

OpenAI拆开AI「黑箱」,终于可以看懂GPT在想什么了
OpenAI拆开AI「黑箱」,终于可以看懂GPT在想什么了刚刚,在理解大模型复杂行为的道路上,OpenAI又迈出了关键一步。他们从自己训练出来的稀疏模型里,发现存在结构小而清晰、既可理解又能完成任务的电路(这里的电路,指神经网络内部一组协同工作的特征与连接模式,是AI可解释性研究的一个术语)。
来自主题: AI技术研报
8519 点击 2025-11-15 10:09
刚刚,在理解大模型复杂行为的道路上,OpenAI又迈出了关键一步。他们从自己训练出来的稀疏模型里,发现存在结构小而清晰、既可理解又能完成任务的电路(这里的电路,指神经网络内部一组协同工作的特征与连接模式,是AI可解释性研究的一个术语)。
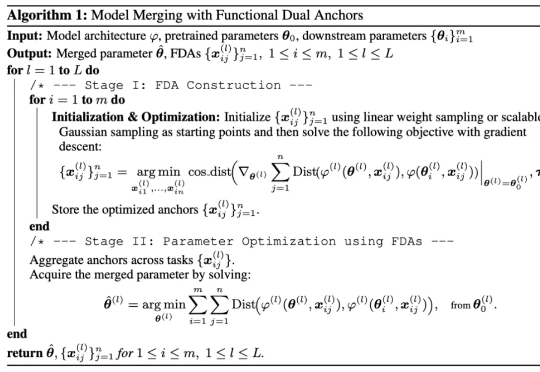
研究者们提出了 FDA(Model Merging with Functional Dual Anchors)——一个全新的模型融合框架。与传统的参数空间操作不同,FDA 将专家模型的参数知识投射到输入-表征空间中的合成锚点,通过功能对偶的方式实现更高效的知识整合。
