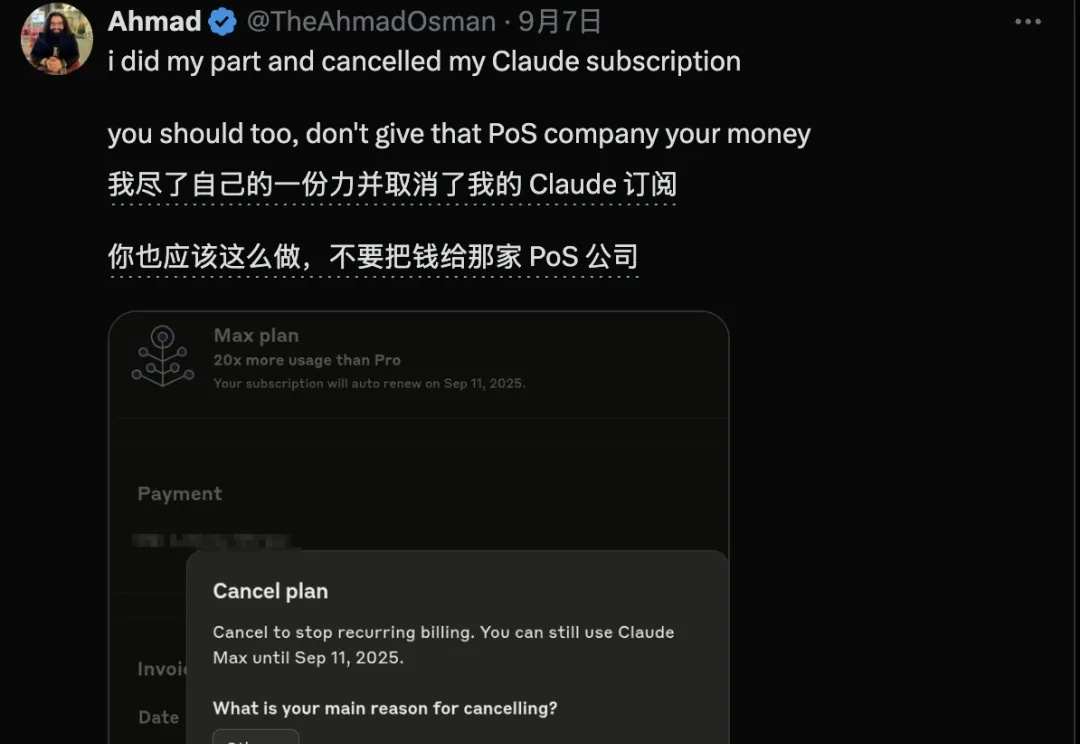
Claude用户退订潮!被指高峰期偷换缩水模型,工程师列9大罪状呼吁全网退订
Claude用户退订潮!被指高峰期偷换缩水模型,工程师列9大罪状呼吁全网退订Claude出现大危机,不是因为最近的某些骚操作,而是产品本身就出了问题。
来自主题: AI资讯
10041 点击 2025-09-10 12:45
 搜索
搜索
Claude出现大危机,不是因为最近的某些骚操作,而是产品本身就出了问题。

刚刚,百度深度思考模型升级上线了!

在现代科学中,几乎所有领域都依赖软件来进行计算实验。但开发这些专用的科学软件是一个非常缓慢、乏味且困难的过程,开发和测试一个新想法(一次“试错”)需要编写复杂的软件,这个过程可能耗费数周、数月甚至数年。

