
突破万次连续编辑极限!中科院提出首个理论保稳的知识保留方法
突破万次连续编辑极限!中科院提出首个理论保稳的知识保留方法LyapLock首次让大模型在上万次知识更新中稳住旧记忆、精准学新知。它用「虚拟队列」实时监控遗忘风险,动态平衡新旧知识,理论保证长期不崩盘,编辑效果比主流方法提升11.89%,还能赋能现有模型,让AI真正学会「持续成长」。
来自主题: AI技术研报
10715 点击 2026-03-12 10:16
 搜索
搜索
LyapLock首次让大模型在上万次知识更新中稳住旧记忆、精准学新知。它用「虚拟队列」实时监控遗忘风险,动态平衡新旧知识,理论保证长期不崩盘,编辑效果比主流方法提升11.89%,还能赋能现有模型,让AI真正学会「持续成长」。
上周有个朋友跟我吐槽,说他们线上跑的 Agent,单次任务 token 消耗到了六位数。

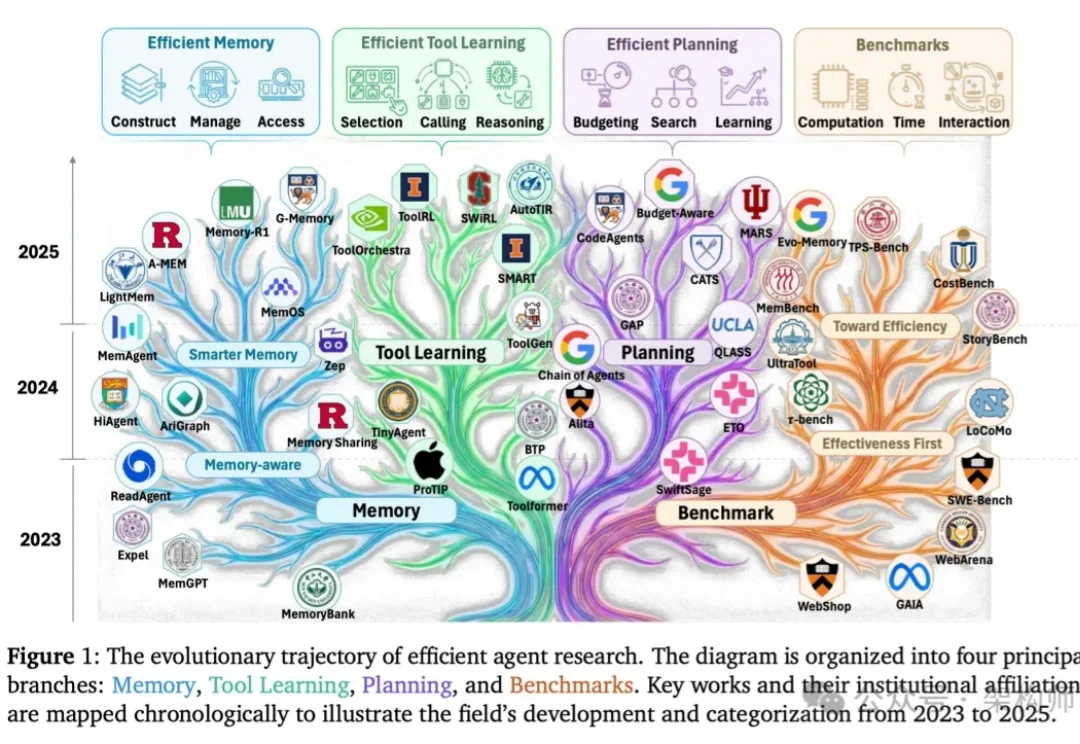
随着大语言模型 Agent 开始在对话、问答与复杂交互环境中长期运行,“记忆该如何设计” 正在成为一个绕不开的核心问题。

