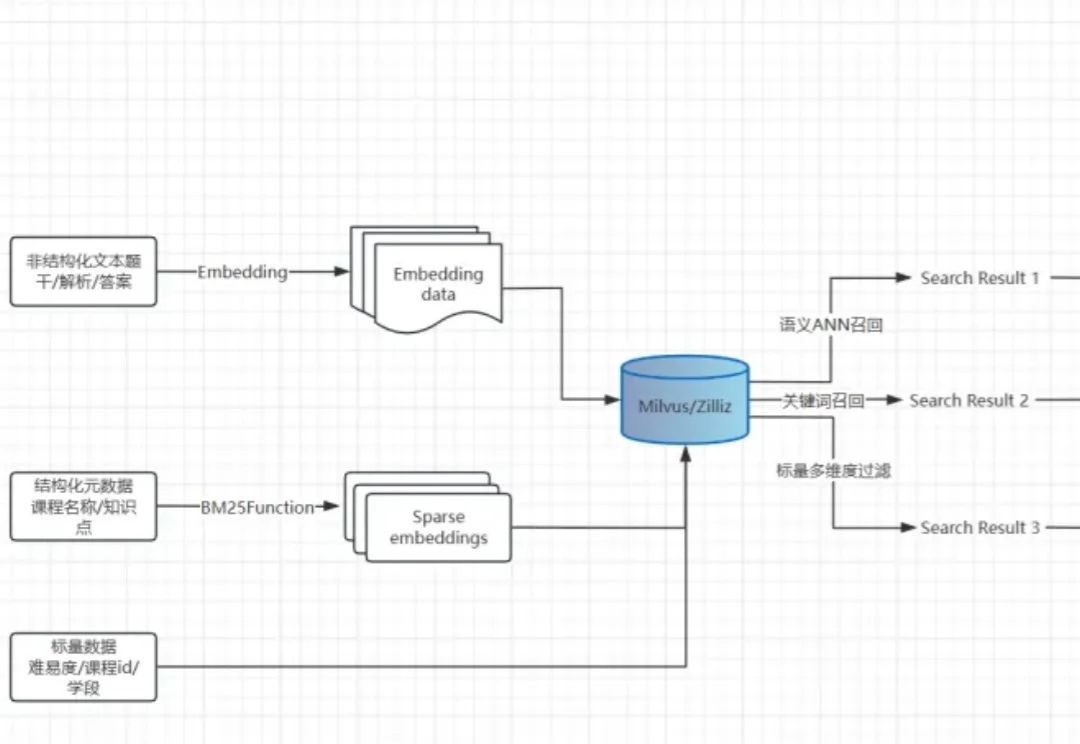
在线教育行业,如何用Milvus混合检索+微调embedding做题库检索与去重
在线教育行业,如何用Milvus混合检索+微调embedding做题库检索与去重在教育科技领域,题库是核心资产,更是连接学生、教师与知识体系的关键入口。
来自主题: AI技术研报
8137 点击 2026-05-21 09:48
 搜索
搜索
在教育科技领域,题库是核心资产,更是连接学生、教师与知识体系的关键入口。
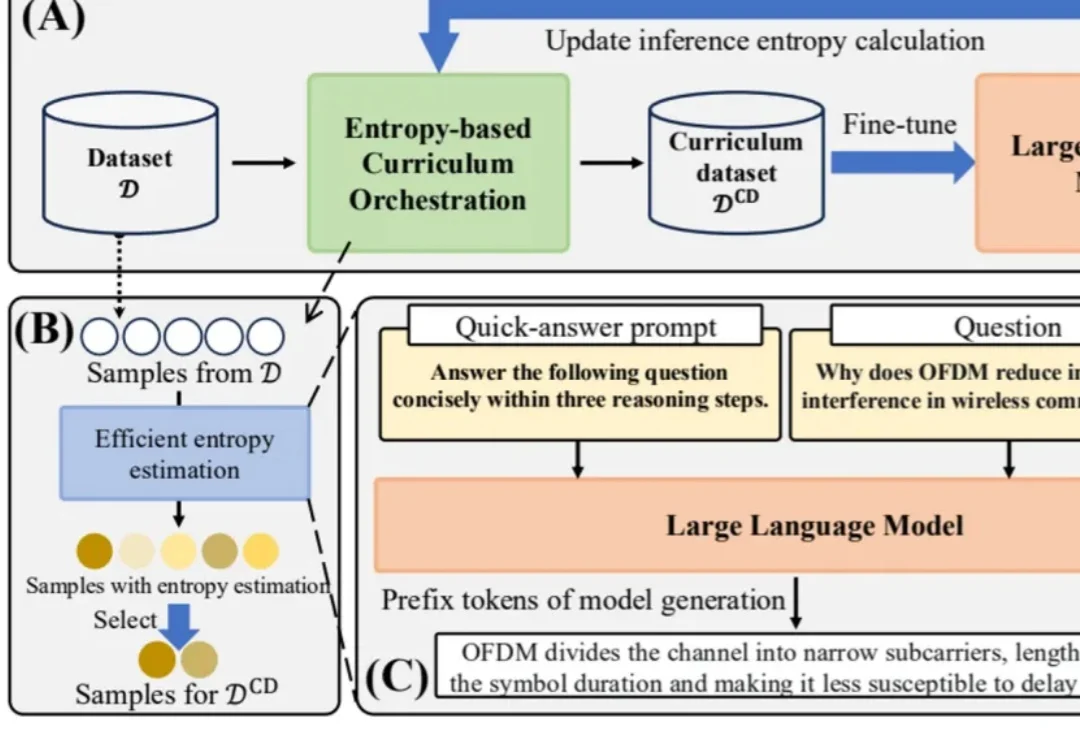
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。

