NeurIPS2025 Spotlight | RobustMerge: 多模态大模型高效微调模型合并的全新范式
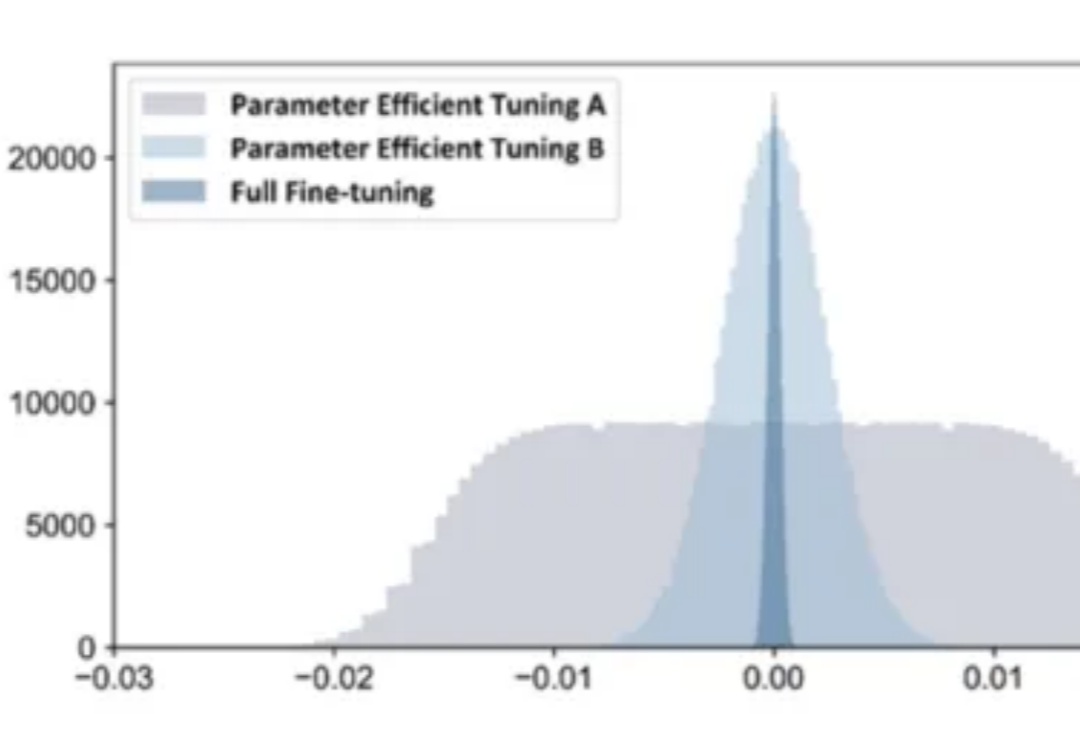
NeurIPS2025 Spotlight | RobustMerge: 多模态大模型高效微调模型合并的全新范式在 AI 技术飞速发展的今天,如何高效地将多个专业模型的能力融合到一个通用模型中,是当前大模型应用面临的关键挑战。全量微调领域已经有许多开创性的工作,但是在高效微调领域,尚未有对模型合并范式清晰的指引。
来自主题: AI技术研报
8374 点击 2025-11-10 14:25