
突破视觉仿真算力瓶颈!新一代具身智能仿真框架开源:高吞吐并行高保真渲染助力规模化训练
突破视觉仿真算力瓶颈!新一代具身智能仿真框架开源:高吞吐并行高保真渲染助力规模化训练为了攻克这些制约具身智能领域发展的核心难题,清华大学智能产业研究院(AIR)DISCOVER Lab联合谋先飞技术、原力灵机、求之科技和地瓜机器人,提出了GS-Playground通用多模态仿真框架。
来自主题: AI技术研报
7952 点击 2026-05-03 22:41
 搜索
搜索
为了攻克这些制约具身智能领域发展的核心难题,清华大学智能产业研究院(AIR)DISCOVER Lab联合谋先飞技术、原力灵机、求之科技和地瓜机器人,提出了GS-Playground通用多模态仿真框架。
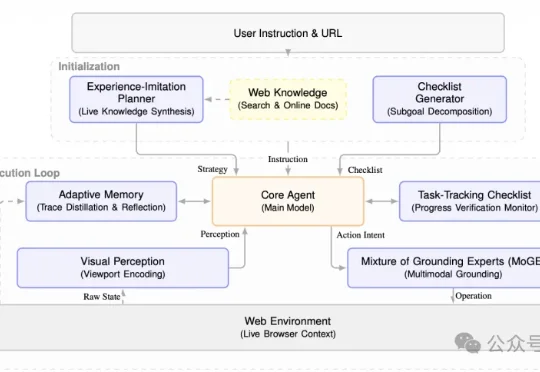
伦敦大学学院(UCL)、普林斯顿大学和爱丁堡大学的研究团队联合推出了Avenir-Web,让现有多模态模型像人类一样使用网页。现有的Web Agent在面对复杂的网页结构(如 iframe、Shadow DOM)时,往往会陷入“定位不准”“缺乏常识”或“走着走着就忘了”的窘境。
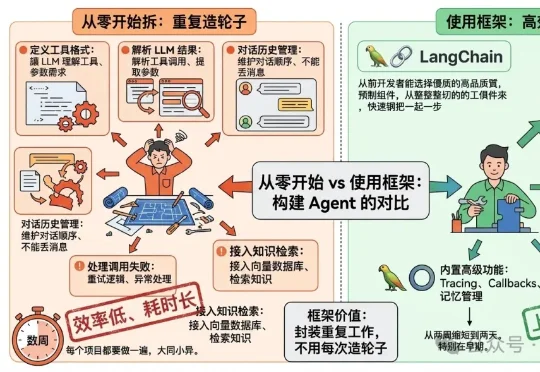
我的感受是框架用起来快,但有几个实际痛点。第一是抽象层太多,调试的时候不知道哪步出了问题,得一层层往下扒;第二是版本升级经常有破坏性变更,线上稳定性难保证;第三是框架的通用设计往往和具体业务需求有偏差,定制起来反而更费劲。手搓的代码完全在自己掌控之内,可观测性好、出问题好排查,也更方便做性能优化。所以我现在的策略是核心逻辑手写,只在边缘功能上用框架的工具。
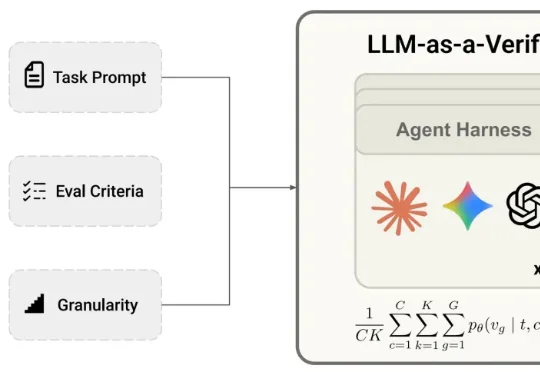
Transformer论文作者Lukasz Kaiser以及GAN作者Bing Xu转发关注了一项工作——LLM-as-a-Verifier验证框架,该方法是一种通用的验证机制,可与任意Agent Harness和模型结合。

