
「马嘉祺」让大模型翻车,而他一年前洗澡时就发现了问题
「马嘉祺」让大模型翻车,而他一年前洗澡时就发现了问题一家名为脸谱心智(FaceMind)的初创公司就在顶级学术会议 EMNLP 主会上系统性地揭示了这个问题,并给出了解法。更有意思的是,就在「马嘉祺」事件前不到两周,全球最强 AI 公司之一 Anthropic 也在自家产品中悄悄落地了一次高度相关的改造 —— 方向与脸谱心智一年前的论文几乎完全一致。
来自主题: AI技术研报
7574 点击 2026-05-30 10:05
 搜索
搜索
一家名为脸谱心智(FaceMind)的初创公司就在顶级学术会议 EMNLP 主会上系统性地揭示了这个问题,并给出了解法。更有意思的是,就在「马嘉祺」事件前不到两周,全球最强 AI 公司之一 Anthropic 也在自家产品中悄悄落地了一次高度相关的改造 —— 方向与脸谱心智一年前的论文几乎完全一致。

所有人都在比谁的模型参数更大,但真正决定AI能不能落地的,其实是另一件没那么性感的事:一颗Token,能不能被稳定、便宜、规模化地生产出来。死磕这件事的,是一支从中国超级计算体系里走出来的年轻团队,是石科技。

Google DeepMind研究院姚顺宇最近接受媒体人采访时说:做一个好的产品经理,是一个我现在想不明白该怎么训练AI去做的事。言外之意,AI时代产品经理很难被替代。招聘市场已经给出了答案。根据脉脉2026年1—4月的数据,热招岗位里大模型算法排第一,产品经理排第二,AI产品经理也排到了前五的位置。
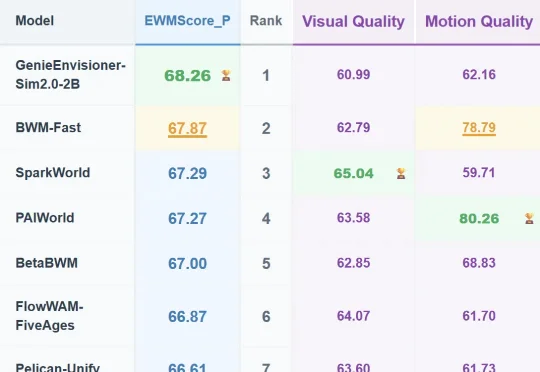
WorldArena 世界模型赛道从来都是竞争异常激烈,在经历了前几次比赛过程中的放榜之后,CVPR 2026 WorldArena 世界模型赛道锁定总成绩,智元自研的世界模型 Genie Envisioner-Sim 2.0(以下简称 GE 2.0)拿下了最终的冠军,成为了 “强者中的强者”。

继 Step 3.5 Flash 后,阶跃星辰最近又推出新一代高效率 Flash 开源模型 ——Step 3.7 Flash。该模型最大特点就是多(模)、快(速)、好(用)、省(钱)。总参数 196B,采用稀疏 MoE 架构,推理激活参数仅 11B,配备 1.88B ViT 视觉编码器,推理速度最高 400 TPS,支持 256K 上下文。
近日,字节旗下AI视频创作工具小云雀的短剧Agent正式更新到2.0版本。自Seedance 2.0这一视频生成模型横空出世以来,小云雀一直是其原生支持的平台。由于整体使用门槛相对较低,小云雀也逐渐积累起一批AI短剧和AI短片创作者。
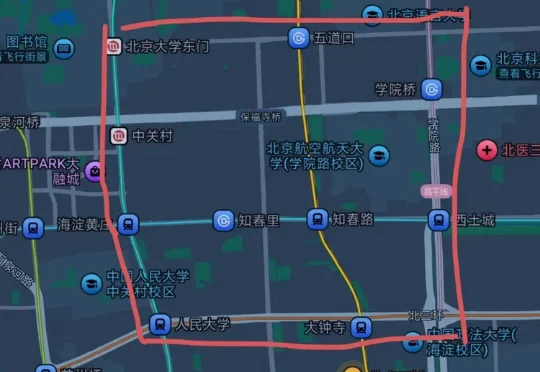
王慧文画的框像是一个聚宝盆,汇集了各方资本的关注。而太平洋另一边的旧金山,上演了类似的财富故事。这些数字给人震撼,但更有意思的问题是,模型可以云端训练,团队可以全球分布,远程办公早已成熟,但AI时代,反倒是更小的框里涌入了更巨量的财富

刚刚,自变量机器人团队带来全新解法——发布全球首个「事件级预测」具身智能世界模型WALL-WM。WALL-WM把世界模型的预测单位从时间帧换成了语义事件:
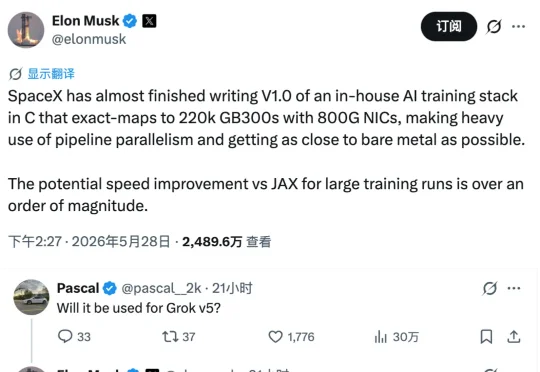
不用JAX,SpaceX正在用C语言编写的全新堆栈训练新模型。而且马斯克本人亲口承认,Grok 5已经用的就是这个新堆栈。按马斯克的说法,这种新堆栈能让大模型训练速度提升一个数量级。

近日,千寻智能高阳团队的研究成果 《Learning Native Continuation for Action Chunking Flow Policies》 被机器人顶会 RSS 2026 接收!这项工作从训练机制出发,让机器人动作天然具有连续性,实现了 "连音" 般的流畅执行,在五个真实世界操作任务上超越了现有方法,为具身智能领域的动作生成研究提供了新的思路。