刚刚,谷歌发布了首个原生多模态(Multimodal)嵌入模型——Gemini Embedding 2。这次模型最大的变化在于:把文本、图像、视频、音频和文档,全部映射进同一个统一的嵌入空间。
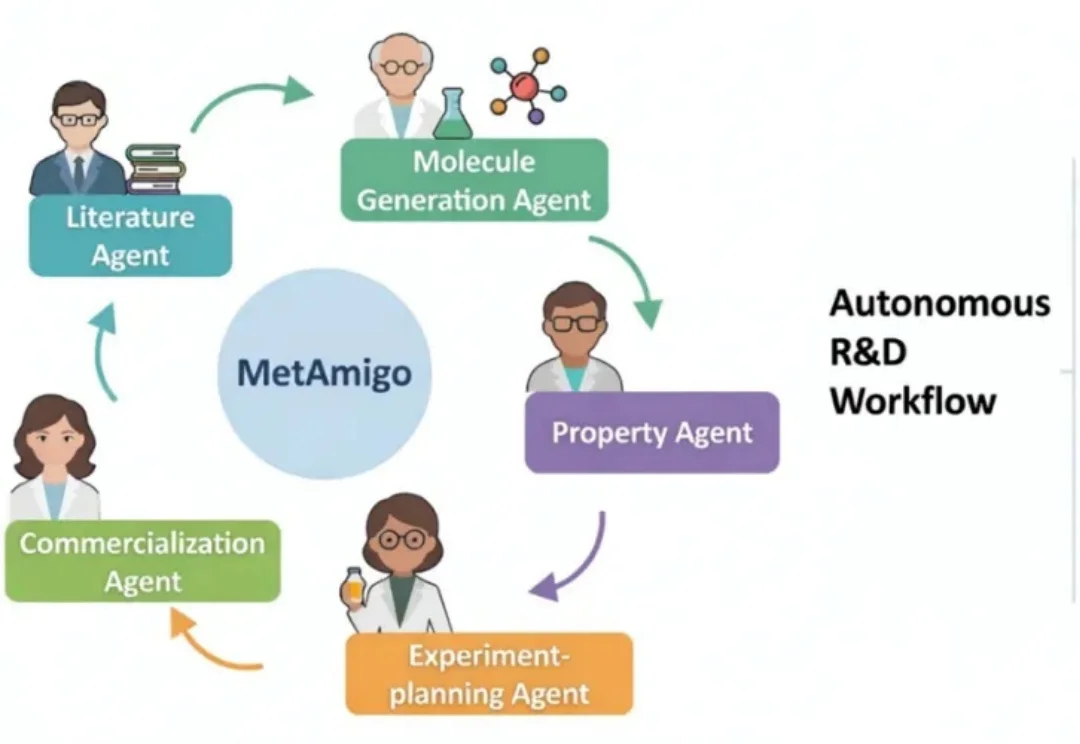
2026 年伊始,AI 的进化逻辑正从「单一工具赋能」转向「场景深度共生」,当大模型在各领域持续突破,前沿科研与新材料研发领域,正迎来一场由 Agentic AI 驱动的效率革命。
好家伙!龙虾老吃家还得看中国。
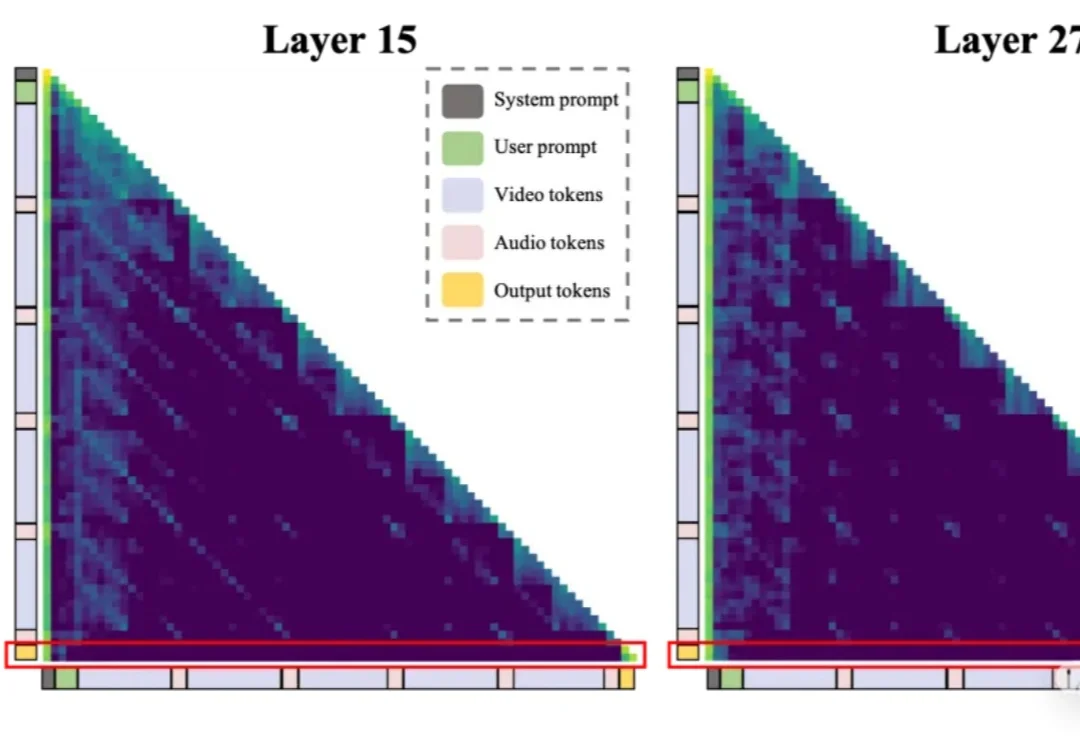
一段几十秒的音视频,上万Token,一半以上是冗余——Omni-LLM的计算浪费,比想象中更严重。

近年来,大规模视频扩散模型在视频生成领域取得了显著进展。然而,采样效率低下仍然是这类模型的核心瓶颈。

当前,大语言模型(LLMs)和视觉语言模型(VLMs)在语义领域的成功未能直接迁移至物理机器人,归根结底在于其互联网原生的基因。

对比学习已成为表征学习中的一种强大范式,能够在不依赖标签的情况下有效利用无标注数据。