
新一代记忆智能体框架MIA:让智能体告别「失忆式工作」,在持续进化中变强
新一代记忆智能体框架MIA:让智能体告别「失忆式工作」,在持续进化中变强如今的大多数智能体,仍然活在一种「失忆式工作」模式中:每一次检索都是从零开始,每一条推理路径都无法沉淀,每一次失败也不会转化为经验。它们虽能多轮交互,但很难在深度研究中持续变强。
来自主题: AI技术研报
9610 点击 2026-04-20 14:02
 搜索
搜索
如今的大多数智能体,仍然活在一种「失忆式工作」模式中:每一次检索都是从零开始,每一条推理路径都无法沉淀,每一次失败也不会转化为经验。它们虽能多轮交互,但很难在深度研究中持续变强。

今天,来自ZJU-REAL的团队带来了ClawGUI,一个覆盖GUI智能体在线RL训练、标准化评测、真机部署完整生命周期的开源框架。不是三个独立工具的简单拼接,而是一条打通的流水线:用ClawGUI-RL训练,用ClawGUI-Eval评测,用OpenClaw-GUI部署,端到端验证。
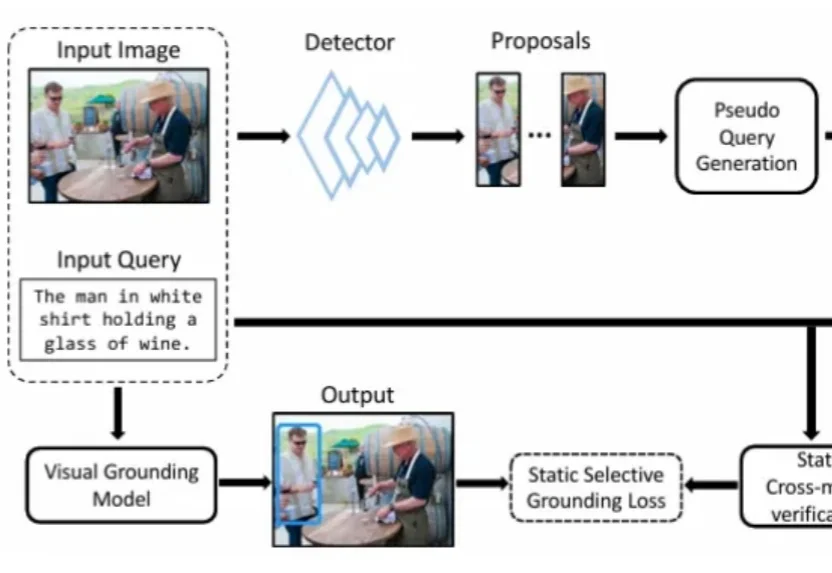
本文是北京大学彭宇新教授团队在视觉定位方向的最新研究成果,相关论文已被顶级国际期刊 IEEE TPAMI 接收。为视觉定位模型赋予「自知之明」能力 —— 通过自监督的关联校正与验证模块,在训练过程中动态识别、衰减并纠正错误的监督信号。大量实验证明,让模型学会「自我纠错」,是突破弱监督视觉定位瓶颈的有效途径。

