
速递|Yann LeCun(杨立坤)新公司AMI Labs聚焦“世界模型”,寻求超50亿美元估值融资
速递|Yann LeCun(杨立坤)新公司AMI Labs聚焦“世界模型”,寻求超50亿美元估值融资知名AI 科学家LeCun周四证实, 他已创办一家新创企业 ——这是科技界人尽皆知的秘密——但他表示不会以首席执行官身份运营这家新公司。
来自主题: AI资讯
8529 点击 2025-12-23 15:23
 搜索
搜索
知名AI 科学家LeCun周四证实, 他已创办一家新创企业 ——这是科技界人尽皆知的秘密——但他表示不会以首席执行官身份运营这家新公司。

参数越小,智商越高?Gemini 3 Flash用百万级长上下文、白菜价成本,把自家大哥Pro按在地上摩擦。谷歌到底掏出了什么黑魔法,让整个大模型圈开始怀疑人生?
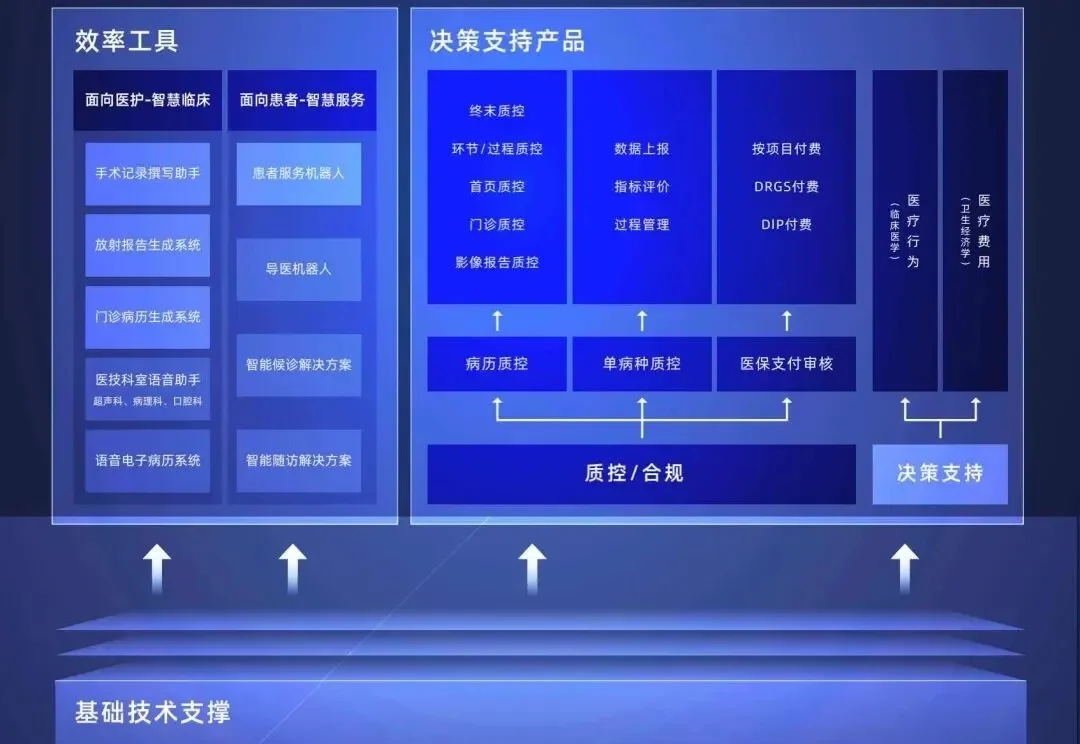
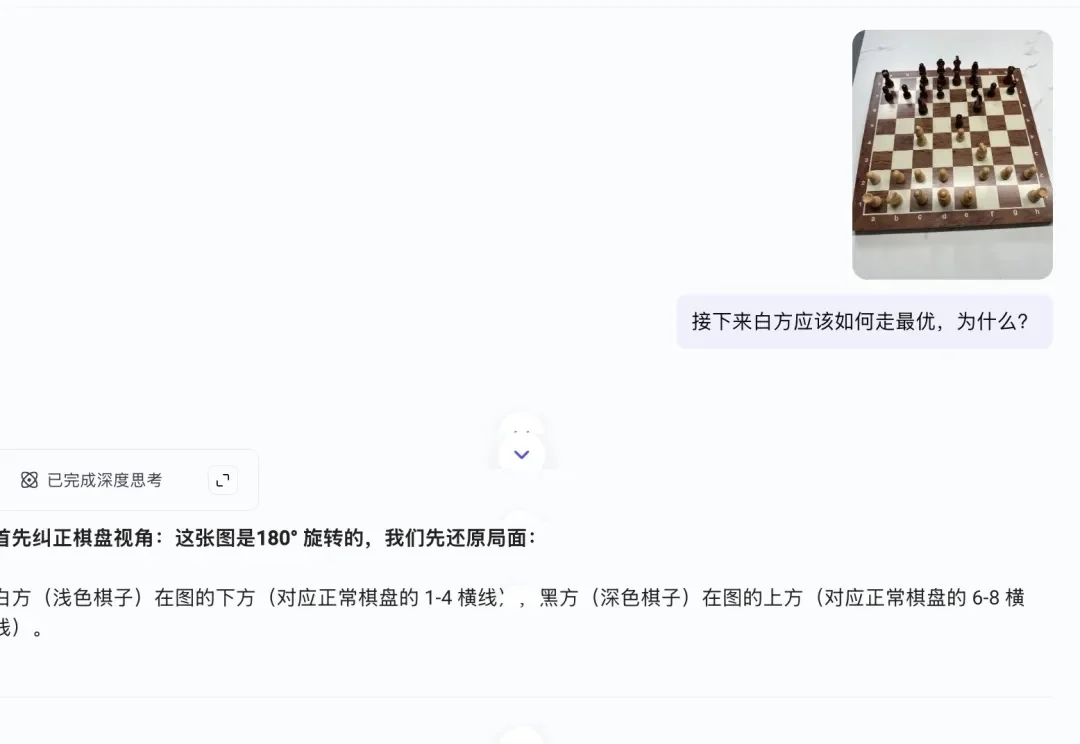
来猜一下,AI时代,医生最哭笑不得的是什么?
最近这段时间,谷歌DeepMind的官方纪录片《The Thinking Game》在AI圈传播挺广。
