速递|Boson AI × SGLang 发布 Higgs Audio v3 TTS:让语音智能体实时可控
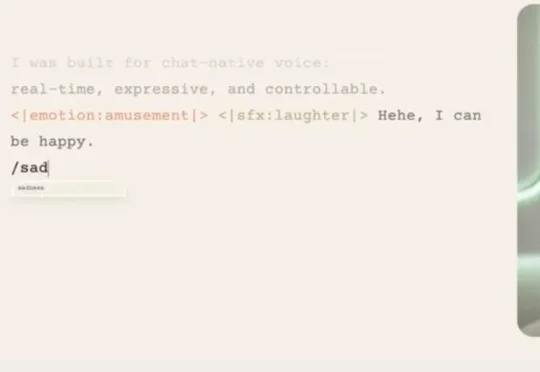
速递|Boson AI × SGLang 发布 Higgs Audio v3 TTS:让语音智能体实时可控Boson AI 与 SGLang-Omni 团队宣布,SGLang-Omni 已完成对 Higgs Audio v3 TTS 的端到端 Serving 支持。作为一家成立于 2023 年的 AI 基础设施公司,李沐与 Alex Smola共同创立了 Boson AI,聚焦大模型时代的系统与基础设施创新。
来自主题: AI资讯
7786 点击 2026-06-06 10:18