重磅!Google Gemma-4-31B 模型被彻底破解!【附越狱版下载链接】
重磅!Google Gemma-4-31B 模型被彻底破解!【附越狱版下载链接】Google 最新发布的 Gemma-4-31B 基础模型出现了越狱版本,安全限制被完全移除。这个名为"Gemma-4-31B-JANG_4M-CRACK"的模型已经公开发布在 Hugging Face 上,任何人都可以下载使用。
来自主题: AI资讯
13883 点击 2026-04-06 20:32
 搜索
搜索
Google 最新发布的 Gemma-4-31B 基础模型出现了越狱版本,安全限制被完全移除。这个名为"Gemma-4-31B-JANG_4M-CRACK"的模型已经公开发布在 Hugging Face 上,任何人都可以下载使用。

如果你是 Kimi Code 会员,现在就可以去控制台申请抢先体验——据说能提前体验新模型。消息虽非官方,但足以让开发者兴奋。毕竟,Kimi K2.5 接入 Kimi Code 才过去不到两个月。
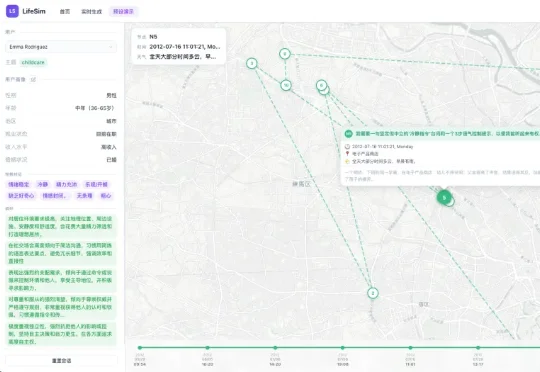
来自复旦大学、上海创智学院的研究人员提出 LifeSim,一个面向个性化助手评测的长程用户生活模拟框架。LifeSim 同时建模用户内部认知过程与外部物理环境,生成连贯的生活轨迹、事件序列与多轮交互行为;在此基础上,研究团队进一步构建了 LifeSim-Eval,用于系统评测模型在长期个性化交互中的能力边界。

Agent 时代,我们需要正确的计费和工程设计哲学,这是 Xiaomi MiMo 大模型负责人罗福莉刚刚在 X 上发表的观点。前两天,我们报道了一则消息 ——Anthropic 宣布,即日起,Claude Pro 和 Max 订阅用户,不得再将订阅额度用于 OpenClaw 等第三方 Agent 框架。想继续用?那就必须切换到按用量付费的 API。

具身智能独角兽Generalist,刚刚推出了最新的研究成果——新模型Gen-1。在包装手机和折叠纸箱这些精细活儿上,它把机器人的成功率从64%硬生生拉到了99%,几乎告别了手残职业病。
Karpathy 表示,大多数人使用 LLM 处理文档的方式,基本都类似于 RAG:你上传一组文件,模型在查询时检索相关片段,然后生成答案。这种方式是有效的,但问题在于每一次提问,模型都在从零重新发现知识。没有积累。
OpenAI简直漏风漏得跟筛子一样,关于最新Spud(土豆)模型的消息,又双叒叕来了。这颗「土豆」,就是万众瞩目的GPT-6。据爆料,这颗「土豆」已经彻底煮熟了,4月14号就会发布。

2026 年,阿联酋哈利法大学的邹航博士和他所在的团队,做出了全世界第一个射频大模型,名字叫 RF GPT。这个模型能直接看懂无线信号,就像 GPT 4o 能看懂图片、Qwen2 Audio 能听懂声音一样。你把无线信号扔给它,它不仅能告诉你这里面有几种信号、分别是什么技术,还能分析出有没有信号在打架、哪个是 5G 哪个是蓝牙、甚至能数出来 WiFi 网络里有多少个用户同时在用。
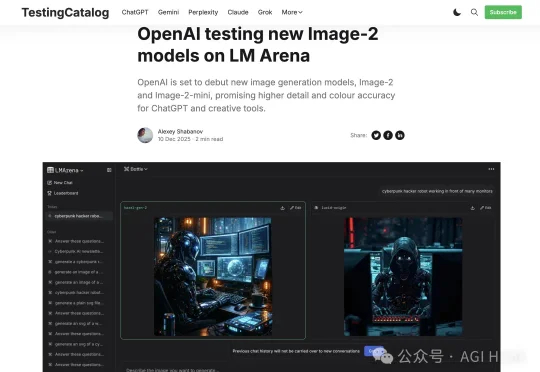
OpenAI 的下一代图像模型 GPT-Image-2,今天在 Chatbot Arena 上被人发现了。独立开发者 levelsio 率先爆料,这个模型以三个代号悄悄上线了 Arena:maskingtape-alpha、gaffertape-alpha、packingtape-alpha。
通用世界模型评测榜单 WorldScore 登顶、建立具身世界模型评测榜单 WorldArena 、发布通用世界模型 WorldScape 、发布世界-动作模型 WorldScape Policy,这家低调的世界模型创业公司 Manifold AI(流形空间)近期走出隐身模式频频出手,开始领跑世界-动作模型具身新路线。