
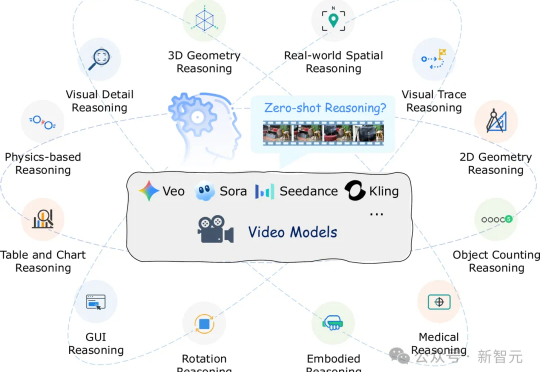
视频模型假装在推理?MME-CoF新基准评估12个推理维度
视频模型假装在推理?MME-CoF新基准评估12个推理维度视频生成模型如Veo-3能生成逼真视频,但有研究发现其推理能力存疑。香港中文大学、北京大学、东北大学的研究者们设计了12项测试,发现模型只能模仿表面模式,未真正理解因果。这项研究为视频模型推理能力评估提供基准,指明未来研究方向。
来自主题: AI技术研报
7740 点击 2025-11-08 11:16
视频生成模型如Veo-3能生成逼真视频,但有研究发现其推理能力存疑。香港中文大学、北京大学、东北大学的研究者们设计了12项测试,发现模型只能模仿表面模式,未真正理解因果。这项研究为视频模型推理能力评估提供基准,指明未来研究方向。

智源研究院(BAAI)、Spin Matrix、乐聚机器人与新加坡南洋理工大学等联合提出了一个全新的终身记忆系统——RoboBrain-Memory。RoboBrain-Memory是全球范围内首个专为全双工、全模态模型设计的终身记忆系统,旨在解决具身智能体在真实世界的复杂交互问题,不仅支持实时音视频中多用户身份识别与关系理解,还能动态维护个体档案与社会关系图谱,从而实现类人的长期个性化交互。
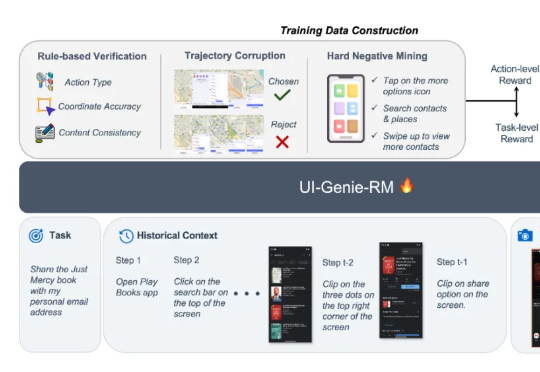
本文来自于香港中文大学 MMLab 和 vivo AI Lab,其中论文第一作者肖涵,主要研究方向为多模态大模型和智能体学习,合作作者王国志,研究方向为多模态大模型和 Agent 强化学习。项目 le
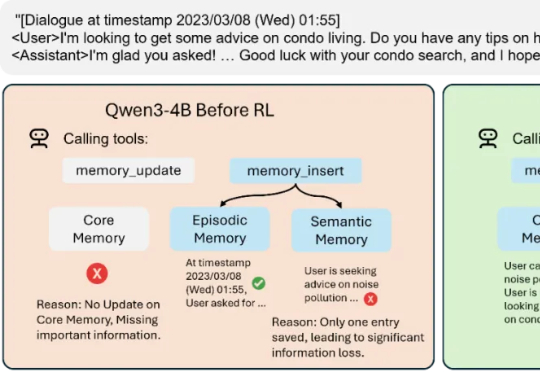
Mem-α 的出现,正是为了解决这一困境。由加州大学圣地亚哥分校的 Yu Wang 在 Anuttacon 实习期间完成,这项工作是首次将强化学习引入大模型的记忆管理体系,让模型能够自主学习如何使用工具去存储、更新和组织记忆。