OpenClaw最新版本官宣,DeepSeek V4 Flash正式成为默认大模型,250k+星标的全球最火开源Agent框架,把中国最强开源AI推上了C位。
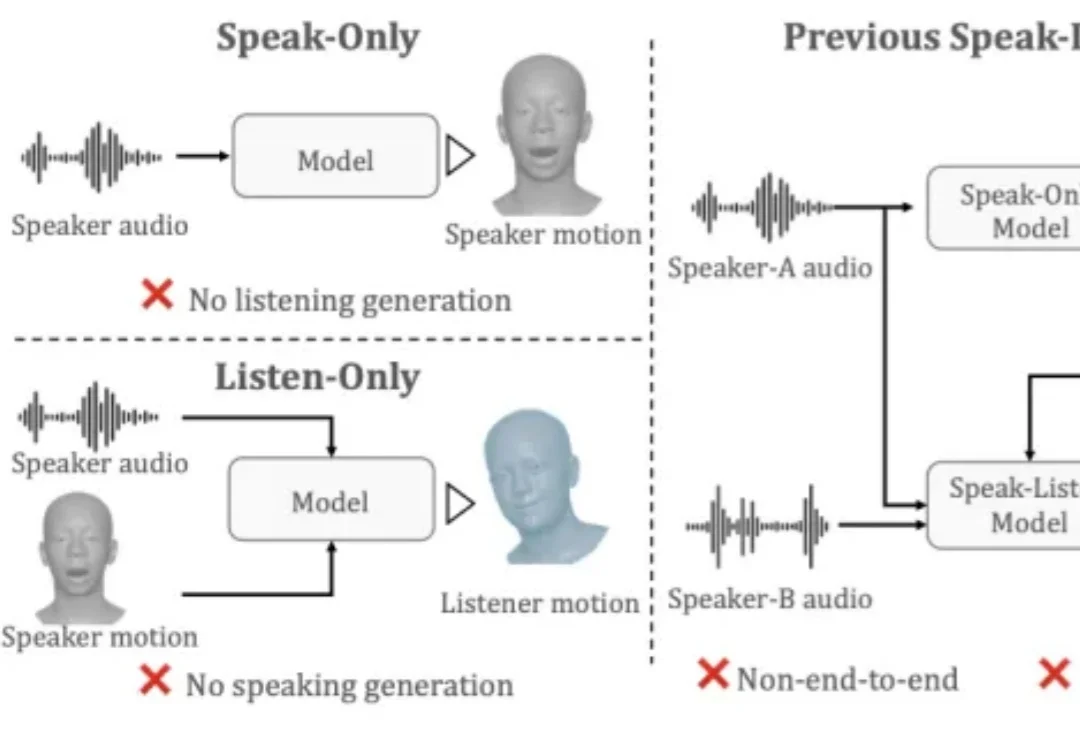
在游戏 NPC、虚拟主播、在线客服等数字人对话场景中,倾听时的 “扑克脸” 问题一直是行业长期痛点 —— 虚拟人说话时口型可以做到精准同步,但倾听时却表情僵硬、毫无反应,严重影响对话的自然感和沉浸感。盛大 AI 研究院(东京)与东京大学联合提出 UniLS(Unified Listening and Speaking),首个仅凭双轨音频即可端到端同时驱动说话和倾听面部动作的统一框架。

大模型人才涌入,帮助智驾厂商突破原有技术框架上限。

乐鑫信息科技 (688018.SH) 正式推出 ESP-Claw —— 以 Chat Coding(聊天造物)为核心的 AI 智能体框架。它突破了编程边界,让人人都能通过对话定义智能设备。

先说一个很多人没意识到的事实:2026年了,每个主流Agent框架底下的工具调用训练数据,格式全是乱的。
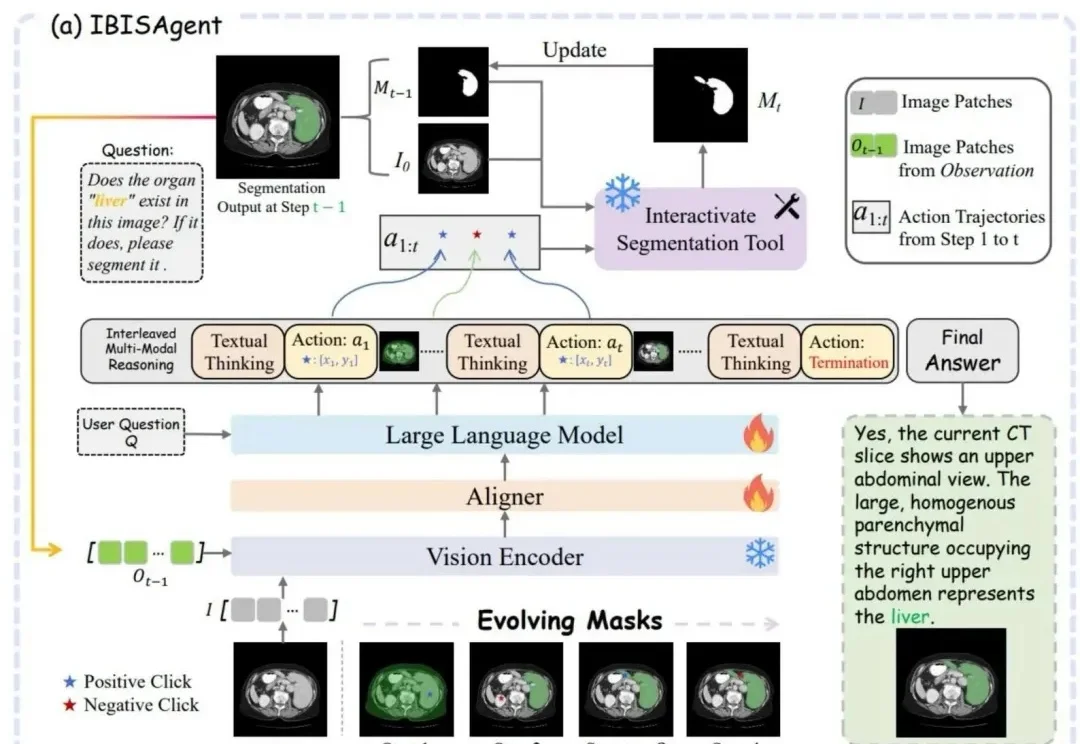
这个生物医学视觉推理框架,被CVPR 2026接收了!