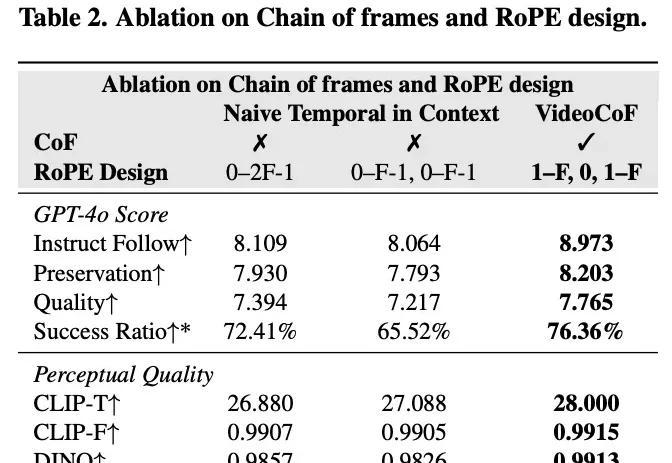
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!

生成式AI狂奔三年,2025迎来架构创新的大年,三条脉络交织演进,伴随着Scaling law(规模定律)遇到天花板的争议,开始定义AI进化的新范式。

近日,在与数学家Hannah Fry的对话中,DeepMind CEO Demis Hassabis回顾了AI在过去一年的飞跃式进展,他谈到了「参差智能」、持续学习、模型幻觉等迈向AGI过程中的关键挑战,并提到AGI带来的社会冲击可能是工业革命的10倍。

在多智能体系统的想象中,我们常常看到这样一幅图景: 多个 AI 智能体分工协作、彼此配合,像一个高效团队一样攻克复杂任务,展现出超越单体智能的 “集体智慧”。

2025倒计时,新SOTA模型涌现没有放缓迹象。一夜之间,编程SOTA模型易主,而且上线即开源,依然来自中国大模型公司——智谱AI,GLM-4.7。

AI不仅会做PPT,写代码,它还能理解更深层次的问题。在美国的一项偏重于文化领域的新基准测试中,中国开源模型Qwen3夺冠,DeepSeek的R1跻身前六,力压多家全球顶级的明星模型。