
腾讯混元最新开源:一套RL框架打通多个模态,庞天宇团队新作
腾讯混元最新开源:一套RL框架打通多个模态,庞天宇团队新作大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。
来自主题: AI技术研报
6890 点击 2026-06-18 11:25
 搜索
搜索
大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。
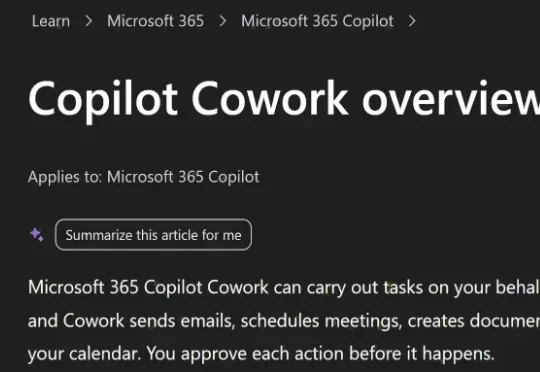
当地时间6月16日,微软宣布将企业AI工具Copilot Cowork转向按使用量计费。另据外媒Axios报道,在扩大该工具访问范围的同时,Copilot Cowork近期考虑引入由微软托管的DeepSeek模型,作为更低成本的模型选项。

新一代具身基础模型G0.5和首款双足人形机器人Kengo亮相不到半个月,星海图又整活儿了。
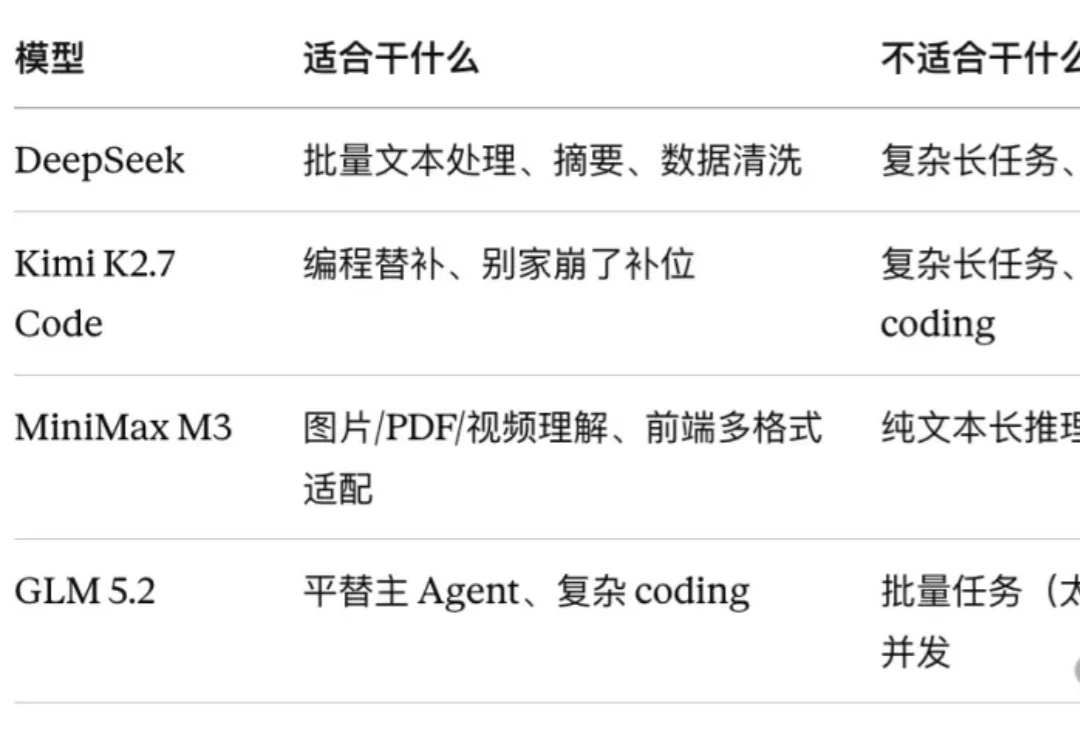
最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。

刚刚过去的2026智源大会上,由智源研究院孵化的星源智发布了全球首个具身交互世界模型ω-EVA,就这一前沿命题给出了全新的差异化解法。传统世界模型的困境是"只预测,不参与"。它们训练时学习未来状态,推理时却与动作生成分割——视频生成得再精美,机器人该撞墙还是撞墙。

