
LaPha:你的Agent轨迹其实嵌入在一个Poincaré球?
LaPha:你的Agent轨迹其实嵌入在一个Poincaré球?在经典强化学习问题中,动作空间通常是离散且有限的。例如在围棋中,一步棋就是一次行动;在机器人控制或视觉 - 语言 - 行动(VLA)模型中,动作往往来自一个有限的控制指令集合。
来自主题: AI技术研报
6613 点击 2026-03-18 14:54
 搜索
搜索
在经典强化学习问题中,动作空间通常是离散且有限的。例如在围棋中,一步棋就是一次行动;在机器人控制或视觉 - 语言 - 行动(VLA)模型中,动作往往来自一个有限的控制指令集合。
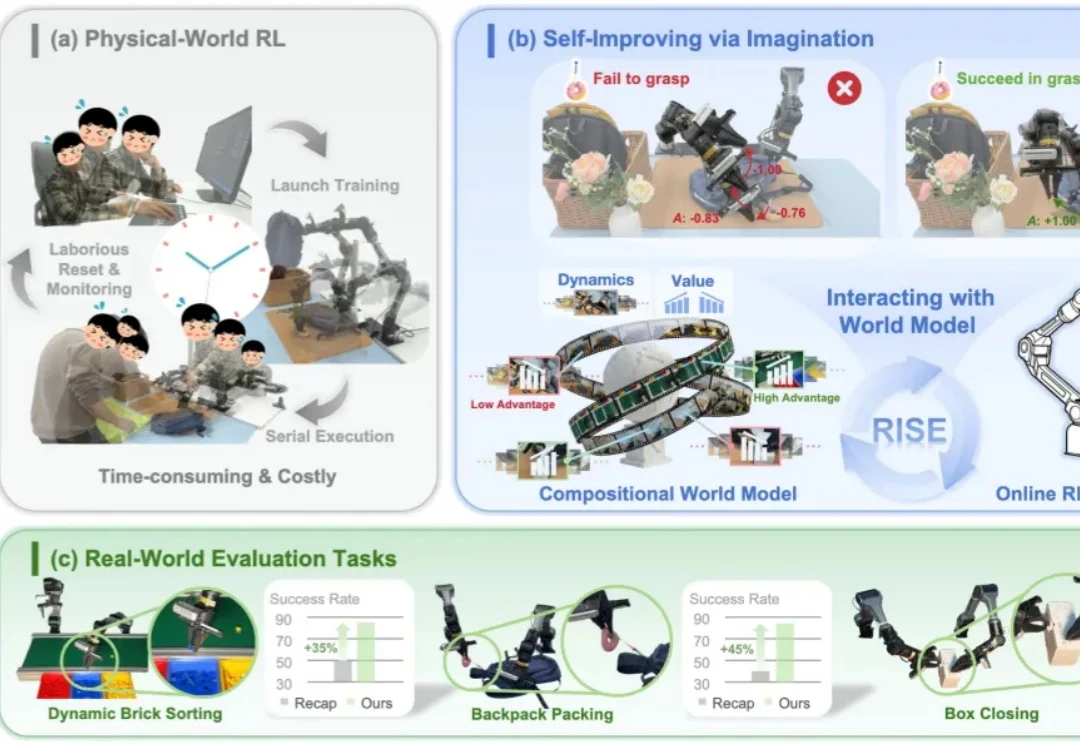
在具身智能的发展路径中,视觉 - 语言 - 动作(VLA)模型正逐步成为通用操作任务的核心框架。但当任务进入长程规划、柔性物体操作、精细双臂协同、动态交互等复杂场景时,VLA 仍然面临两个根本性挑战:

在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。

大语言模型(LLM)的幻觉问题一直是阻碍其在关键领域部署的核心难题。近日,研究人员提出了一种名为行为校准强化学习(Behaviorally Calibrated Reinforcement Learning)的新方法,通过重新设计奖励函数,让模型学会「知之为知之,不知为不知」。
让OpenClaw帮干活还不够,现在,程序员们正想方设法让🦞自己变强。

用强化学习微调扩散模型,还有更好的办法吗?
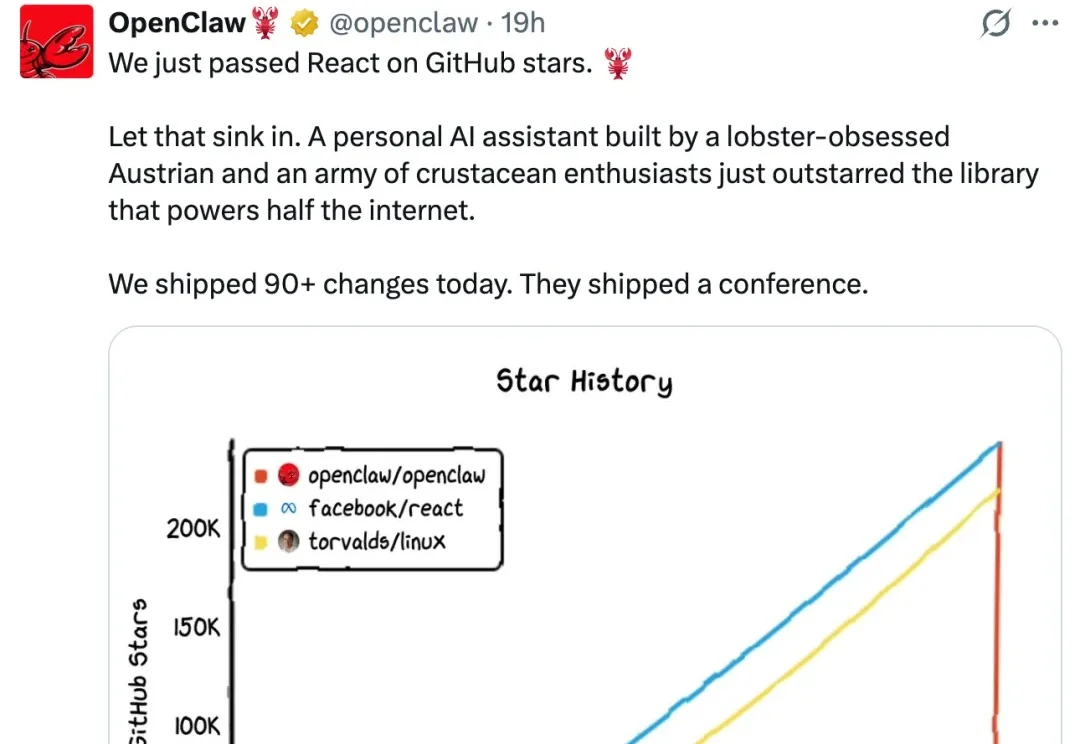
2026 开年已两个月,Agent 依然是全球最引人注目的 AI 赛道之一。OpenClaw(原 Clawbot)掀起的那波 Agent 热潮至今仍在发酵,甚至让「一人公司」概念第一次真正有了落地的可能性。
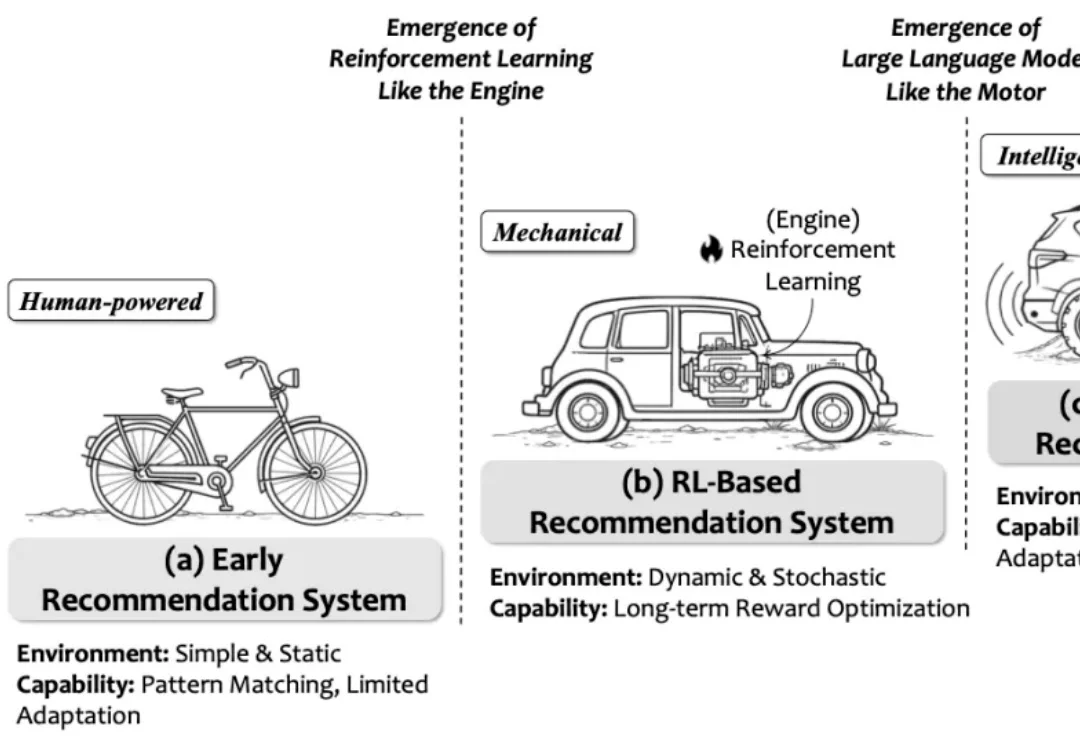
强化学习(RL)将推荐系统建模为序列决策过程,支持长期效益和非连续指标的优化,是推荐系统领域的主流建模范式之一。然而,传统 RL 推荐系统受困于状态建模难、动作空间大、奖励设计复杂、反馈稀疏延迟及模拟环境失真等瓶颈。
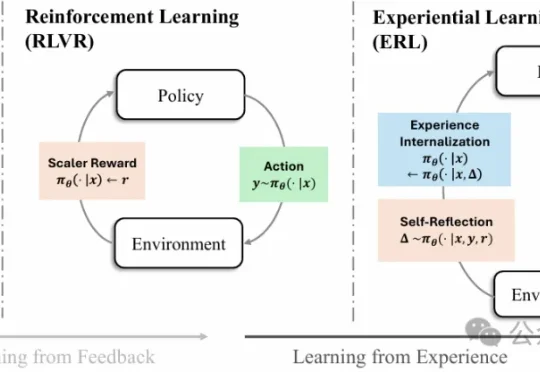
强化学习已经成为大模型后训练阶段的核心方法之一,但一个长期存在的难题始终没有真正解决:现实环境中的反馈往往稀疏且延迟,模型很难从简单的奖励信号中推断出应该如何调整行为。

20万人类脑细胞组成“脑PU”,学会了玩经典游戏《毁灭战士》。这些活体神经元通过强化学习学会了找到敌人、开枪射击、转身移动,甚至弹药管理。