
DeepMind再登Nature:AI Agent造出了最强RL算法!
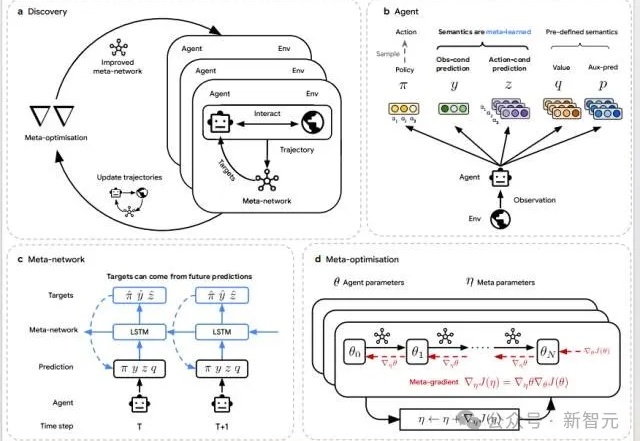
DeepMind再登Nature:AI Agent造出了最强RL算法!当AI开始「自己学会学习」,人类的角色正在被重写。DeepMind最新研究DiscoRL,让智能体在多环境交互中自主发现强化学习规则——无需人类设计算法。它在Atari基准中击败MuZero,在从未见过的游戏中依旧稳定高效。
来自主题: AI技术研报
10274 点击 2025-10-28 14:56
当AI开始「自己学会学习」,人类的角色正在被重写。DeepMind最新研究DiscoRL,让智能体在多环境交互中自主发现强化学习规则——无需人类设计算法。它在Atari基准中击败MuZero,在从未见过的游戏中依旧稳定高效。
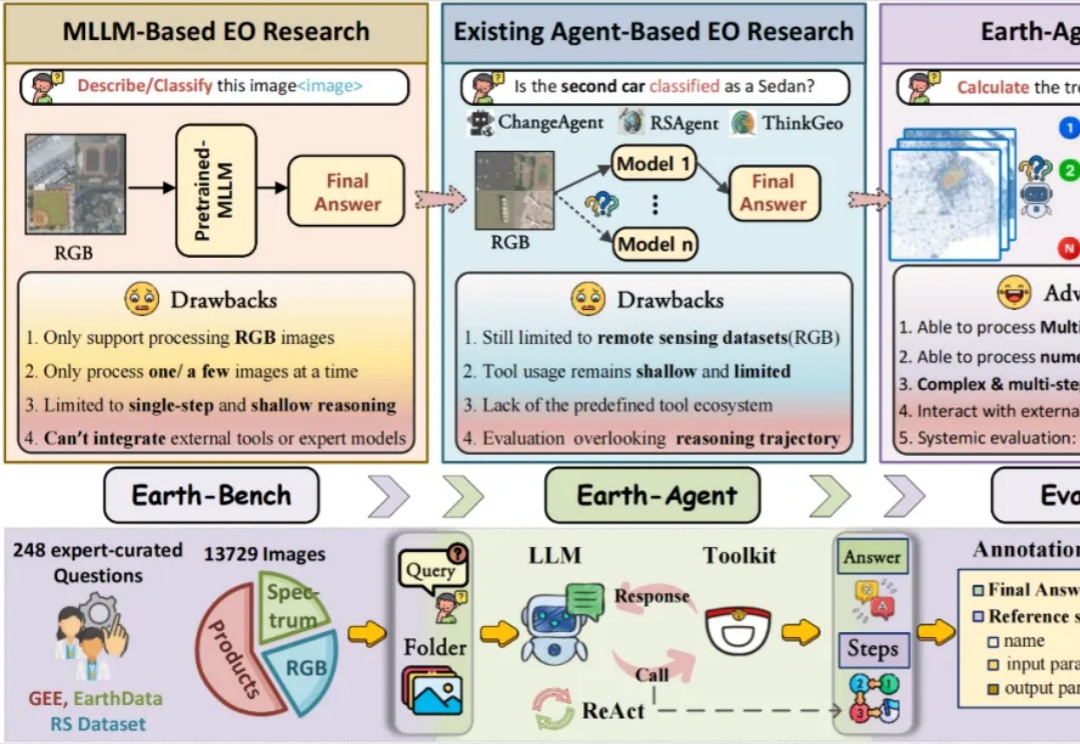
当强大的多模态大语言模型应用于地球科学研究时,它面临着无法忽视的 「阿克琉斯之踵」