物理AI基础设施公司章鱼动力(SynapX)近日已完成新一轮5000万美元融资。结合此前两轮5000万美元的连续融资,章鱼动力在过去3个月内已累计完成接近10亿元人民币的融资。
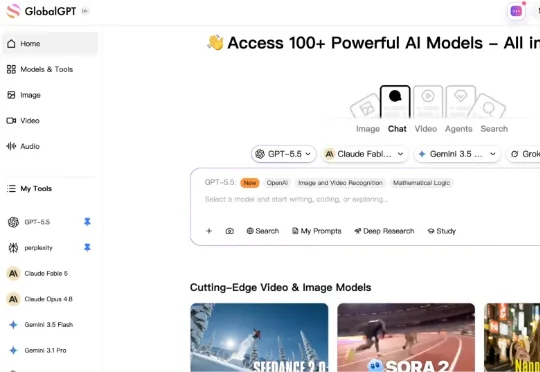
GlobalGPT 是一款很典型的 AI 套壳产品,一份订阅访问市面上几乎所有主流 AI 模型,目前全球累计用户超过 300 万,ARR 做到 1000 万美金。创始人李焕之,律师出身,2022 年开始连续创业,经历了 LegalDAO(Web3 法律社区)、LegalNow(AI 法律产品)的两次pivot后,在 2024 年初团队现金流只剩 1 个月时做出了 GlobalGPT。
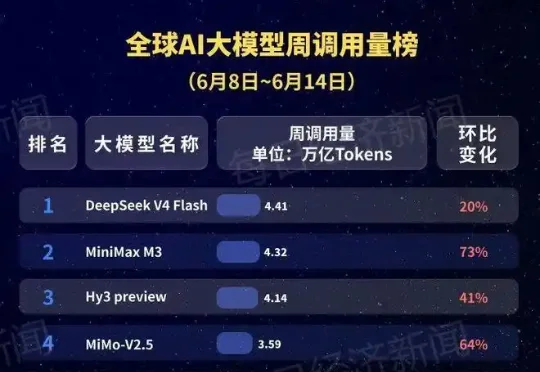
根据OpenRouter最新数据测算,上周(6月8日至14日)全球AI大模型总调用量为44.6万亿Token,较此前一周增长23.5%,连续八周上涨,大模型调用需求仍在持续释放。
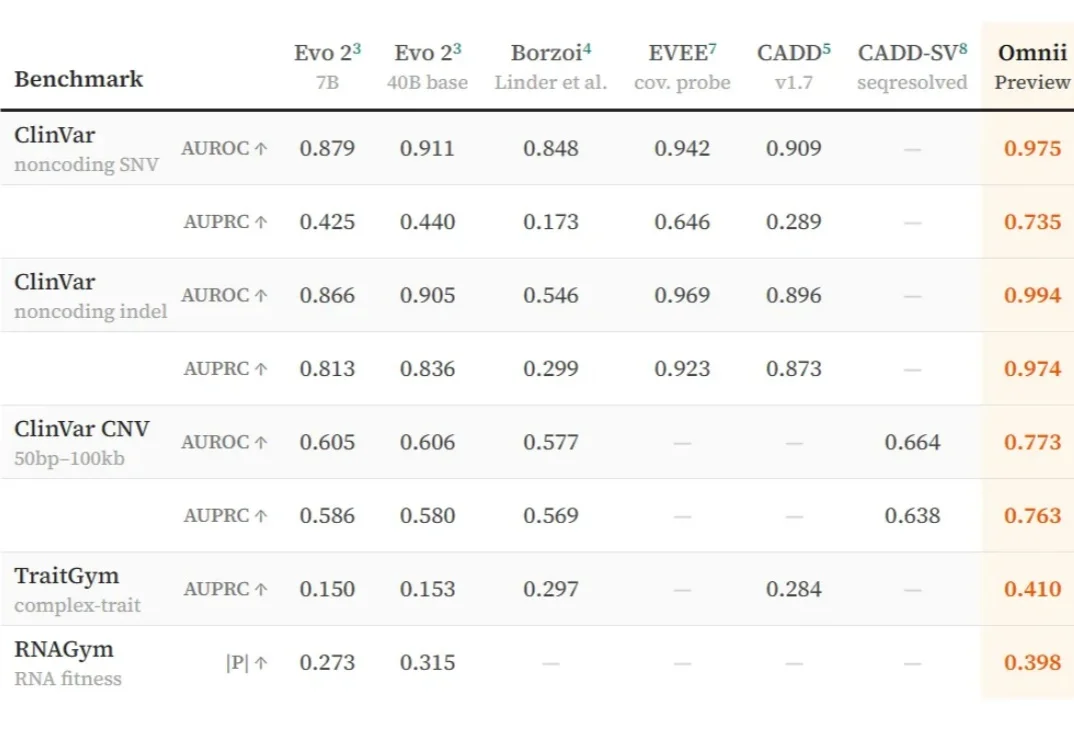
最大生物学AI模型Evo2的幕后团队,要把所有生物信息整合到一套AI里!

被算力荒逼出来的硬核奇迹!腾讯米哈游老兵组成的「草根」团队,硬在国产芯片上炼出了超10分钟的绝对物理一致性。画面可以糙,物理绝不能假,这就是通往AGI的真正基石。