
0.6B VLM重塑AI修图推理流程,支持手机端侧部署,vivo+浙大出品
0.6B VLM重塑AI修图推理流程,支持手机端侧部署,vivo+浙大出品如今手机拍照已成日常,后期修图是提升照片质感的关键。
来自主题: AI技术研报
9434 点击 2026-06-15 09:21
 搜索
搜索
如今手机拍照已成日常,后期修图是提升照片质感的关键。

好家伙,卡帕西又说对了!

三年后,这个判断变成了一家叫FrontierX的公司,和它的产品Aura——一个球形的、能在室内自由移动、端侧部署感知和模型的「开放定义的机器人」。FrontierX诞生于杭州,是一家以感知智能为核心的AI原生硬件公司,由来自浙江大学和阿里巴巴的团队创立。团队背景多元,涵盖硬件工程师、算法工程师、产品经理和工业设计师。
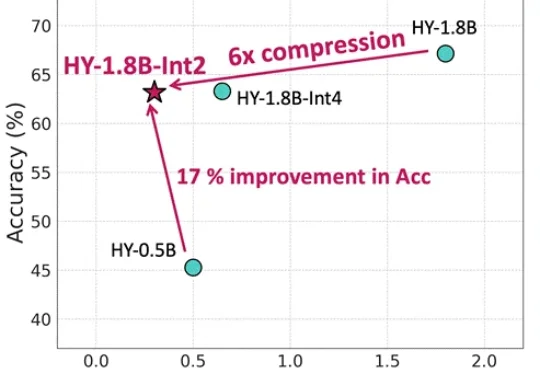
等效参数量仅0.3B,内存占用仅600MB,更适合端侧部署还带思维链的模型来了。腾讯混元最新推出面向消费级硬件场景的“极小”模型HY-1.8B-2Bit,体量甚至比常用的一些手机应用还小。
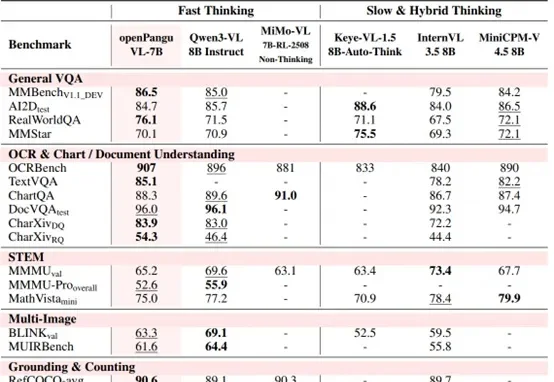
7B量级模型,向来是端侧部署与个人开发者的心头好。
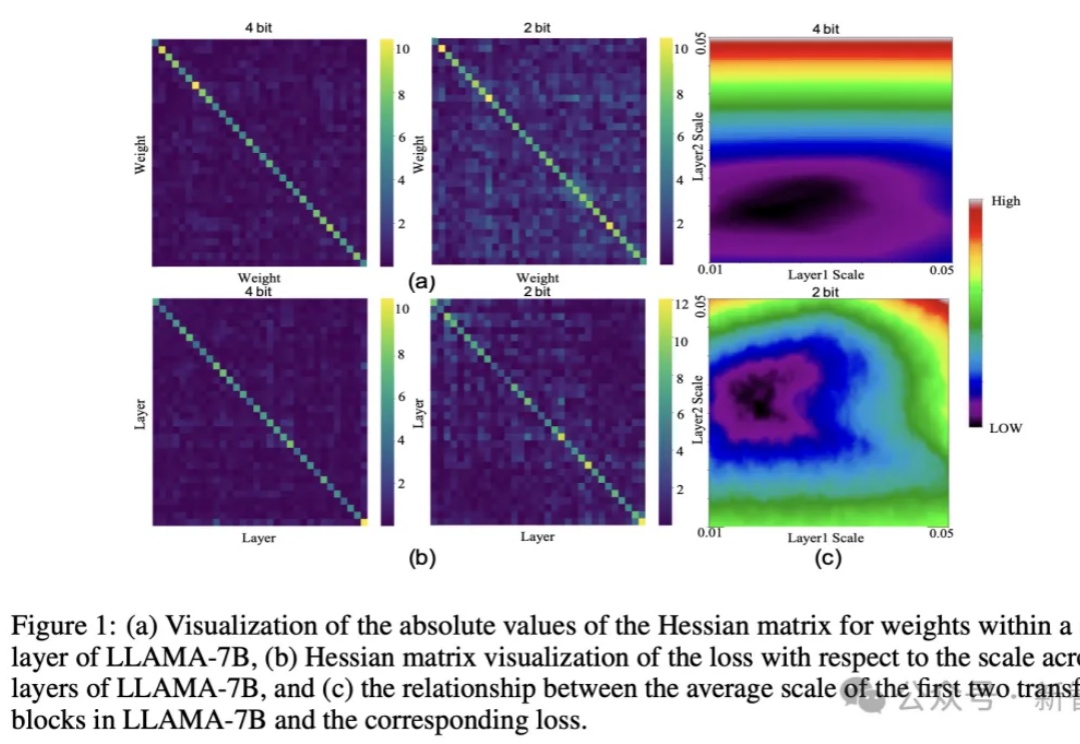
