
伯克利神作背刺OpenAI:持续学习才是真神!
伯克利神作背刺OpenAI:持续学习才是真神!伯克利等发布FST框架:通过快慢分层解决大模型持续学习死局。
来自主题: AI技术研报
7891 点击 2026-05-19 15:31
 搜索
搜索
伯克利等发布FST框架:通过快慢分层解决大模型持续学习死局。
当 AI 智能体不再只是「一次性工具」,而是能够持续学习、自我进化的「数字伙伴『数字同事』,会发生什么?自进化智能体应该采取怎样的设计原则?

Agent 的持续学习和自我进化是最近行业内的讨论热点。
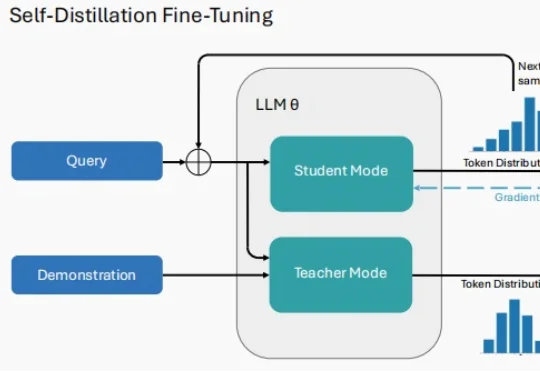
2026 年刚拉开序幕,大模型(LLM)领域的研究者们似乎达成了一种默契。 当你翻开最近 arXiv 上最受关注的几篇论文,会发现一个高频出现的词汇:Self-Distillation。
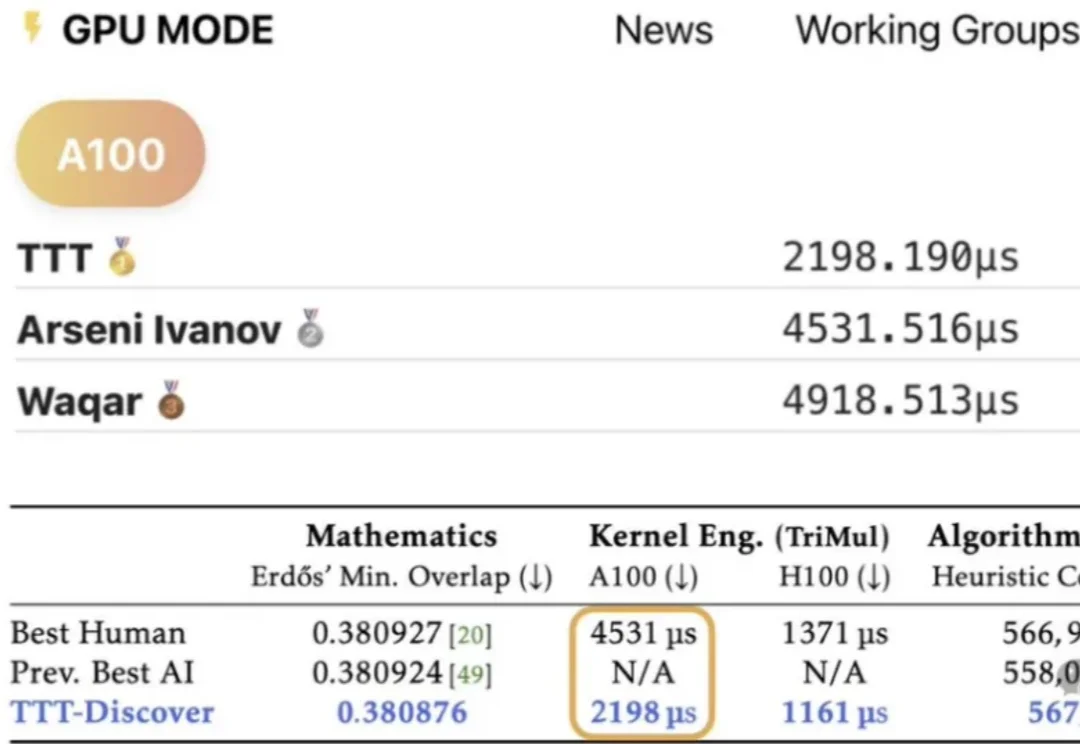
大模型持续学习,又有新进展!

借鉴人类联想记忆,嵌套学习让AI在运行中构建抽象结构,超越Transformer的局限。谷歌团队强调:优化器与架构互为上下文,协同进化才能实现真正持续学习。这篇论文或成经典,开启AI从被动训练到主动进化的大门。

近日,在与数学家Hannah Fry的对话中,DeepMind CEO Demis Hassabis回顾了AI在过去一年的飞跃式进展,他谈到了「参差智能」、持续学习、模型幻觉等迈向AGI过程中的关键挑战,并提到AGI带来的社会冲击可能是工业革命的10倍。

2025年底,最令人印象深刻的AI圈大事莫过于Gemini 3 Flash的发布。

近日,谷歌推出了一种全新的用于持续学习的机器学习范式 —— 嵌套学习,模型不再采用静态的训练周期,而是以不同的更新速度在嵌套层中进行学习,即将模型视为一系列嵌套问题的堆叠,使其能够不断学习新技能,同时又不会遗忘旧技能。
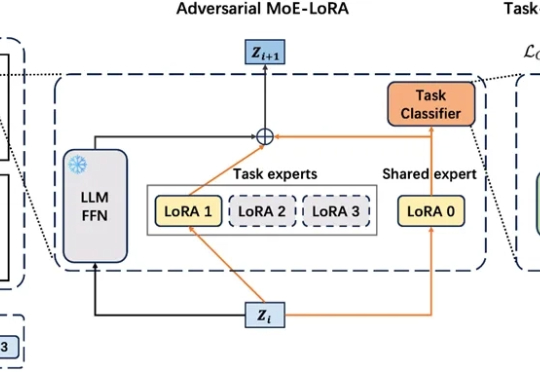
在工业级大语言模型(LLM)应用中,动态适配任务与保留既有能力的 “自进化” 需求日益迫切。真实场景中,不同领域语言模式差异显著,LLM 需在学习新场景合规规则的同时,不丢失旧场景的判断能力。这正是大模型自进化核心诉求,即 “自主优化跨任务知识整合,适应动态环境而无需大量外部干预”。