我们实测TRAE Work的这份攻略,被官方收进知识库了
我们实测TRAE Work的这份攻略,被官方收进知识库了上周我们发了一篇Agent大横评的文章三家评测,结果评论区出现了一个高频问题: “字节的TRAE Work建议测一下。”
来自主题: AI技术研报
9351 点击 2026-07-27 16:07
 搜索
搜索
上周我们发了一篇Agent大横评的文章三家评测,结果评论区出现了一个高频问题: “字节的TRAE Work建议测一下。”

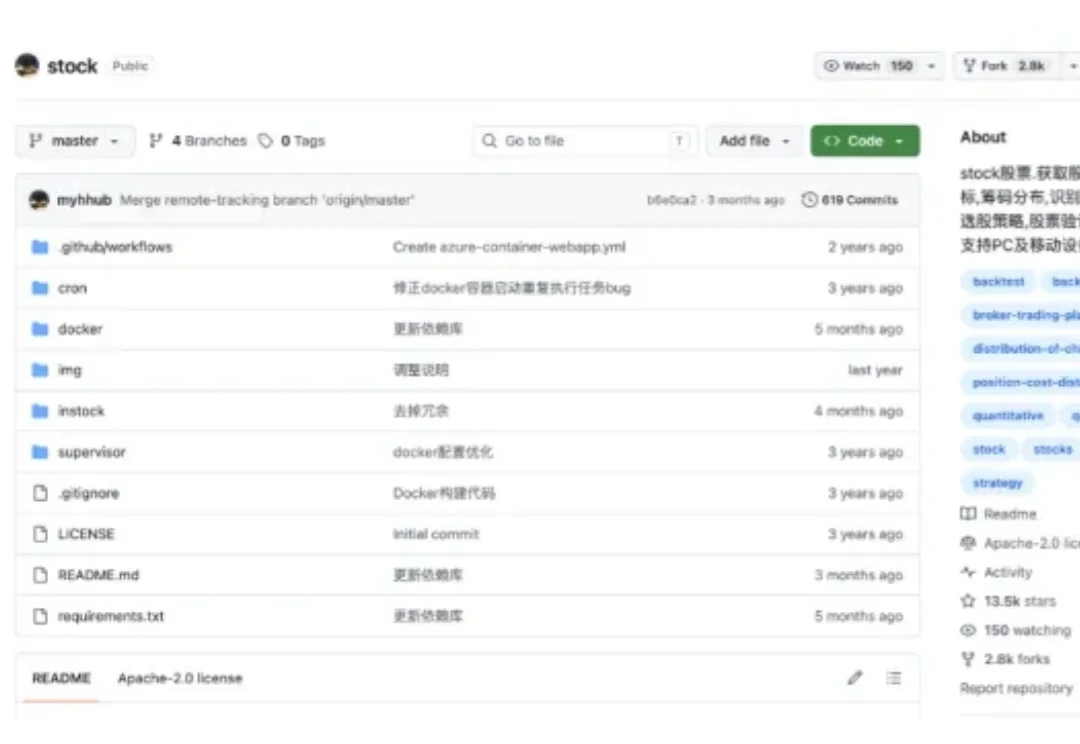
刚刚,字节也坐不住了,推出了 Trae Work 官方知识库教程。我让 Agent 查了下,这个知识库目前大约有 46w 字,85 篇文档。 不得不说,不愧是字节,写文档还是很有一手的!

知识第一次,能像代码一样利滚利。前OpenA 创始团队成员、特斯拉前 AI 高级总监 Andrej Karpathy,提出一个狠招:别再用 RAG 检索你的知识库,让大模型把它「编译」成一座持续生长的活 Wiki。两个多月,他在GitHub屠出 5000+ star。
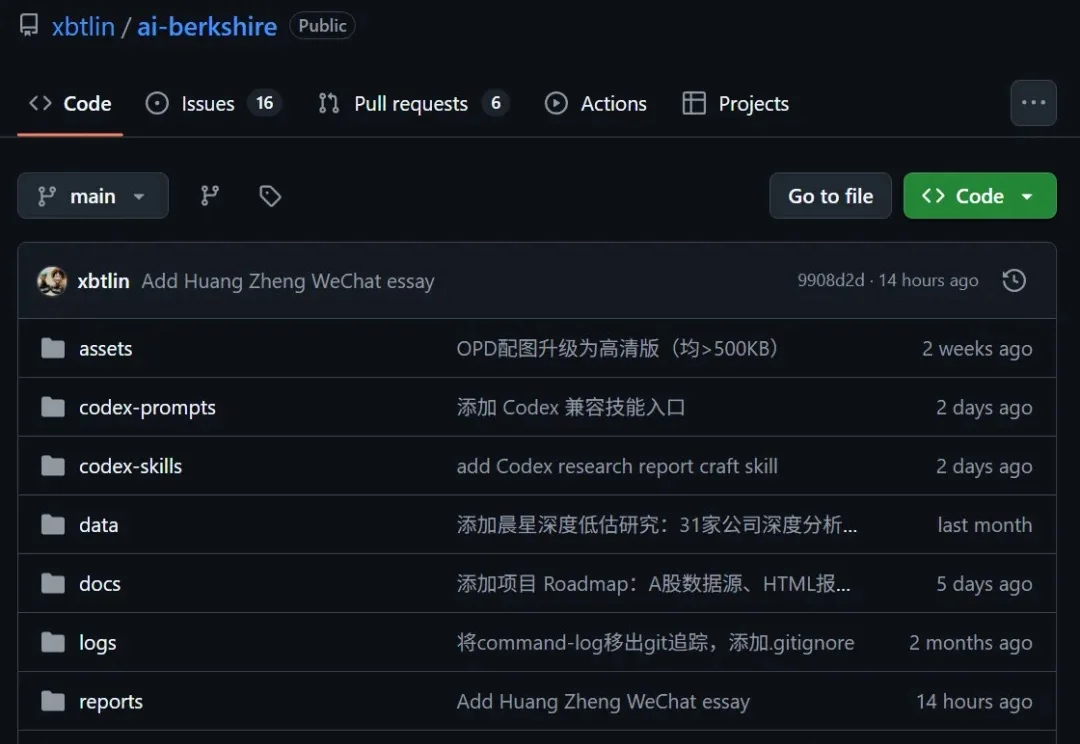
最近网上冲浪,刷到两个特别有意思的 GitHub 项目,分享给大家。

