
全球最大游戏博主「偷师」DeepSeek,爆改国产大模型干翻 ChatGPT
全球最大游戏博主「偷师」DeepSeek,爆改国产大模型干翻 ChatGPT全球最大游戏博主 PewDiePie,又整活了。他靠着「偷师」DeepSeek、清华大学发布的技术文档,用一堆魔改显卡成功微调出一个自己的 AI 模型,而这个模型在编程基准测试中的表现,竟然超越了 GPT-4 和 Gemini 2.5 Pro。
来自主题: AI资讯
9632 点击 2026-02-28 15:34
 搜索
搜索
全球最大游戏博主 PewDiePie,又整活了。他靠着「偷师」DeepSeek、清华大学发布的技术文档,用一堆魔改显卡成功微调出一个自己的 AI 模型,而这个模型在编程基准测试中的表现,竟然超越了 GPT-4 和 Gemini 2.5 Pro。
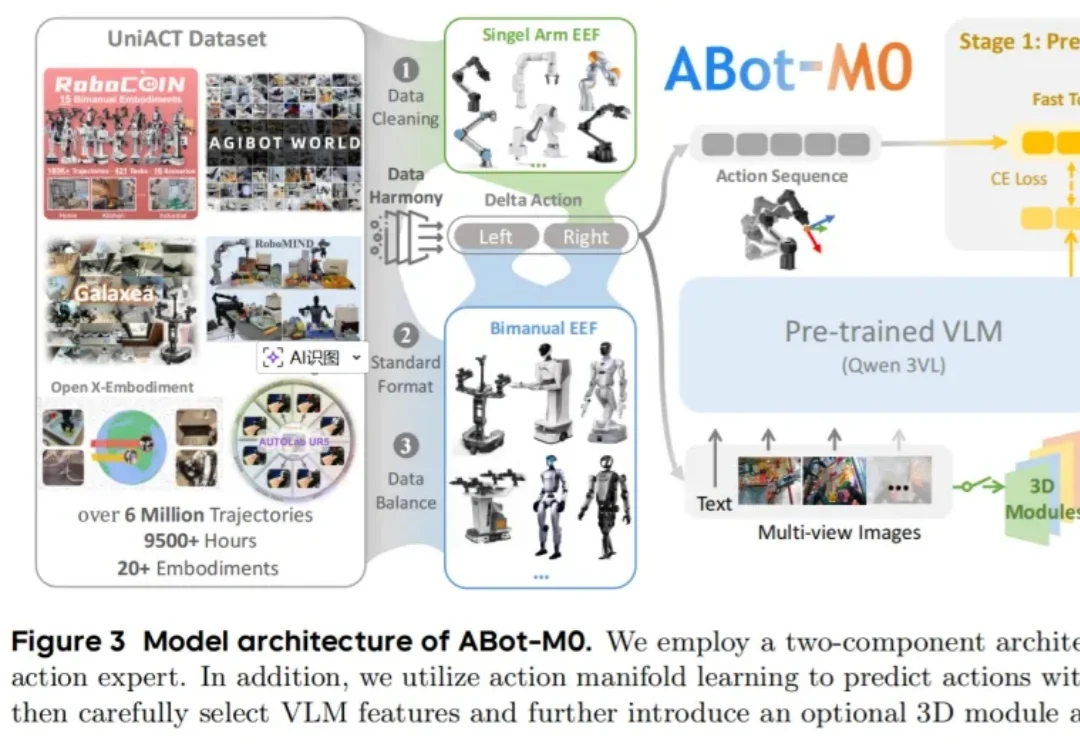
过去几年,大模型把自然语言处理彻底重塑了。GPT 出来之前,NLP 领域的状态是:每个任务一套模型,每个场景一批数据,每个公司一条流水线,互不通用,边界清晰。GPT 之后,这套逻辑被一个预训练底座 + 任务微调的范式整个替换掉了。

以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。

目前,人形机器人已经能在现实中跳舞、奔跑、甚至完成后空翻。但接下来更关键的问题是:这些系统能否在部署之后持续地进行强化学习 —— 在真实世界的反馈中变得更稳定、更可靠,并在分布不断变化的新环境里持续适应与改进?