当强化学习后训练的大规模 rollout 已经被证明能够提升图像生成模型的偏好对齐能力,推理负担就成了制约训练速度的核心瓶颈。来自 NVIDIA、港大和 MIT 的团队提出的 Sol-RL,通过「FP4 先探索、BF16 再训练」的后训练框架,将达到等效 reward 水平的收敛速度最高提升到 4.64x,在训练速度与对齐效果之间给出了一条更具工程可行性的解法。
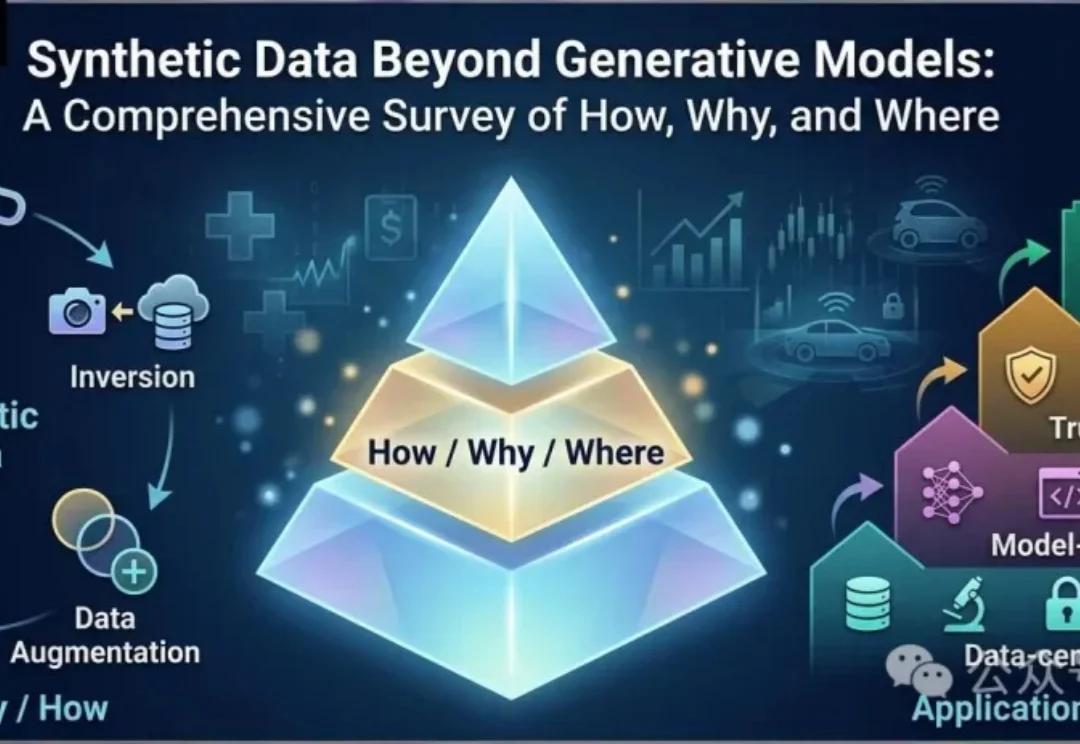
最新研究提出合成数据的全新分类框架,突破「生成模型=合成数据」的传统认知,涵盖反演、仿真与数据增强等方法,并按应用层次划分为数据中心AI、模型中心AI、可信AI和具身AI。

据外媒The Information曝料,微软近期刚刚重组了Copilot工程团队,并计划靠“龙虾”(开源AI Agent框架OpenClaw的昵称)逆风翻盘。这一重大组织变革由CEO萨蒂亚·纳德拉(Satya Nadella)亲自操刀,被列为公司“头等优先事项”。他提拔高管并组建了一支12人精锐队伍,计划在Copilot中构建类OpenClaw的AI Agent产品,

随着机器人操作从短程、单步技能逐步走向长程、富接触、需要持续协调与恢复能力的复杂任务,传统以二元成功率为核心的评测方式开始暴露出明显局限。它能够回答 “任务是否完成”,却难以回答 “策略推进到了哪里”“执行过程是否高效稳定”“失败究竟发生在什么阶段”。

模思智能成立于2024年,位于上海徐汇区,由上海创智学院与复旦大学联合孵化,是国内少数完成“全模态基座模型能力闭环”的初创公司之一,致力于构建统一Token表达框架下的“情境智能”能力,推动Agent系统在真实世界中的自主交互与任务执行。
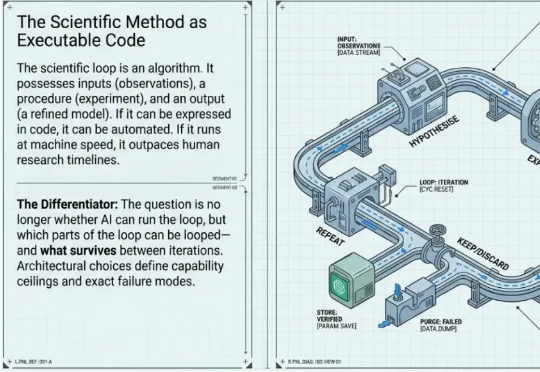
今天 Interesting Engineering++ 发了一篇长文,把这些系统放在同一个分析框架里做了横评,回答的就是这些问题。原文地址:interestingengineering.substack.com/p/the-loop-is-the-lab

近日,支付宝开始内测一款名为AClaw的“AI龙虾”小程序。如今,支付宝搜索“龙虾”,结果页除了满屏的外卖推荐,服务一栏里还会出现AClaw的身影。根据官方介绍,AClaw是一个基于当前热门AI Agent框架OpenClaw的Agent类应用。