人类一眼就能看懂的文字,AI居然全军覆没。
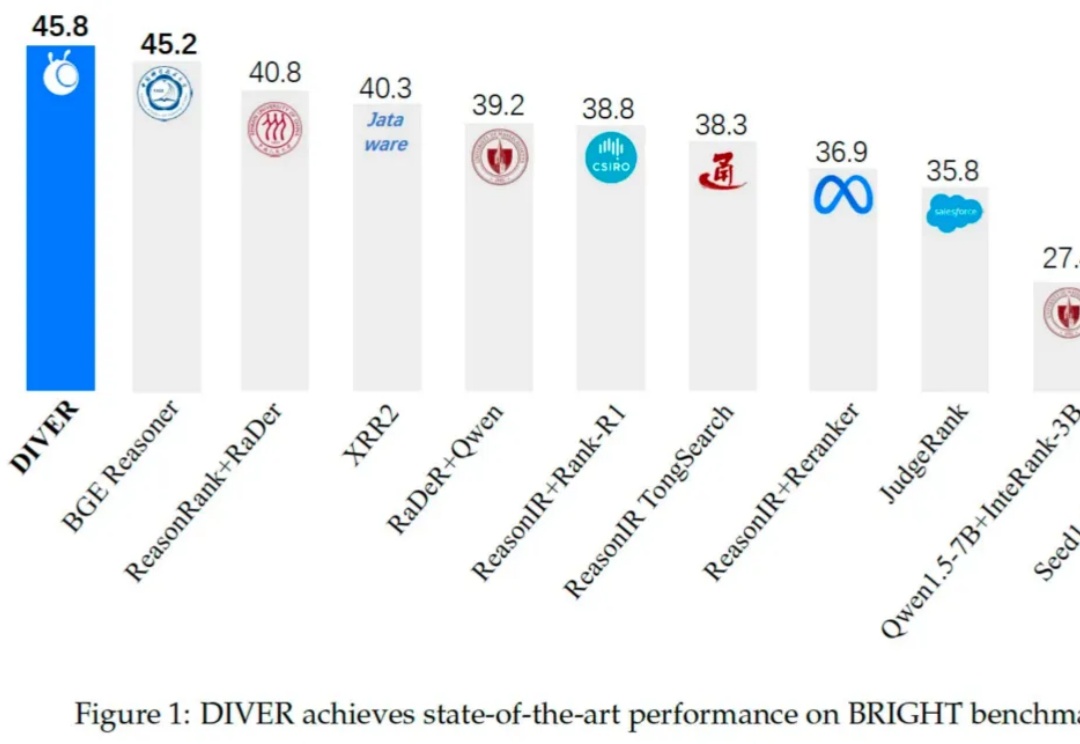
在当前由大语言模型(LLM)驱动的技术范式中,检索增强生成(RAG)已成为提升模型知识能力与缓解「幻觉」的核心技术。然而,现有 RAG 系统在面对需多步逻辑推理任务时仍存在显著局限,具体挑战如下:
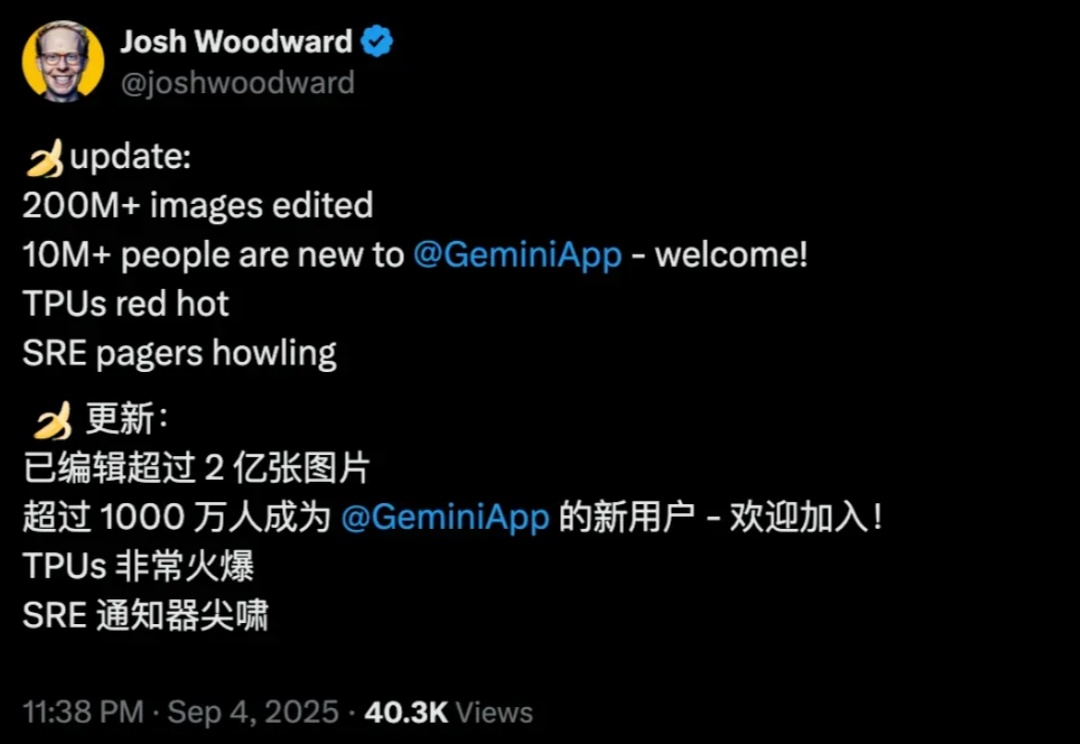
最近,朋友圈和抖音小红书几乎被 Nano Banana 刷屏了。这个香蕉模型似乎要让 P 图这个词消失,直接给 Gemini 带来了一千万的新用户,火得一塌糊涂。