大模型巨无霸体量,让端侧部署望而却步?华为联手中科大提出CBQ新方案,仅用0.1%的训练数据实现7倍压缩率,保留99%精度。
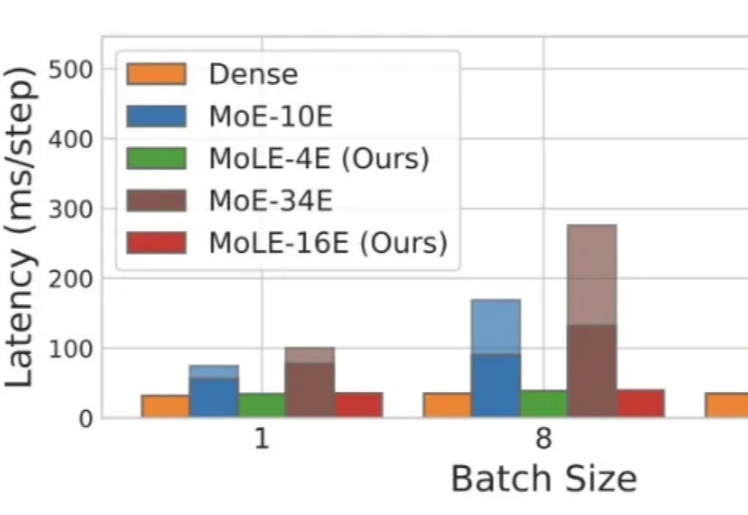
Mixture-of-Experts(MoE)在推理时仅激活每个 token 所需的一小部分专家,凭借其稀疏激活的特点,已成为当前 LLM 中的主流架构。然而,MoE 虽然显著降低了推理时的计算量,但整体参数规模依然大于同等性能的 Dense 模型,因此在显存资源极为受限的端侧部署场景中,仍然面临较大挑战。
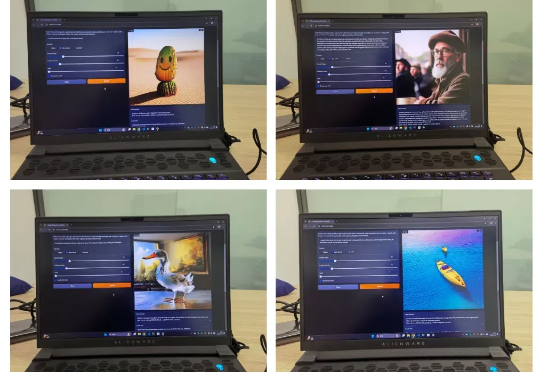
香港大学联合上海人工智能实验室,华为诺亚方舟实验室提出高效扩散模型 LiT:探索了扩散模型中极简线性注意力的架构设计和训练策略。LiT-0.6B 可以在断网状态,离线部署在 Windows 笔记本电脑上,遵循用户指令快速生成 1K 分辨率逼真图片。

T-MAC是一种创新的基于查找表(LUT)的方法,专为在CPU上高效执行低比特大型语言模型(LLMs)推理而设计,无需权重反量化,支持混合精度矩阵乘法(mpGEMM),显著降低了推理开销并提升了计算速度。

有CPU就能跑大模型,性能甚至超过NPU/GPU!