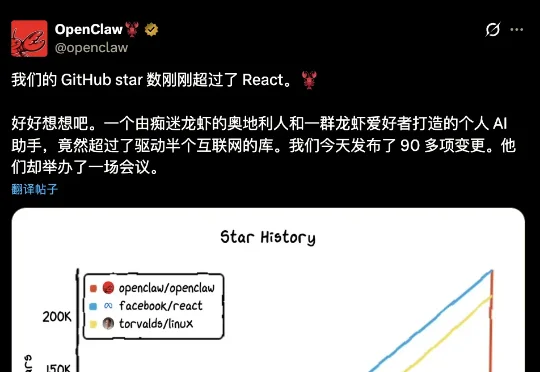
刚刚,OpenClaw登顶GitHub软件星标历史第一!已超越Linux
刚刚,OpenClaw登顶GitHub软件星标历史第一!已超越Linux仅用两月,本地AI框架OpenClaw击败Linux,登顶GitHub星标榜!本文回顾了OpenClaw爆火之路,及其背后反映的开源社区趋势变化。
来自主题: AI资讯
9841 点击 2026-03-03 11:36
 搜索
搜索
仅用两月,本地AI框架OpenClaw击败Linux,登顶GitHub星标榜!本文回顾了OpenClaw爆火之路,及其背后反映的开源社区趋势变化。
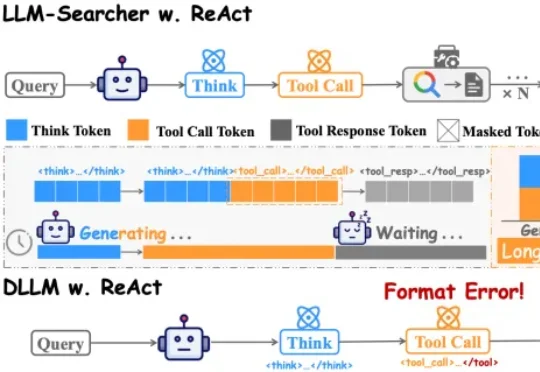
中国人民大学团队在论文DLLM-Searcher中,第一次让扩散大语言模型(dLLM)学会了这种“一心二用”的本事。目前主流的搜索Agent,不管是Search-R1还是R1Searcher,用的都是ReAct框架。这个框架的执行流程是严格串行的:

本篇文章被 ICRA 2026 接收并获得 IROS 2025 双料 Workshop 最佳论文,第一作者张子哲(site: zizhe.io)是宾夕法尼亚大学机器人学硕士生,同时在 GRASP 实验室担任科研助理,导师为 Nadia Figueroa 教授,研究兴趣涵盖机器学习,安全控制以及人机交互。

各位对Agent Skill早已轻车熟路。不可否认,在Claude code、Openclaw的加持下,这套框架效果极佳。但工业界的痛点在于:它几乎沦为了超大型闭源API的专属玩具。当您的项目面临金融