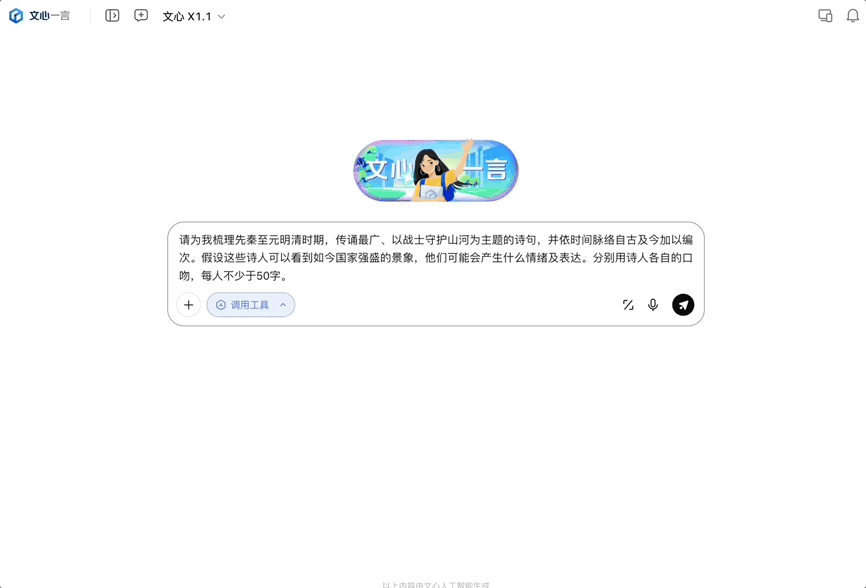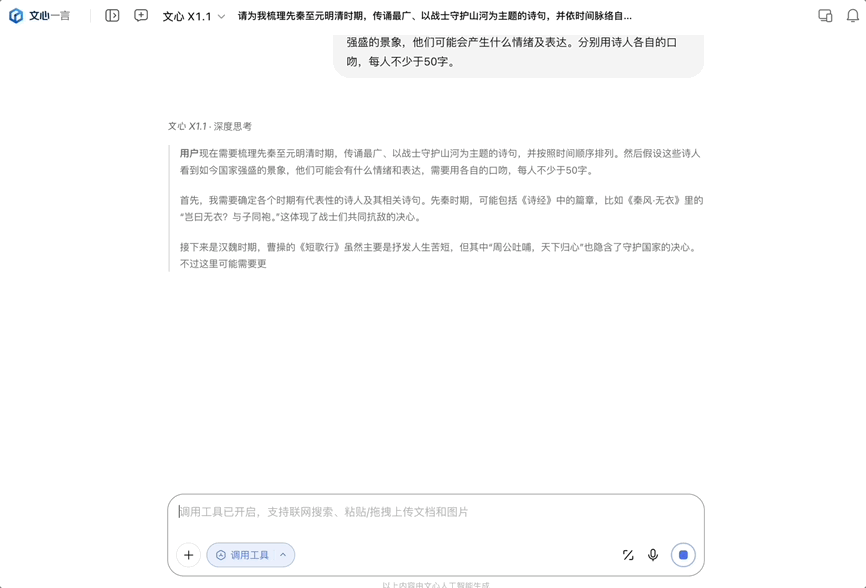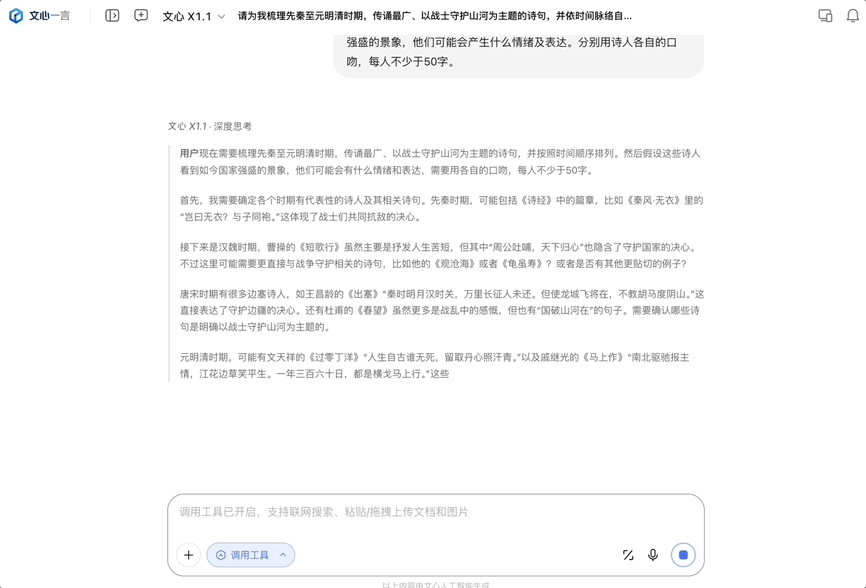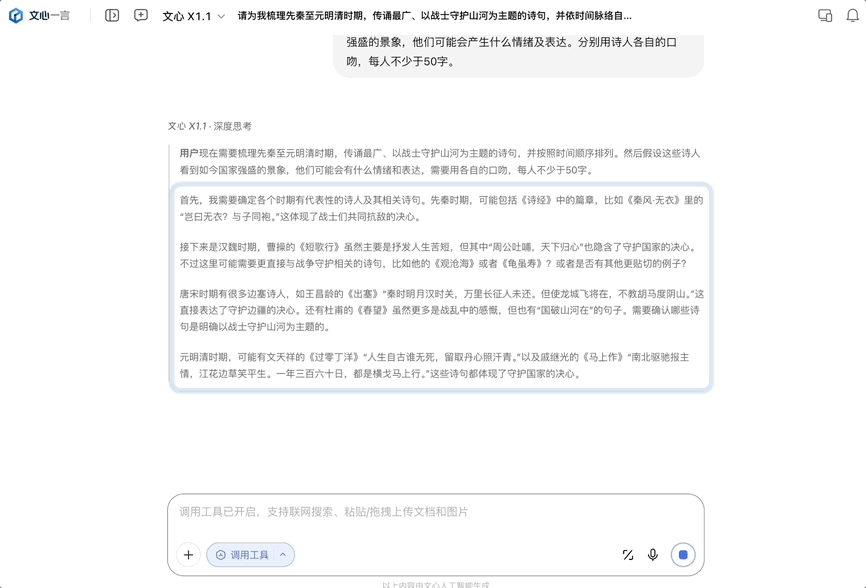
今天发布的是文心大模型 X1.1 深度思考模型,它是百度在 4 月份发布的旗舰模型 X1 的升级版,发布即上线,所有人都可以免费体验。同时该模型通过百度智能云千帆平台向企业客户与开发者开放使用。
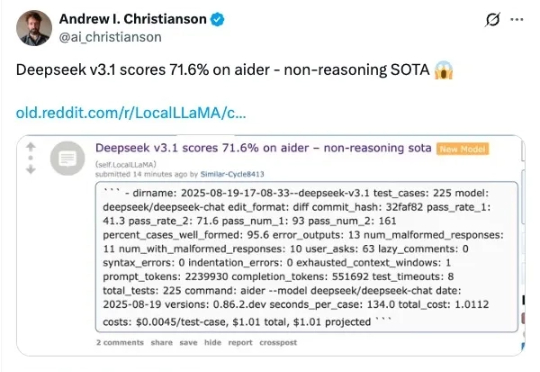
AI 编程工具的竞争已经进入深水区:不仅各家产品在补全速度、上下文感知、智能体协作上不断拉锯,在背后的模型层面,博弈同样激烈,甚至出现了全球范围的“准入门槛”和“封锁线”。这意味着工具之争早已不是单纯的产品对比,而是与模型生态、合规和市场战略深度绑定。
