英伟达开源发布最新AI模型!引入突破性专家混合架构,推理性能超越Qwen3和GPT,百万token上下文,模型数据集全开源!
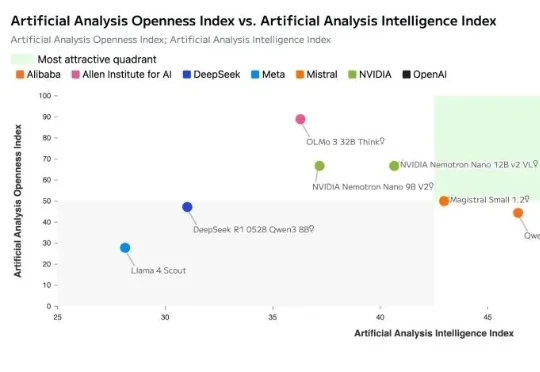
英伟达开源发布最新AI模型!引入突破性专家混合架构,推理性能超越Qwen3和GPT,百万token上下文,模型数据集全开源!就在刚刚,英伟达正式开源发布了其新一代AI模型:NVIDIA Nemotron 3。Nemotron 3 系列由三种型号组成:Nano、Super 和 Ultra。官方介绍其具备强大的智能体、推理和对话能力。
来自主题: AI技术研报
10472 点击 2025-12-16 17:21