

只因一个“:”,大模型全军覆没
只因一个“:”,大模型全军覆没一个冒号,竟然让大模型集体翻车?
来自主题: AI技术研报
7819 点击 2025-07-16 10:45
一个冒号,竟然让大模型集体翻车?
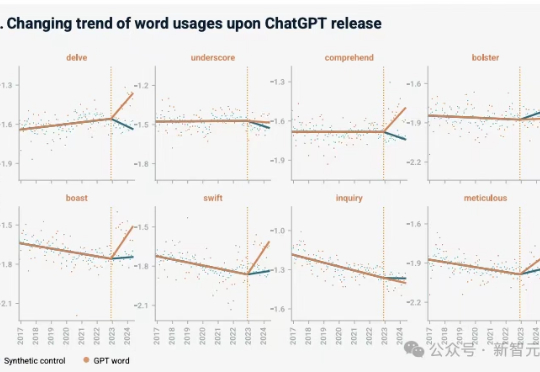
你以为你在掌控AI,其实是AI在驯化你!最新研究警告:ChatGPT正改变英语的表达方式,悄然植入自己的偏好。是时候重新审视,我们到底在表达自我,还是AI的「复读机」?

MIRIX,一个由 UCSD 和 NYU 团队主导的新系统,正在重新定义 AI 的记忆格局。

上周五(711),月之暗面蛰伏半年,憋了个大的,正式发布Kimi K2模型,总参数1T,同步开源。具体模型效果就不过多赘述了,网上已经有很多实测。
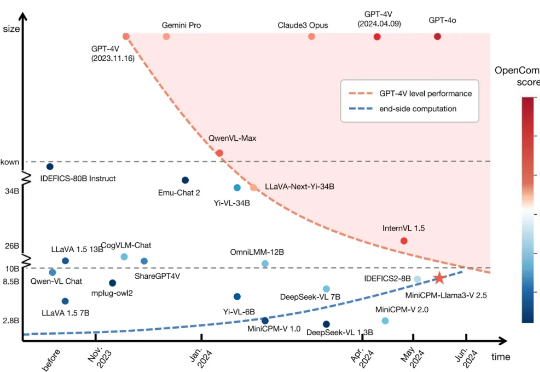
7 月 1 日,国际顶级学术期刊《Nature》旗下子刊《Nature Communications》正式刊登了来自清华、面壁等研究团队联合研发的高效端侧多模态大模型MiniCPM-V 核心研究成果。

我们正经历一场前所未有的智能跃迁。人工智能带来的,远不止于技术革新,更是一场深刻重塑人类认知、教育与生存方式的范式转移。
你说:“帮我列下今天的会议日程。” 它迅速回复:“9 点产品部,11 点市场部,下午 2 点财务汇报。”——完美。
今天凌晨,马斯克突然通知大家:快来更新 Grok APP,出新功能了。新推出的功能名为「智能伴侣」,基于前几天刚推出的 Grok 4 大模型,可以和人们实现自然的交互。大家一看这个效果,讨论的热度比前几天新模型发布还大。
「造芯」不易,「用芯」更难。大模型加速落地,国产芯片需求日盛,但模型真正能在国产芯上「开箱即用」者寥寥无几——这关键的「最后一公里」,谁来铺路?
大家好,我是袋鼠帝 上周五kimi开源了他们最新最强的旗舰模型K2https://github.com/MoonshotAI/Kimi-K2。K2这几天很多博主都写过了,确实很强,如果能搭配世界最强AI编程神器Claude Code,那不得起飞啊!