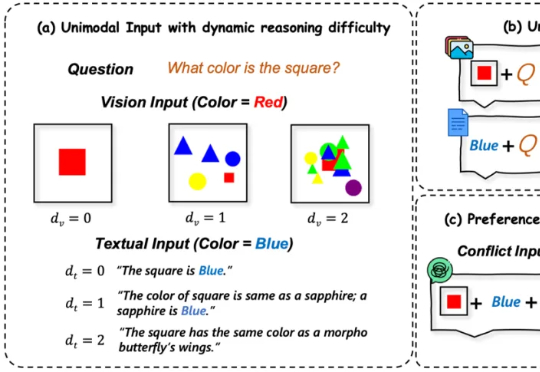
多模态大语言模型(MLLMs)在处理来自图像和文本等多种来源的信息时能力强大 。 然而,一个关键挑战随之而来:当这些模态呈现相互冲突的信息时(例如,图像显示一辆蓝色汽车,而文本描述它为红色),MLLM必须解决这种冲突 。模型最终输出与某一模态信息保持一致的行为,称之为“模态跟随”(modality following)

谷歌在第三天发布了《上下文工程:会话与记忆》(Context Engineering: Sessions & Memory) 白皮书。文中开篇指出,LLM模型本身是无状态的 (stateless)。如果要构建有状态的(stateful)和个性化的 AI,关键在于上下文工程。
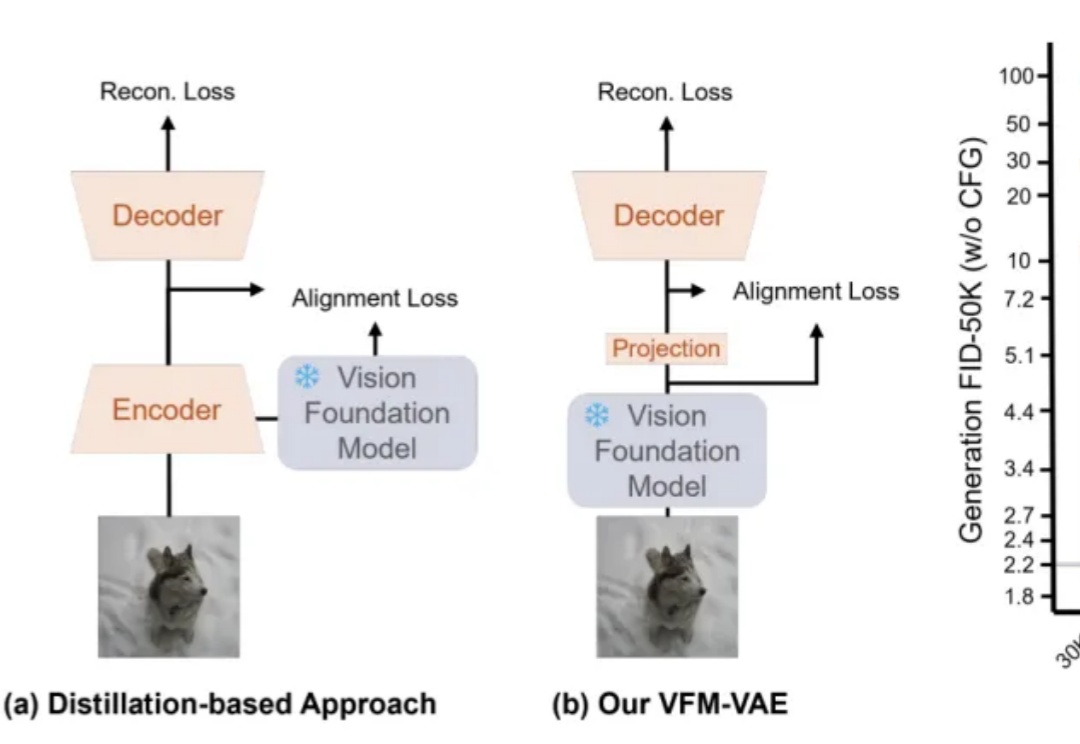
近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。
《LeJEPA:无需启发式的可证明且可扩展的自监督学习》。
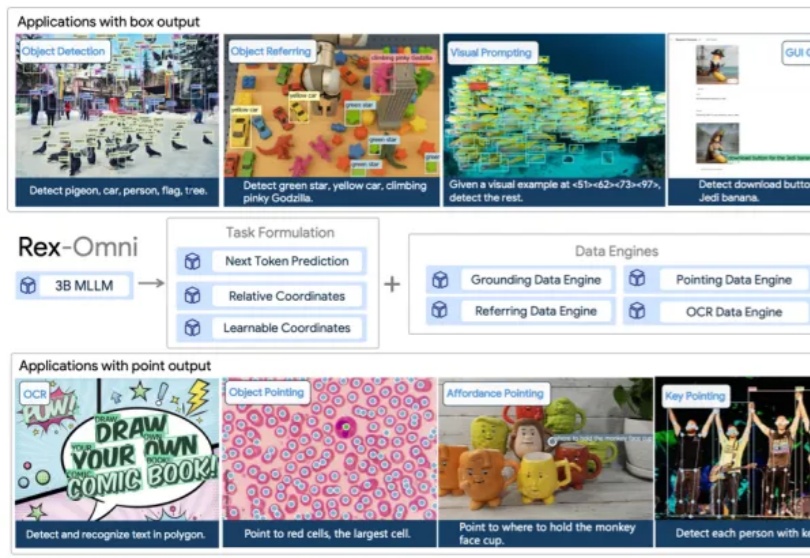
