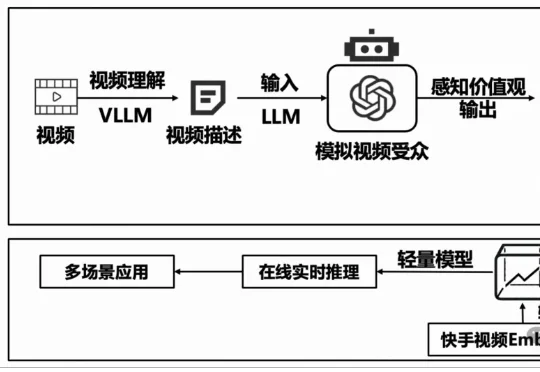
终于,清华快手养出了通人性的AI!
终于,清华快手养出了通人性的AI!清华大学经济管理学院的陈柯均博士生、张佳音教授、徐心教授与快手消费策略算法部合作探索完成了一项联合实验:从视频传递的价值观的角度,去理解观看视频后用户的行为和心理变化。
来自主题: AI技术研报
8441 点击 2026-05-31 11:15
 搜索
搜索
清华大学经济管理学院的陈柯均博士生、张佳音教授、徐心教授与快手消费策略算法部合作探索完成了一项联合实验:从视频传递的价值观的角度,去理解观看视频后用户的行为和心理变化。
今天,阿里云百炼核心能力已CLI化 ,仅需一行命令,即可让Agent自动接入阿里云百炼的150多款模型、十多款应用,以及知识库、记忆、联网搜索等全套能力。百炼CLI专为Agent设计,原生支持Clau
普通人看排行榜估计越看越疑惑,写文章该用哪个?数据分析该用哪个?写代码、审 PR、拆任务又该用哪个?我挑了四款最近讨论度很高的模型:Claude Opus 4.8、Gemini 3.5 Flash、GPT-5.5、Qwen3.7-Max,做一次横评,看看它们在真实任务里的交付表现。

5 月下旬,NVIDIA 联合清华大学、多伦多大学和 Vector Institute 发布 Gamma-World,共一第一为清华大学电子系博士刘芳甫,核心 Research 方向是世界模型和空间智能。

证监会官网显示,上海AI大模型龙头企业MiniMax已于5月29日向上海证监局提交了上市辅导备案报告,开启A股上市进程,中信证券担任辅导机构。这也意味着,MiniMax将与已经提交A股上市辅导备案的智谱,一同冲刺A股大模型第一股。

绝大多数 AI 陪伴产品,都是基于通用模型的使用,利用提示词框架对模型进行定向约束,所以角色的表达仍然停留在「人类平均水平」,本质都是提示词驱动下的角色扮演。但陆弘毅做蕾伊的方法完全不同。团队先为她写了几十万字的人格语料,确定她从小到大的经历、行为与反应、深层性格和内在冲突,再把这些只属于蕾伊的数据灌进他们自研的「超人格化模型」。
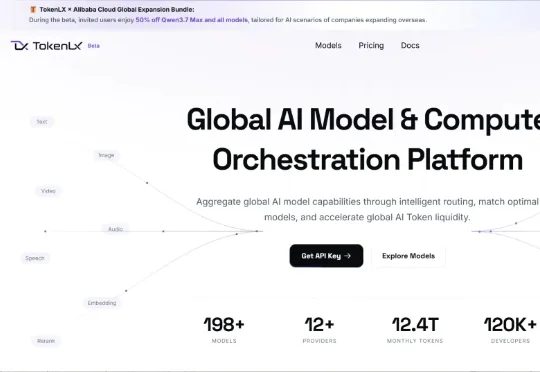
最近和几个做 AI 出海的朋友聊天,大家已经很少去聊哪个模型又刷了榜。谈论最多的,是哪个模型调度平台好用、实惠、安全。 这话题我是一点都不意外。毕竟前不久全球大佬都在扎堆往 AI 这个方向挤。老话说得

昨天,大名鼎鼎的 Claude 4.8 发布了。 科技圈照例是一片欢呼。 看官方放出来的一堆评测数据,依然是碾压级别的,尤其是说代码(Coding)能力有了史诗级的提升,简直像交了一份满分答卷。
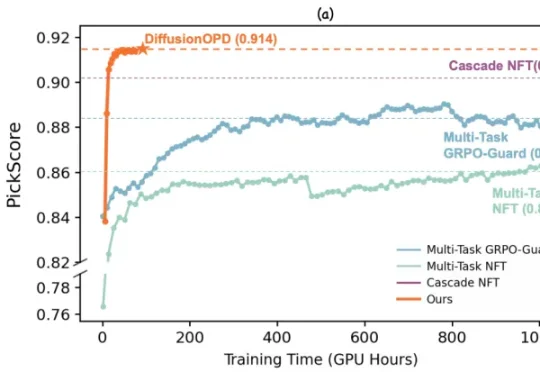
近期,来自复旦大学与阿里巴巴通义万相的研究团队对此提出了新的思考。他们认为,多任务强化学习不应被视为一个统一优化问题,而应该解耦为两个彼此独立的过程:单任务的在线策略探索 & 多任务能力整合。
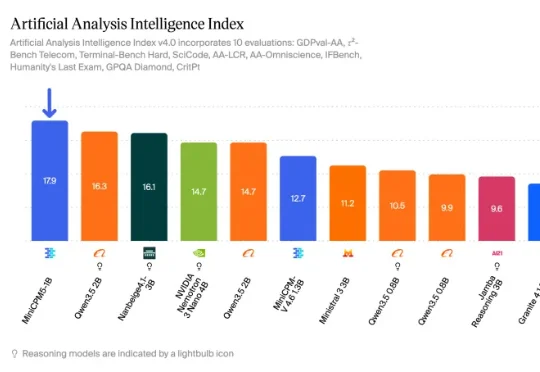
我去搜了下 MiniCPM5-1B 的数据,发现面壁智能刚刚把背后的核心数据集给开源了。一共是两份 L3 级数据集:Ultra-FineWeb-L3 :600B tokens,中英文都有,是目前最大的中文开源合成预训练数据集。