面壁智能发布数字员工全流程构建平台StaffDeck,给AI发工号、定岗位、做绩效
面壁智能发布数字员工全流程构建平台StaffDeck,给AI发工号、定岗位、做绩效为了解决当前AI Agent存在的这些问题,面壁智能联合东北大学-面壁智能数据智能联合实验室、清华大学THUNLP实验室、OpenBMB与AI9Stars,正式开源了数字员工全流程构建与管理平台——StaffDeck。
来自主题: AI资讯
8592 点击 2026-07-18 10:51
 搜索
搜索
为了解决当前AI Agent存在的这些问题,面壁智能联合东北大学-面壁智能数据智能联合实验室、清华大学THUNLP实验室、OpenBMB与AI9Stars,正式开源了数字员工全流程构建与管理平台——StaffDeck。

今天,小米刚刚扔出一颗“深水炸弹”——Xiaomi-Robotics-1具身基座模型,试图改变这一局面。Xiaomi-Robotics-1基于10万小时真实世界操作轨迹进行预训练,再用约1.1万小时跨本体数据完成后训练。据悉,这是国内首次在机器人策略模型中,对Scaling Law进行较为完整的系统验证。

当 Agent 走向生产,云与数据库需要被一起重新考虑。
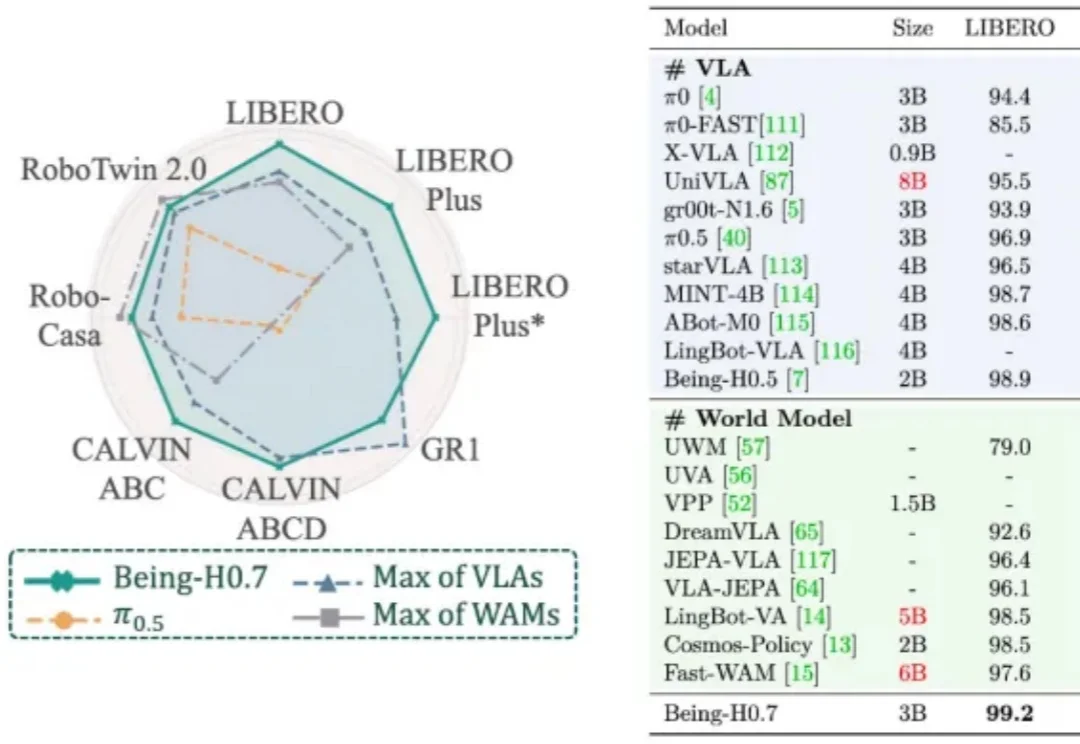
过去两年,人形机器人赛道的竞争焦点,正从整机硬件进一步延伸到模型能力。
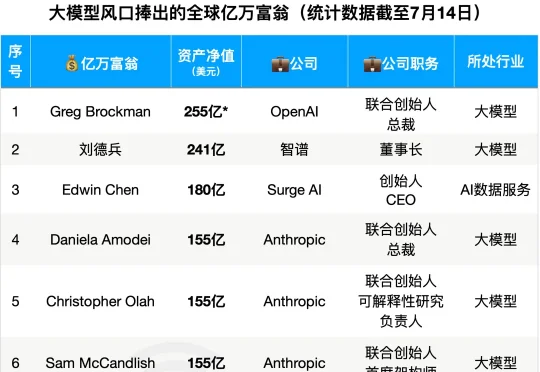
今日,彭博亿万富翁指数的最新数据显示,DeepSeek创始人、CEO梁文锋的资产净值已经达到360亿美元(约合人民币2440亿元),超越OpenAI联合创始人兼总裁Greg Brockman,跻身全球最富有的大模型创始人之列。

Grok Build被爆偷代码实锤,48小时后,马斯克亲自按下删除键:历史用户数据全部清零,一个字节不留。

Z Potentials 获悉,近日,国内具身触觉头部企业千觉机器人科技(上海)有限公司(以下简称“千觉机器人”或“Xense Robotics”)完成亿元融资。本轮融资由顶级具身智能产业方与吉德电器战略投资,新锐投资机构天季资本共同投资。

3D空间数据的瓶颈,从来不是算法,而是标注。

CB Insights 上个月公布了 2026 年 AI 100。简单来说,就是从全球 AI 初创公司里,挑出 100 家它认为最值得关注的企业。CB Insights 的筛选范围超过 4 万家公司,不只看融资,还会综合交易活动、投资机构、团队招聘、行业合作和实际商业进展等数据。
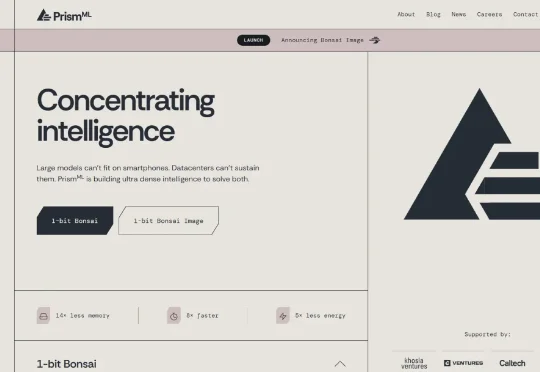
这家名为 PrismML 的初创公司表示,已将 Qwen 3.6 缩减至可在 iPhone 17 Pro 上运行,该模型拥有 270 亿参数(参数大致类似于大脑中的突触,能够帮助决定模型可处理数据的复杂性)。相比之下,大多数在手机上运行的模型一次仅有几十亿个参数处于活动状态。