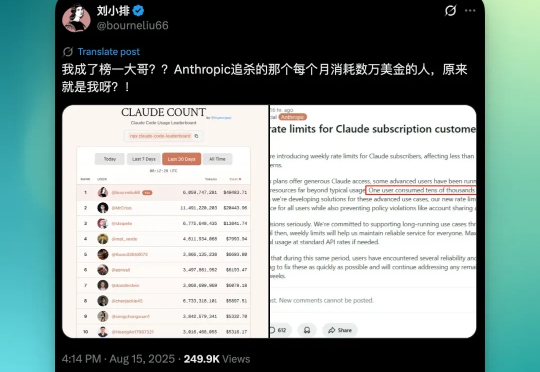
故事是这样的,两周前,Anthropic 上周发布一个公告:他们的工程师在后台数据中发现了一个异常账户,正在以一种不可思议的速度,7x24 小时消耗着 Claude 模型的算力。公告中提到:”有一位用户,在每月200美元的套餐中,消耗了价值 5 万美元的模型使用量。“ 这个消耗量大到,Anthropic 不得不公开发布声明调整全球用户的速率限制。

刚刚,火山引擎上线了豆包・图像创作模型 Seedream 4.0,我提前试了一下,应该各位也看到了各种非常强的玩法和图片。 简单来说就是一个支持图片生成、连续图片编辑、多图参考的全能图像创作模型。