近期发表于 TMLR 的论文《Large Language Model Reasoning Failures》对这一问题进行了系统性梳理。该研究并未围绕 “模型是否真正理解” 展开哲学层面的争论,而是采取更加务实的路径 —— 通过整理现有文献中的失败现象,构建统一框架,系统分析大语言模型的推理短板。
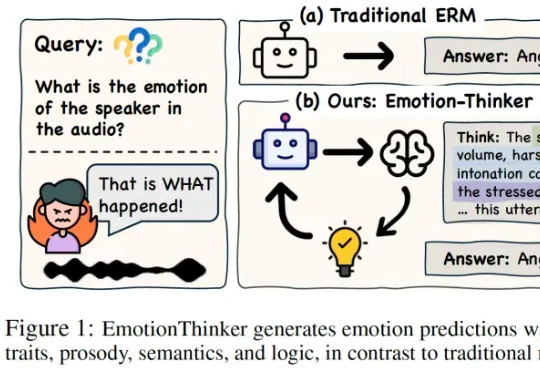
SpeechLLM 是否具备像人类一样解释 “为什么” 做出情绪判断的能力?为此,研究团队提出了EmotionThinker—— 首个面向可解释情感推理(Explainable Emotion Reasoning)的强化学习框架,尝试将 SER 从 “分类任务” 提升为 “多模态证据驱动的推理任务”。
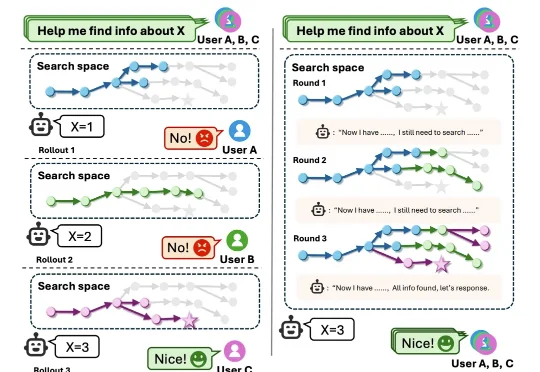
来自东南大学、微软亚洲研究院等机构的研究团队提出了一种全新的解决方案——Re-TRAC(REcursive TRAjectory Compression),这个框架让 AI 智能体能够「记住」每次探索的经验,在多个探索轨迹之间传递经验,实现渐进式的智能搜索。
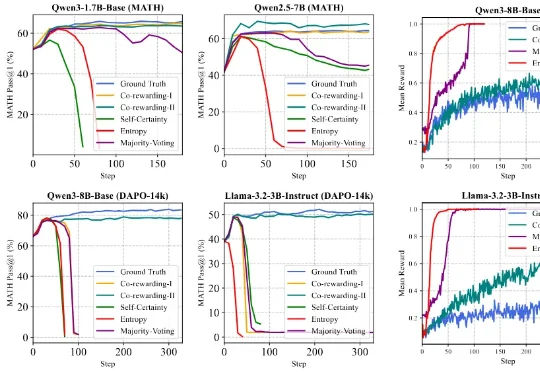
针对这一挑战,来自香港浸会大学和上海交通大学的可信机器学习和推理组提出了一个全新的自监督 RL 框架 ——Co-rewarding。该框架通过在数据端或模型端引入互补视角的自监督信号,稳定奖励获取,提升 RL 过程中模型奖励投机的难度,从而有效避免 RL 训练崩溃,实现稳定训练和模型推理能力的诱导。
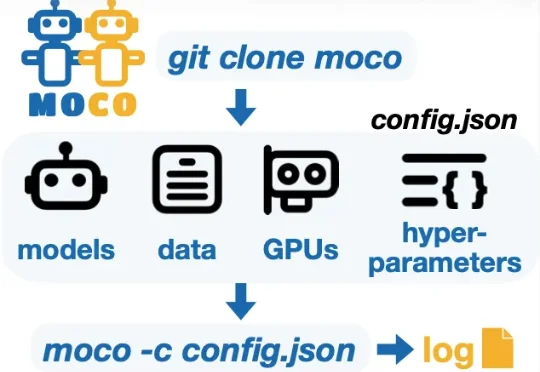
为了支持多模型协同研究并加速这一未来愿景的实现,华盛顿大学 (University of Washington) 冯尚彬团队联合斯坦福大学、哈佛大学等研究人员提出 MoCo—— 一个针对多模型协同研究的 Python 框架。MoCo 支持 26 种在不同层级实现多模型交互的算法,研究者可以灵活自定义数据集、模型以及硬件配置,比较不同算法,优化自身算法,以此构建组合式人工智能系统。MoCo 为设计、
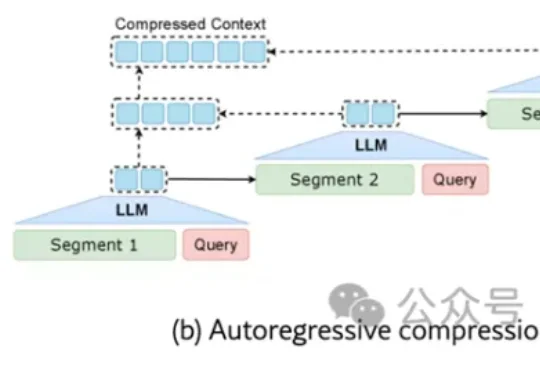
来自清华大学、鹏城实验室与阿里巴巴未来生活实验室的联合研究团队发现:现有任务相关的压缩方法不仅陷入效率瓶颈——要么一次性加载全文(效率低),要么自回归逐步压缩(速度慢),更难以兼顾“保留关键信息”与“保持自然语言可解释性”。