英伟达、DeepSeek集体跟进!18个月前被忽视,如今统治AI推理
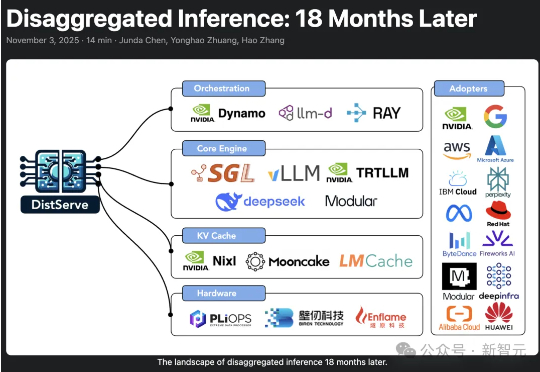
英伟达、DeepSeek集体跟进!18个月前被忽视,如今统治AI推理2024年,加州大学圣地亚哥分校「Hao AI Lab」提出了DistServe的解耦推理理念,短短一年多时间,迅速从实验室概念成长为行业标准,被NVIDIA、vLLM等主流大模型推理框架采用,预示着AI正迈向「模块化智能」的新时代。
来自主题: AI技术研报
11198 点击 2025-11-09 15:37
 搜索
搜索
2024年,加州大学圣地亚哥分校「Hao AI Lab」提出了DistServe的解耦推理理念,短短一年多时间,迅速从实验室概念成长为行业标准,被NVIDIA、vLLM等主流大模型推理框架采用,预示着AI正迈向「模块化智能」的新时代。
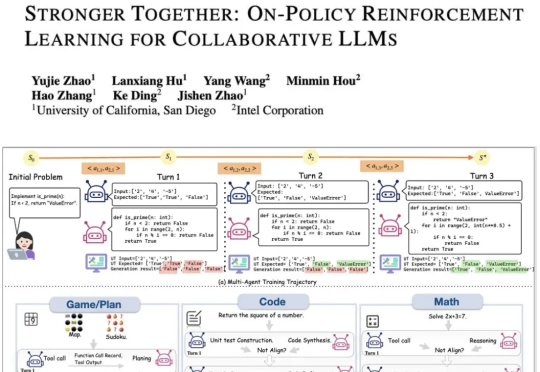
现有的LLM智能体训练框架都是针对单智能体的,多智能体的“群体强化”仍是一个亟须解决的问题。为了解决这一领域的研究痛点,来自UCSD和英特尔的研究人员,提出了新的提出通用化多智能体强化学习框架——PettingLLMs。支持任意组合的多个LLM一起训练。

《Science》的一篇新文章指出,大模型存在一个先天难解的软肋:幻觉难以根除。AI厂商让大模型在不确定性情况下说「我不知道」,虽然有助于减少模型幻觉,但可能因此影响用户留存与活跃度,动摇商业根本。

北京大学,银河通用,阿德莱德大学,浙江大学等机构合作,探究如何构建具身导航的基座模型(Embodied Navigation Foundation Model)提出了NavFoM,一个跨任务和跨载体的导航大模型。实现具身导航从“专用”到“通用”的技术跃进
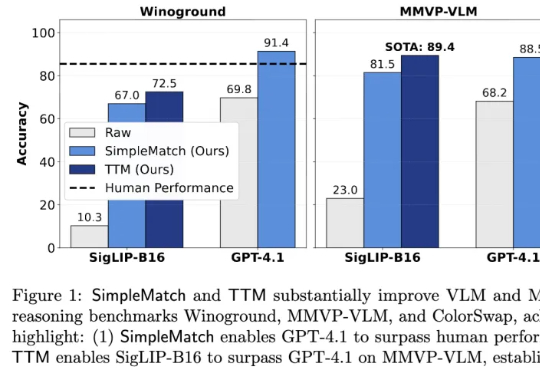
加州大学河滨分校团队发现,AI组合推理表现不佳部分源于评测指标过于苛刻。他们提出新指标GroupMatch和Test-Time Matching算法,挖掘模型潜力,使GPT-4.1在Winoground测试中首次超越人类,0.2B参数的SigLIP-B16在MMVP-VLM基准测试上超越GPT-4.1并刷新最优结果。这表明模型的组合推理能力早已存在,只需合适方法在测试阶段解锁。

近日,诺贝尔奖得主、美国华盛顿大学教授大卫·贝克(David Baker)和团队再次将 AI 成果送上 Nature,他们开发出一种基于 AI 的蛋白质结构生成模型 RFdiffusion,能在指定病毒表面特定表位的情况下,辅助人类从头设计出能够与之结合的抗体结构。

去年,谢赛宁(Saining Xie)团队发布了 Cambrian-1,一次对图像多模态模型的开放式探索。但团队没有按惯例继续推出 Cambrian-2、Cambrian-3,而是停下来思考:真正的多

近日,谷歌推出了一种全新的用于持续学习的机器学习范式 —— 嵌套学习,模型不再采用静态的训练周期,而是以不同的更新速度在嵌套层中进行学习,即将模型视为一系列嵌套问题的堆叠,使其能够不断学习新技能,同时又不会遗忘旧技能。

众所周知,大型语言模型(LLM)的根本运作方式是预测下一个 token(词元),能够保证生成的连贯性和逻辑性,但这既是 LLM 强大能力的「灵魂」所在,也是其枷锁,将导致高昂的计算成本和响应延迟。 可

前段时间Trae下架了Claude,标志着但凡跟中国沾边AI工具都禁止使用 Claude 但我一点都不慌,因为已经很久没用 Claude 了 尤其在编程赛道上,国产大模型已经通过内部互卷站起来了。