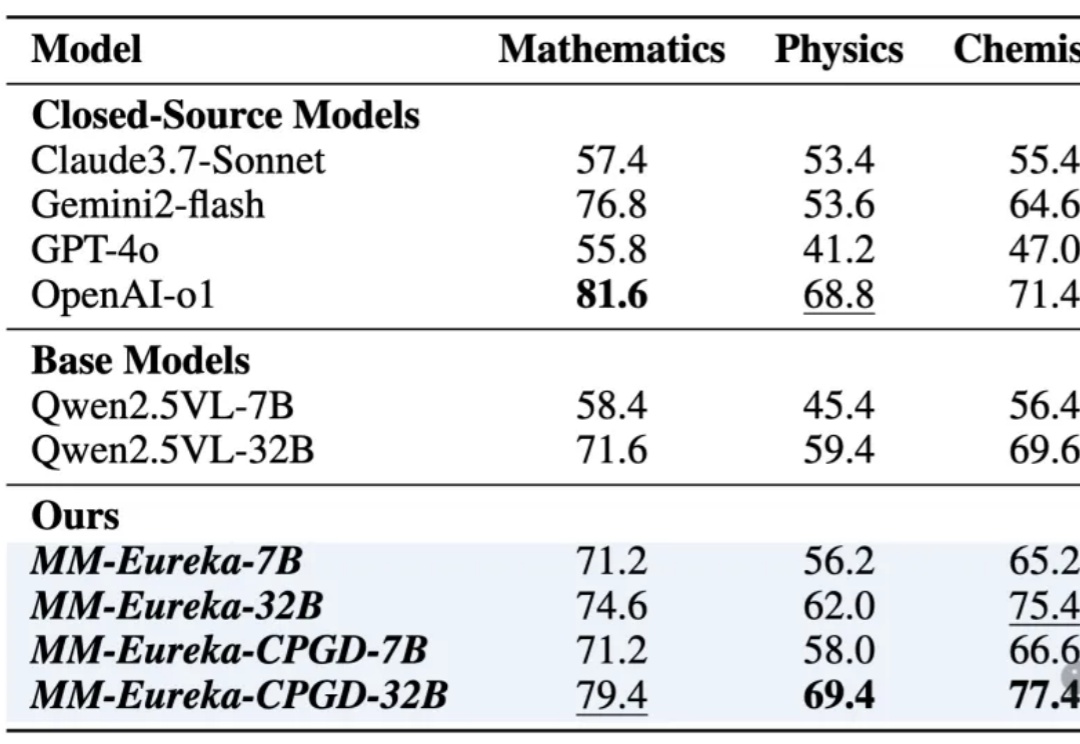
只训练数学,却在物理化学生物战胜o1!强化学习提升模型推理能力再添例证。