

亚马逊押注,10万人疯抢测试资格,好莱坞的新导演,还是 AI 的新剧本?
亚马逊押注,10万人疯抢测试资格,好莱坞的新导演,还是 AI 的新剧本?“听说 Showrunner AI 能直接生成剧本,还被好莱坞大导演抢着用。”我对这种跨界的 “新物种” 总是充满好奇,这玩意儿,是不是又一个噱头?虽仍处于封闭测试的阶段,却已有超 10 万用户挤入等候名单。这个 Showrunner AI,得好好研究研究。
来自主题: AI资讯
7145 点击 2025-08-09 17:17
“听说 Showrunner AI 能直接生成剧本,还被好莱坞大导演抢着用。”我对这种跨界的 “新物种” 总是充满好奇,这玩意儿,是不是又一个噱头?虽仍处于封闭测试的阶段,却已有超 10 万用户挤入等候名单。这个 Showrunner AI,得好好研究研究。
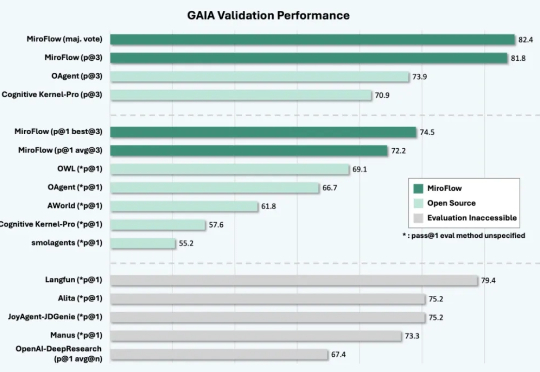
全栈开源生态系统:涵盖Agent框架(MiroFlow)、模型(MiroThinker)、数据(MiroVerse)和训练基础设施(MiroTrain / MiroRL)的全栈开源方案,所有组件和流程均开放共享,便于学习、复用与二次开发。

这位AI创始人靠打造医生专用的“ChatGPT”成为亿万富豪。丹尼尔·纳德勒(Daniel Nadler)创办了OpenEvidence,帮医生们从海量医学研究中理出头绪。如今,他已筹得2.1亿美元资金,公司估值达35亿美元。
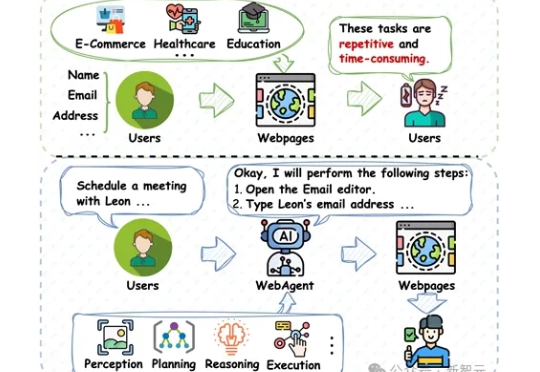
互联网技术的发展极大地便利了我们的生活,但许多网络任务重复繁琐,降低了效率。为了解决这一问题,研究人员正在开发基于大型基础模型(LFMs)的智能体——WebAgents,通过感知环境、规划推理和执行交互来完成用户指令,显著提升便利性。香港理工大学的研究人员从架构、训练和可信性等角度,总结了WebAgents的代表性方法,全面梳理了相关研究进展。
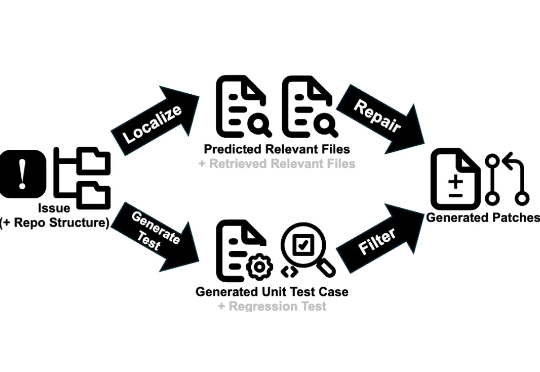
近日,一项由北京大学、字节跳动 Seed 团队及香港大学联合进行的研究,提出了一种名为「SWE-Swiss」的完整「配方」,旨在高效训练用于解决软件工程问题的 AI 模型。研究团队推出的 32B 参数模型 SWE-Swiss-32B,在权威基准 SWE-bench Verified 上取得了 60.2% 的准确率,在同尺寸级别中达到了新的 SOTA。
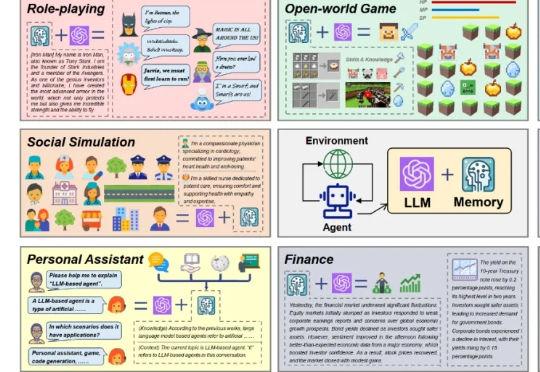
近期,基于大语言模型的智能体(LLM-based agent)在学术界和工业界中引起了广泛关注。对于智能体而言,记忆(Memory)是其中的重要能力,承担了记录过往信息和外部知识的功能,对于提高智能体的个性化等能力至关重要。

谷歌DeepMind的Genie 3是如何诞生的?这位主持人深入探访实验室内部,全球独家首测了Genie 3,扒出超多震撼细节。同时,前谷歌研究员的笔记中,也曝光了使用初体验,他直言:炸裂,Genie 3让我看到了游戏未来五年的尽头!

就在刚刚,智能体国家队集结,中国电子技术标准化研究院联合80余家产学研用单位,正式发起《智能体协议共建共享联合倡议》,智能体的中国方案来了!
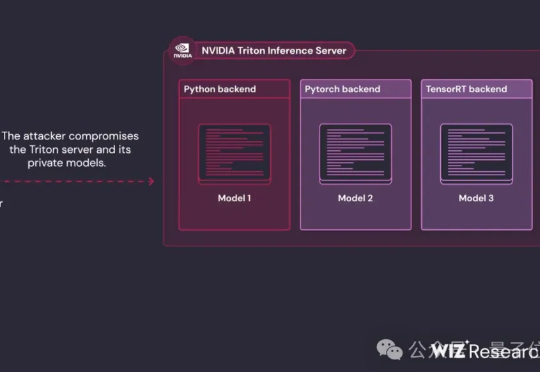
一波未平,一波又起。 英伟达Triton推理服务器,被安全研究机构Wiz Research曝光了一组高危漏洞链。
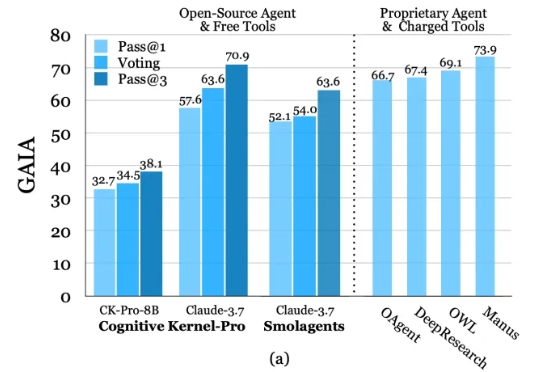
深度研究智能体(Deep Research Agents)凭借大语言模型(LLM)和视觉-语言模型(VLM)的强大能力,正在重塑知识发现与问题解决的范式。