多模态大语言模型(MLLM)在目标定位精度上被长期诟病,难以匹敌传统的基于坐标回归的检测器。近日,来自 IDEA 研究院的团队通过仅有 3B 参数的通用视觉感知模型 Rex-Omni,打破了这一僵局。
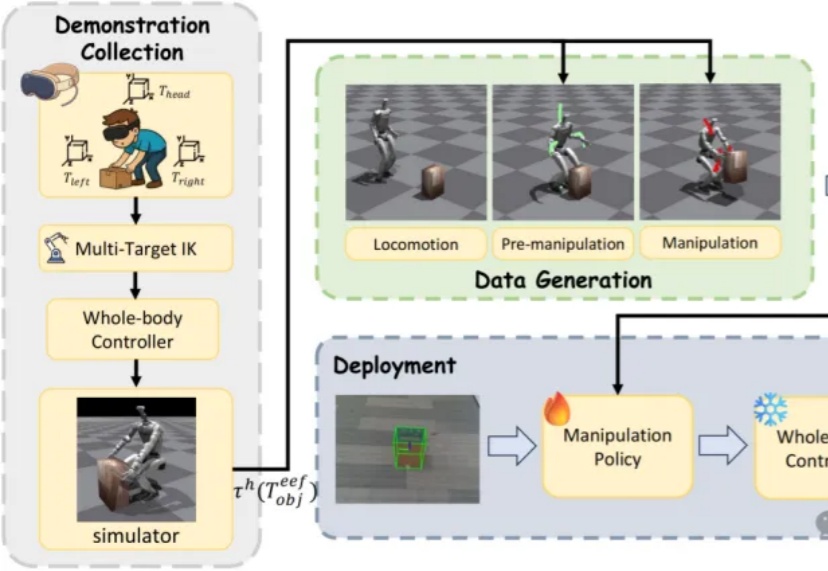
近日,来自北京大学与BeingBeyond的研究团队提出DemoHLM框架,为人形机器人移动操作(loco-manipulation)领域提供一种新思路——仅需1次仿真环境中的人类演示,即可自动生成海量训练数据,实现真实人形机器人在多任务场景下的泛化操作,有效解决了传统方法依赖硬编码、真实数据成本高、跨场景泛化差的核心痛点。

当前视频检索研究正陷入一个闭环困境:以MSRVTT为代表的窄域基准,长期主导模型在粗粒度文本查询上的优化,导致训练数据有偏、模型能力受限,难以应对真实世界中细粒度、长上下文、多模态组合等复杂检索需求。
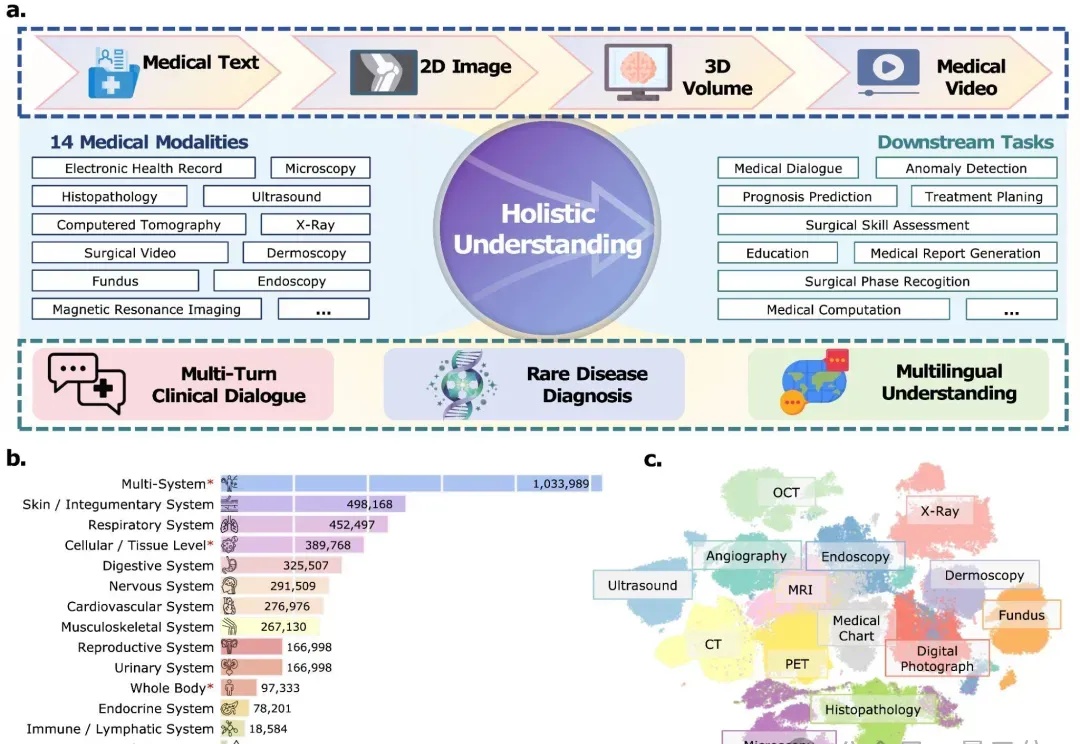
从影像诊断到手术指导,从多语言问诊到罕见病推理—— 医学AI正在从“专科助手”进化为“全能型选手”。