两人小团队,仅用两周就复刻了之前被硅谷夸疯的DeepSeek-OCR?? 复刻版名叫DeepOCR,还原了原版低token高压缩的核心优势,还在关键任务上追上了原版的表现。完全开源,而且无需依赖大规模的算力集群,在两张H200上就能完成训练。
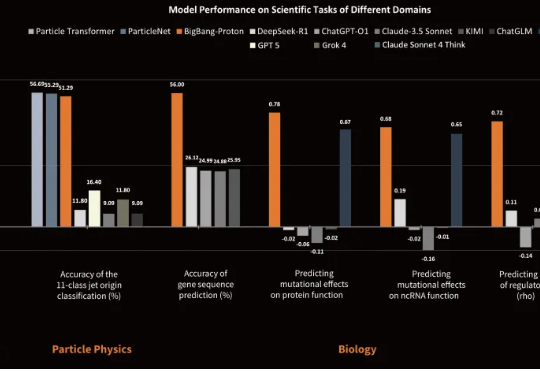
近日,专注于研发物质世界基座模型的公司超越对称(上海)技术有限公司(超对称)发布了新版基座模型 BigBang-Proton,成功实现多个真实世界的专业学科问题与 LLM 的统一预训练和推理,挑战了 Sam Altman 和主流的 AGI 技术路线。
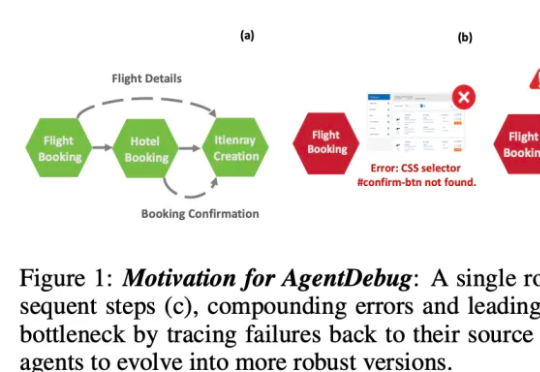
伊利诺伊大学厄巴纳 - 香槟分校(UIUC)等团队近日发布论文,系统性剖析了 LLM 智能体失败的机制,并提出了可自我修复的创新框架 ——AgentDebug。该研究认为,AI 智能体应成为自身的观察者和调试者,不仅仅是被动的任务执行者,为未来大规模智能体的可靠运行和自动进化提供了理论与实践工具。

目前,最先进的对齐方法是使用知识蒸馏(Knowledge Distillation, KD)在所有 token 上最小化 KL 散度。然而,最小化全局 KL 散度并不意味着 token 的接受率最大化。由于小模型容量受限,草稿模型往往难以完整吸收目标模型的知识,导致直接使用蒸馏方法的性能提升受限。在极限场景下,草稿模型和目标模型的巨大尺寸差异甚至可能导致训练不收敛。
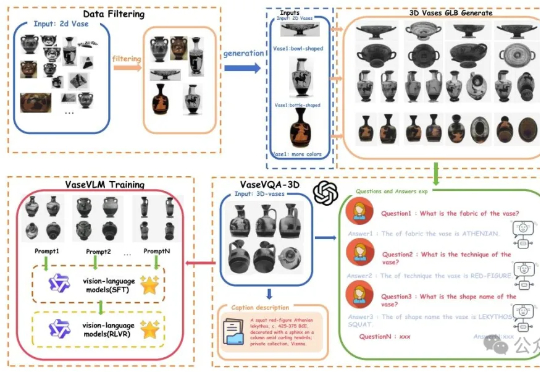
现在AI都懂文物懂历史了。一项来自北京大学的最新研究引发关注:他们推出了全球首个面向古希腊陶罐的3D视觉问答数据集——VaseVQA-3D,并配套推出了专用视觉语言模型VaseVLM。这意味着,AI正在从“识图机器”迈向“文化考古Agent”。

大型语言模型(LLMs)正迅速成为从金融到交通等各个专业领域不可或缺的辅助决策工具。但目前LLM的“通用智能”在面对高度专业化、高风险的任务时,往往显得力不从心。