近期,DeepSeek-OCR提出了“Vision as Context Compression”的新思路,然而它主要研究的是通过模型的OCR能力,用图片压缩文档。

人眼秒懂,AI抓瞎!网友用光学错觉玩坏大模型,全网百万人围观。

能看懂相机参数,并且生成相应视角图片的多模态模型来了。
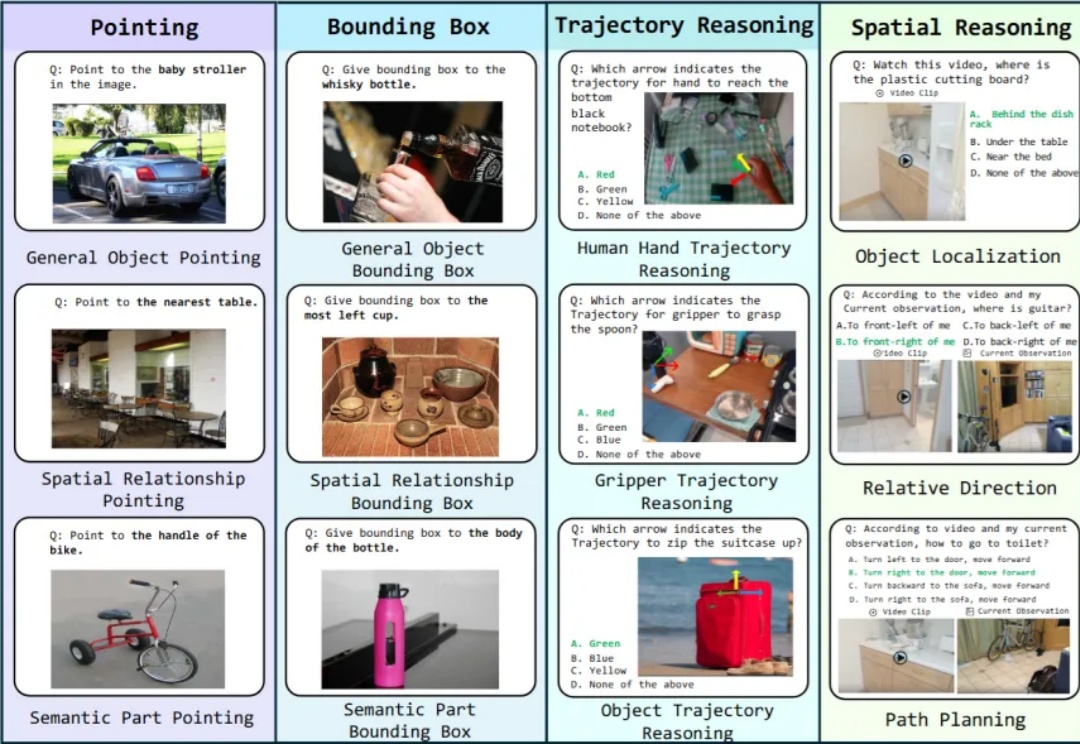
具身智能是近年来非常火概念。一个智能体(比如人)能够在环境中完成感知、理解与决策的闭环,并通过环境反馈不断进入新一轮循环,直至任务完成。这一过程往往依赖多种技能,涵盖了底层视觉对齐,空间感知,到上层决策的不同能力,这些能力便是广义上的具身智能。
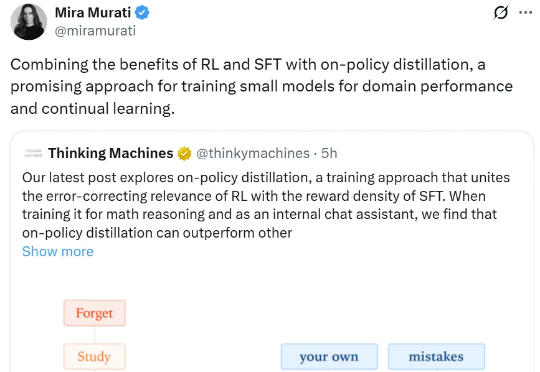
刚刚,不发论文、爱发博客的 Thinking Machines Lab (以下简称 TML)再次更新,发布了一篇题为《在策略蒸馏》的博客。在策略蒸馏(on-policy distillation)是一种将强化学习 (RL) 的纠错相关性与 SFT 的奖励密度相结合的训练方法。在将其用于数学推理和内部聊天助手时,TML 发现在策略蒸馏可以极低的成本超越其他方法。

