ICML 2026|让 Agent 真正协同作战:GoS 为多智能体推理构建共享信念状态
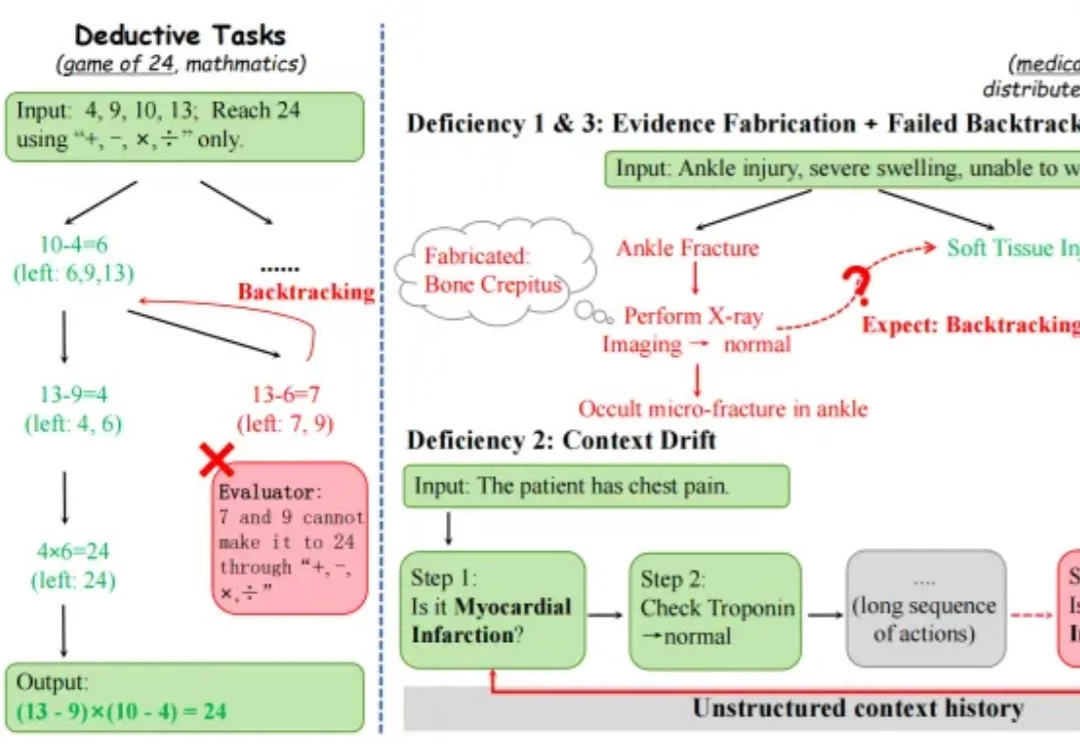
ICML 2026|让 Agent 真正协同作战:GoS 为多智能体推理构建共享信念状态近年来,大语言模型在数学、代码等任务上的表现不断刷新上限,但到了医疗诊断、故障排查这类真实世界任务里,真正困难的是让多个智能体在不确定的动态环境中持续协作推理。
来自主题: AI技术研报
9673 点击 2026-06-08 09:48
 搜索
搜索
近年来,大语言模型在数学、代码等任务上的表现不断刷新上限,但到了医疗诊断、故障排查这类真实世界任务里,真正困难的是让多个智能体在不确定的动态环境中持续协作推理。
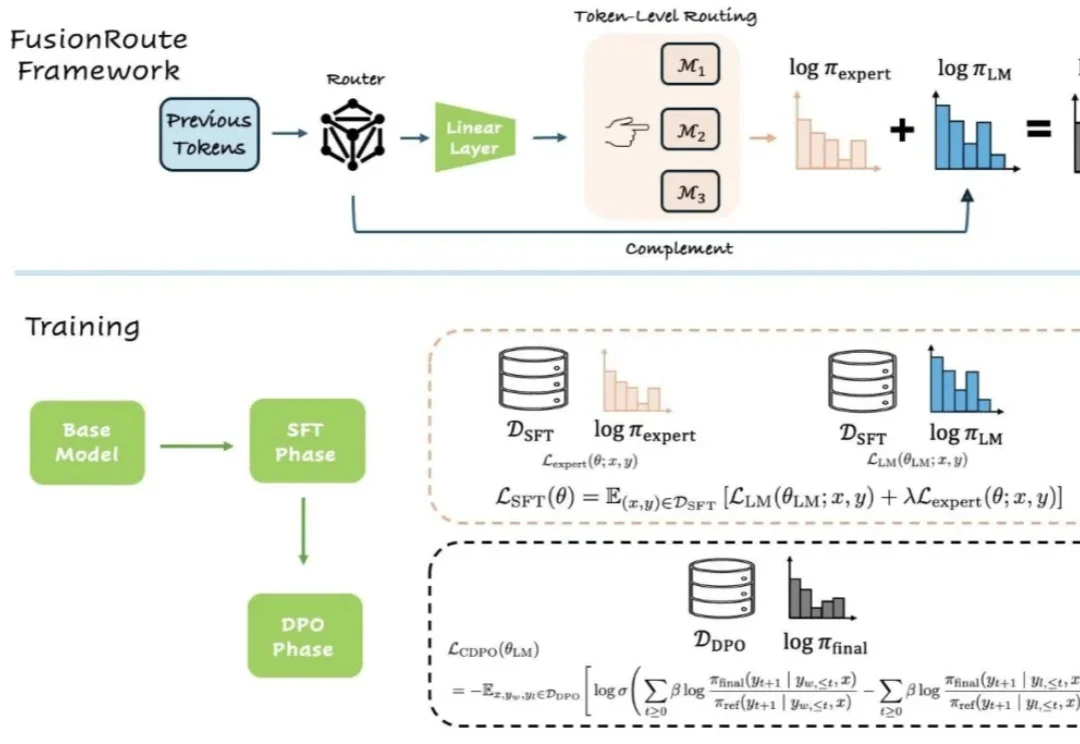
近年来,大语言模型能力的提升,已不再仅仅依赖于更大的模型规模或更多的训练数据。越来越多的研究开始探索另一条路径:通过多个专家模型的协作来完成生成任务。