谷歌今天发布了一个叫 Open Knowledge Format(OKF)的开放规范。
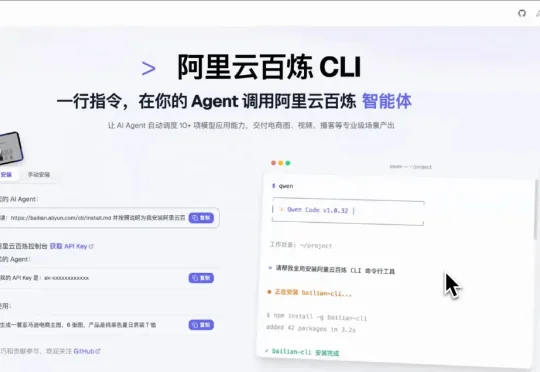
今天,阿里云百炼核心能力已CLI化 ,仅需一行命令,即可让Agent自动接入阿里云百炼的150多款模型、十多款应用,以及知识库、记忆、联网搜索等全套能力。百炼CLI专为Agent设计,原生支持Clau
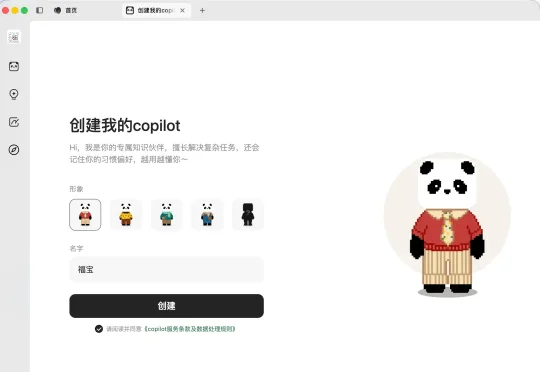
灰度一个月,这个数字让我们有点坐不住——它说明大家对"让AI用我的知识替我干活"这件事,等不及了。好消息是,从今天起,所有人打开 ima,都可以直接使用copilot。同时,ima知识号也开始能发布 Skill 了,知识广场从“内容平台”延伸为“能力平台”。

近日,有读者向《读佳》爆料:腾讯在测试一款知识库工具“狍子AI”,功能是帮助用户将微信收藏的公众号文章导入到专属的狍子知识库。
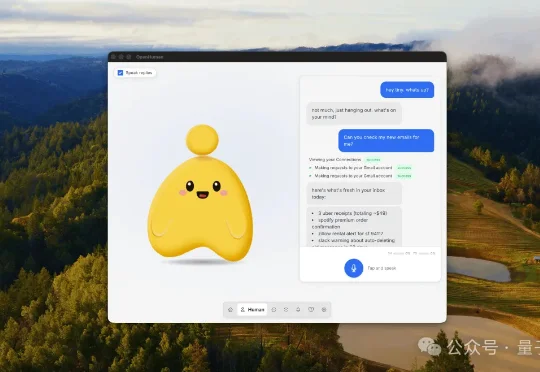
虾在前,马当道,居然还有新物种能在Agent赛道突出重围。OpenHuman连续霸榜GitHub Trending第一,狂揽9k+ Star,一天就涨千星。和虾马不一样,Human不用你花心思养,还能反过来主动了解你。
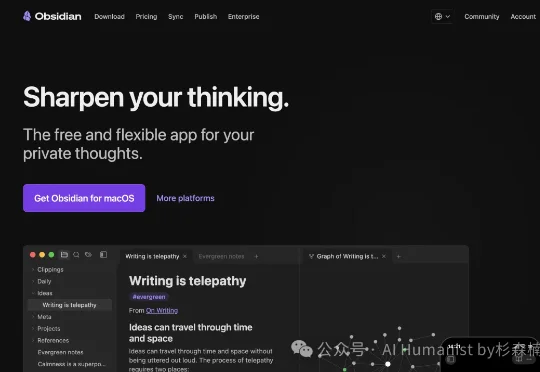
最近很多朋友问我用什么笔记软件。我说 Obsidian。其中一个主要原因是:大家使用 Obsidian 的时间点是在「AI 时代」之前,而现在,Claude Code 时代下的 Obsidian 已经完全完全成了「最强笔记软件」。