预训练的核心是推动损失函数下降,这是我们一直追求的唯一目标。
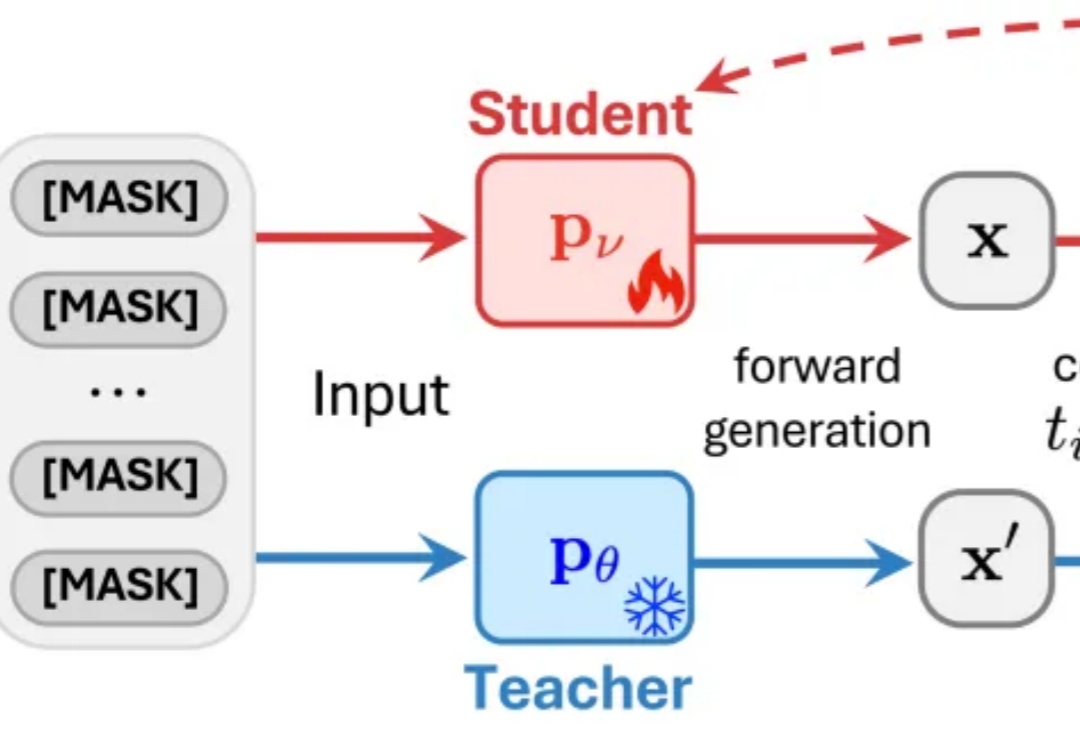
近日,来自普渡大学、德克萨斯大学、新加坡国立大学、摩根士丹利机器学习研究、小红书 hi-lab 的研究者联合提出了一种对离散扩散大语言模型的后训练方法 —— Discrete Diffusion Divergence Instruct (DiDi-Instruct)。经过 DiDi-Instruct 后训练的扩散大语言模型可以以 60 倍的加速超越传统的 GPT 模型和扩散大语言模型。

数据集蒸馏是一种用少量合成数据替代全量数据训练模型的技术,能让模型高效又节能。WMDD和GUARD两项研究分别解决了如何保留原始数据特性并提升模型对抗扰动能力的问题,使模型在少量数据上训练时既准确又可靠。