35岁的周先生在杭州一家金融互联网企业担任AI大模型质检主管,负责对AI与用户交互生成的答案进行把关。2024年11月19日,他突然收到通知,从部门主管调至普通岗位,月薪也从2.5万元降到1.5万元,他拒绝接受。两个多月后,周先生被单方面解除劳动合同。
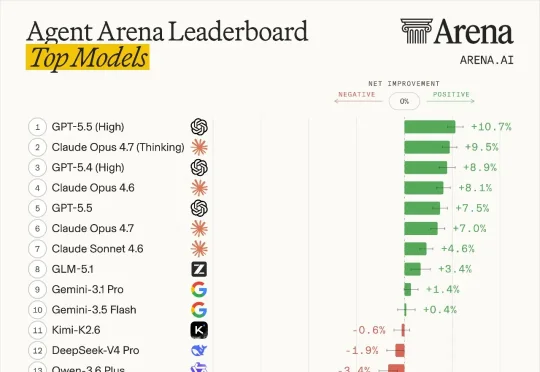
6月4日,Arena.ai发布Agent Arena排行榜,用373,431次真实会话的数据,给18个主流模型的Agent能力排了个座次。先看总榜。Agent Arena的排名依据是“净改进”(Net Improvement),用因果推断方法算出每个模型相对于随机基线的性能提升幅度。正值代表比随机选择更好,负值说明不如随机。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,

早在 2023 年大模型快速发展期,哈工大张民教授立知大模型团队已开展多模态大模型驱动的视频内容创作智能体研究,并全球首发开源了电影制作智能体 FilmAgent 与动画片生成智能体 Anim-Director,受到国内外智能体研究者与文艺创作者的广泛关注。
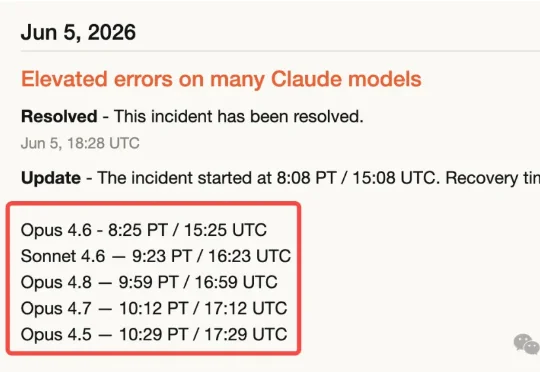
就在昨天,Anthropic 的官方状态页突然挂起一排刺眼的红灯——Claude API、Claude Code、Claude.ai、Claude Cowork……几乎所有核心服务,突然大面积宕机。从 Opus 4.6 到 Opus 4.8,五大模型无一幸免。

最近,一个叫 Emergence AI 的团队做了一场社会实验。它们建了一个持久化的虚拟小镇,把市面上最顶级的几个大模型扔了进去,赋予它们行动的权限。它们想看看,当 AI 真正拥有了不受限制的 15 天,它们会建立一个乌托邦,还是一个疯人院。
OpenSquilla 是一个开源 Agent Harness 框架(https://github.com/opensquilla/opensquilla)。它在 Agent 应用和模型之间加了一层运行中枢。OpenSquilla 由上海基元律动科技有限公司开发。基元律动成立仅几个月后,已完成首轮融资,估值高达1亿美元。