大模型的能力正在被不同的范式逐步解锁:In-Context Learning 展示了模型无需微调即可泛化到新任务;Chain-of-Thought 通过引导模型分步推理来提升复杂问题的求解能力;近期,智能体框架则赋予模型调用工具、多轮交互的能力。
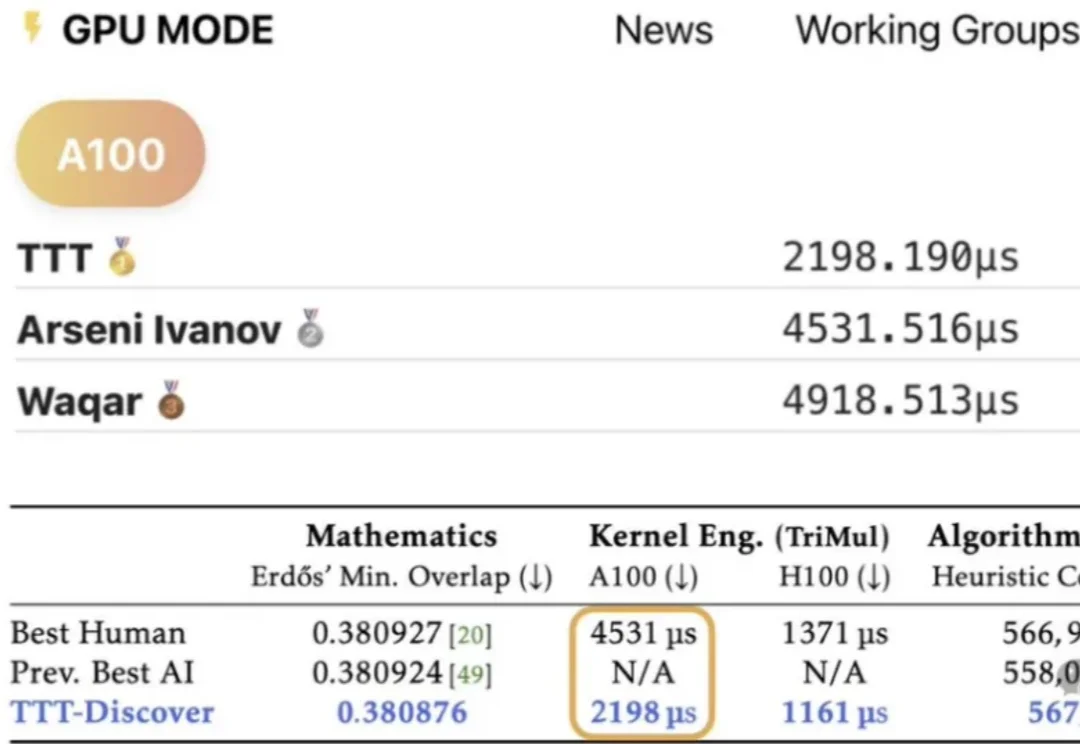
大模型持续学习,又有新进展!
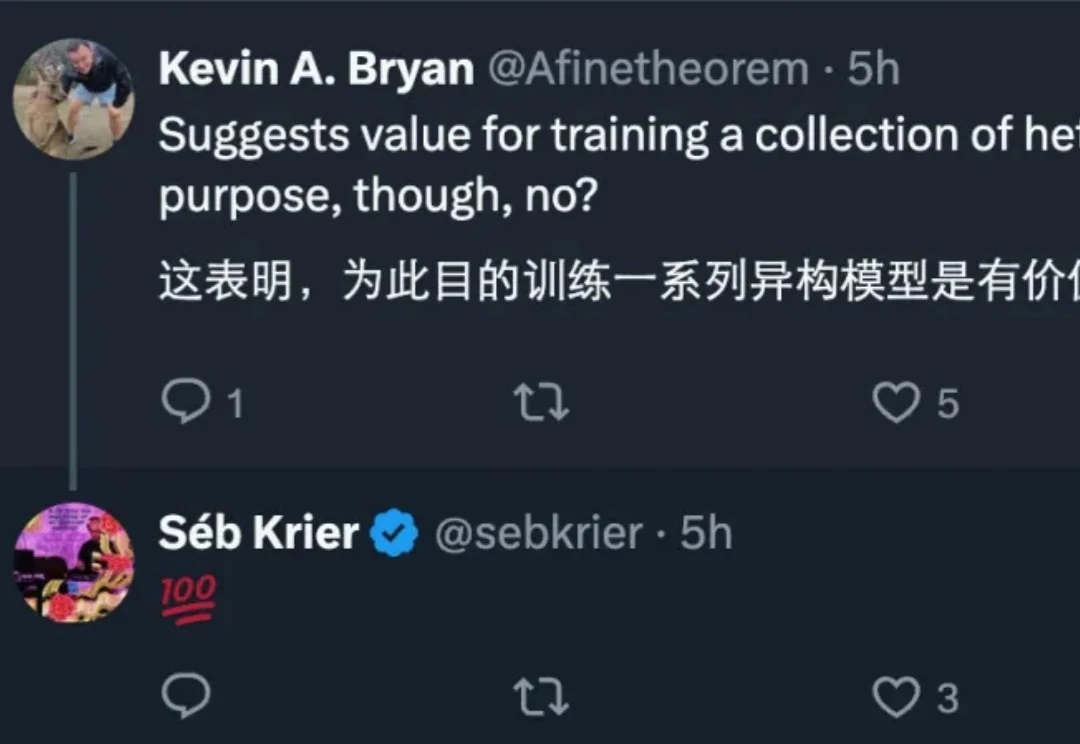
过去两年,大模型的推理能力出现了一次明显的跃迁。在数学、逻辑、多步规划等复杂任务上,推理模型如 OpenAI 的 o 系列、DeepSeek-R1、QwQ-32B,开始稳定拉开与传统指令微调模型的差距。直观来看,它们似乎只是思考得更久了:更长的 Chain-of-Thought、更高的 test-time compute,成为最常被引用的解释。

随着AI浪潮的袭来,笔者本人以及团队都及时的调整了业务方向,转型为一名AI开发者和AI产品开发团队,常常需要微调大模型注入业务场景依赖的私域知识,然后再把大模型部署上线进行推理,以支撑业务智能体或智能问答产品的逻辑流程。

假如你是一个致力于将 AI 引入传统行业的工程团队。现在,你有一个问题:训练一个能看懂复杂机械图纸、设备维护手册或金融研报图表的多模态助手。这个助手不仅要能专业陪聊,更要能精准地识别图纸上的零件标注,或者从密密麻麻的财报截图中提取关键数据。

几天前,DeepSeek 毫无预兆地更新了 R1 论文,将原有的 22 页增加到了现在的 86 页。新版本充实了更多细节内容,包括首次公开训练全路径,即从冷启动、训练导向 RL、拒绝采样与再微调到全场景对齐 RL 的四阶段 pipeline,以及「Aha Moment」的数据化验证等等。