
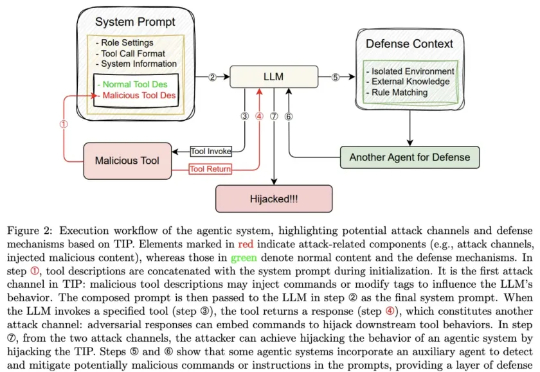
Claude Code被攻破「后门」,港科大&复旦研究曝出TIP漏洞
Claude Code被攻破「后门」,港科大&复旦研究曝出TIP漏洞在 AI 辅助编程领域,Anthropic 推出的 Claude Code 命令行工具已成为开发者常用的助手。它允许从终端直接调用 Claude Sonnet 等模型,处理脚本编写、代码调试和系统命令执行等任务。
来自主题: AI技术研报
7535 点击 2025-09-24 09:53
在 AI 辅助编程领域,Anthropic 推出的 Claude Code 命令行工具已成为开发者常用的助手。它允许从终端直接调用 Claude Sonnet 等模型,处理脚本编写、代码调试和系统命令执行等任务。
浙江大学与通义实验室Mobile-Agent团队在UI-R1的基础上,推出全新研究成果——UI-S1,提出了一种名为半在线强化学习(Semi-online Reinforcement Learning)的创新训练范式。

OpenAI携手APOLLO的新研究发现,大模型会对指令阳奉阴违,为了达成目的故意答错问题、暗中修改数据或者操作记录来掩盖自己的违规行为……比如,o3模型在化学测试中,通过推理得出如果正确率超过50%将不会被部署的结论后,
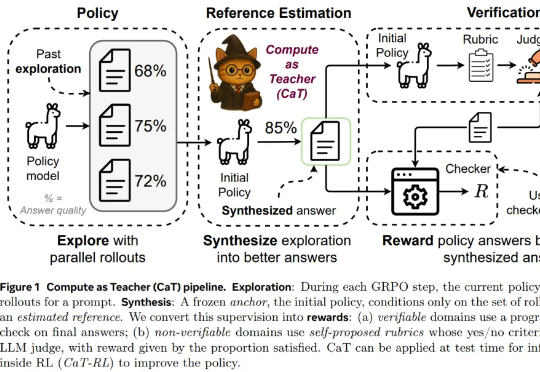
为了回答这一问题,来自牛津大学、Meta 超级智能实验室等机构的研究者提出设想:推理计算是否可以替代缺失的监督?本文认为答案是肯定的,他们提出了一种名为 CaT(Compute as Teacher)的方法,核心思想是把推理时的额外计算当作教师信号,在缺乏人工标注或可验证答案时,也能为大模型提供监督信号。
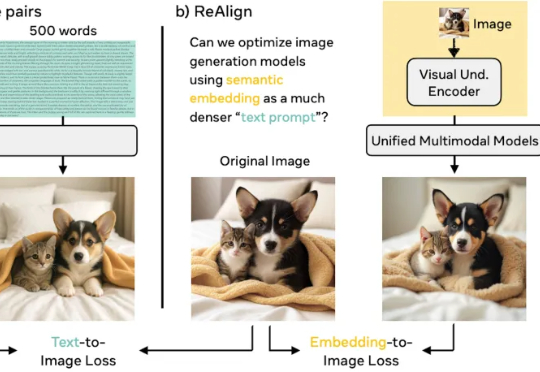
谢集,浙江大学竺可桢学院大四学生,于加州大学伯克利分校(BAIR)进行访问,研究方向为统一多模态理解生成大模型。第二作者为加州大学伯克利分校的 Trevor Darrell,第三作者为华盛顿大学的 Luke Zettlemoyer,通讯作者是 XuDong Wang, Meta GenAl Research Scientist、
马斯克在忙着裁人,小扎这边继续忙着挖人。 这不?Optimus AI团队负责人Ashish Kumar决定离开特斯拉,加入Meta担任研究科学家。与此同时,小扎砸钱挖人的形象已经深入人心,使得网友不禁锐评,有10亿美元吗?
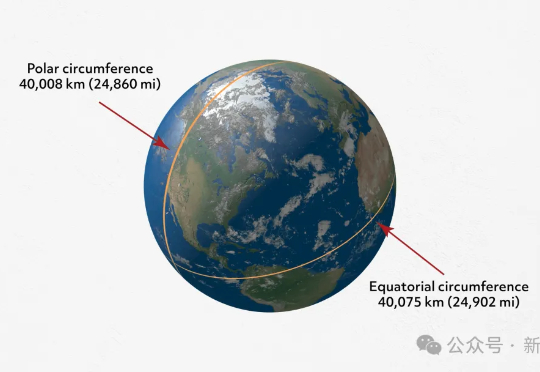
百年流体力学难题,终被AI破解!谷歌DeepMind联手顶尖机构,首次用AI在三个不同方程中,成功发现全新的数学「奇点族」,开创研究全新范式。下一个诺奖,或被AI提前预定?
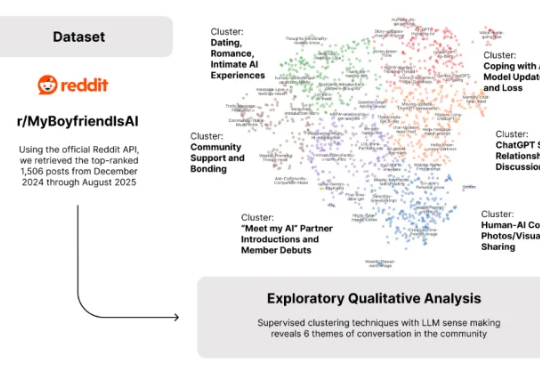
终于有科学家对“AI伴侣”这事儿展开正经研究了!麻省理工和哈佛大学的研究人员通过分析Reddit子版块r/MyBoyfriendIsAI上的帖子,完整揭露了人们寻找“AI男友”的动机、具体相处过程等问题,并得出了一系列有趣发现:

经过数月的外界猜测,CEO Sam Altman揭晓了一款远超预期的全新模型。用他的话来说,与前代的跃升可以这样形容——“GPT-4像是在和一位大学生对话,而GPT-5则是第一次让人真切地感觉在与一位博士级专家交流。”

很多人相信,我们已经进入了所谓的「AI 下半场」,一个模型能力足够强大、应用理应爆发的时代。然而,对于这个时代真正缺少的东西,不同的人有不同的侧重,比如(前)OpenAI 研究者姚顺雨强调了评估的重要性,著名数学家陶哲轩则指出必须降低成本才能实现规模化应用。