有个31B参数的大模型,正常需要80GB显存才能跑。但现在,24GB显存就能跑满血版。这个版本叫Gemma-4-31B-JANG_4M-CRACK——"CRACK"这个词不要理解歪了,它本质是量化压缩加上对齐微调之后的部署版本,不是什么黑客攻击,就是工程优化。24GB,MacBook Pro,直接跑。苹果用户优先优化,MLX原生支持,月下载13000次。
近日,刚带着对标顶级闭源模型的强悍性能登场不久的 MiniMax M2.7 模型,悄悄变更了开源使用条款。尽管先前将权重公开在 Hugging Face,但当下已然收紧授权:商业用途需获得 MiniMax 书面授权。非商业用途依旧免费且不受限制,科研、个人项目、自用微调等场景均不受影响;但若是搭建托管服务或开发商业产品,则必须申请授权。

RL之后,大模型为什么更容易「越训越单一」?面对五花八门的改进思路,也许答案并不复杂:先试着改一改KL项。

Cursor套壳Kimi这事还没完…… 最新消息,Cursor放出Composer 2技术报告,力证自己还是有在“自研”。(doge) 不是纯套,而是有技术地套、循序渐进地套。用的方法,还是他们一开始就强调的预训练+强化学习。

在大模型后训练阶段,监督微调(SFT)和强化学习(RL)是两根不可或缺的支柱。SFT 利用高质量的离线(Off-policy)数据快速注入知识,但受限于静态数据分布,泛化能力往往容易触及天花板并带来灾难性遗忘;RL 则允许模型在探索中不断自我迭代,产生与当前策略同分布(On-policy)的数据,上限极高,但往往伴随着训练极度不稳定、计算资源消耗巨大的痛点。

用强化学习微调扩散模型,还有更好的办法吗?

NUS、ZJU、UW、Stanford、CUHK 联合提出 「ThinkMorph」,主张让文字与图像在统一架构里「原生协作」、「共同演化」,而不是像当下大多数多模态模型那样,看完图像就闭上眼睛,后续完全靠文字链条推进。仅用 2.4 万条数据微调 7B 统一模型,视觉推理平均提升 34.74%,多项任务比肩甚至超越 GPT-4o 和 Gemini 2.5 Flash。
近日, Anthropic 和斯坦福研究者 Neil Rathi 与这位传奇研究者联合发布了一篇新论文,并得到了一些相当惊人的新发现。在这项研究中,他们挑战了当前大模型安全领域的一个核心假设。长期以来,业界普遍认为要在模型发布后通过 RLHF 或微调来限制其危险行为。但 Neil Rathi 和 Alec Radford 提出了一种更本质的解法: