自回归科学基座模型 BigBang-Proton,提出实现 AGI 的新路线
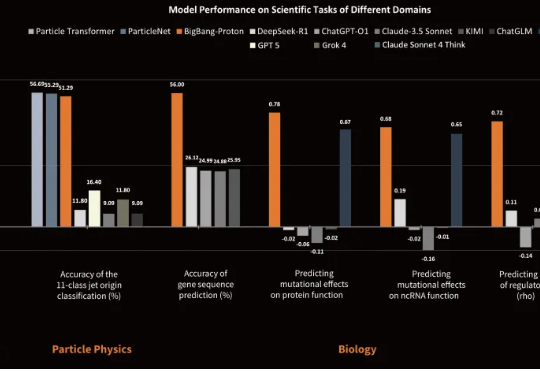
自回归科学基座模型 BigBang-Proton,提出实现 AGI 的新路线近日,专注于研发物质世界基座模型的公司超越对称(上海)技术有限公司(超对称)发布了新版基座模型 BigBang-Proton,成功实现多个真实世界的专业学科问题与 LLM 的统一预训练和推理,挑战了 Sam Altman 和主流的 AGI 技术路线。
来自主题: AI技术研报
9391 点击 2025-11-07 15:03
 搜索
搜索
近日,专注于研发物质世界基座模型的公司超越对称(上海)技术有限公司(超对称)发布了新版基座模型 BigBang-Proton,成功实现多个真实世界的专业学科问题与 LLM 的统一预训练和推理,挑战了 Sam Altman 和主流的 AGI 技术路线。

大模型一个token一个token生成,效率太低怎么办?

谷歌遗珠与IBM预言:一文点醒Karpathy,扩散模型或成LLM下一步。
在多模态生成领域,由视频生成音频(Video-to-Audio,V2A)的任务要求模型理解视频语义,还要在时间维度上精准对齐声音与动态。早期的 V2A 方法采用自回归(Auto-Regressive)的方式将视频特征作为前缀来逐个生成音频 token,或者以掩码预测(Mask-Prediction)的方式并行地预测音频 token,逐步生成完整音频。
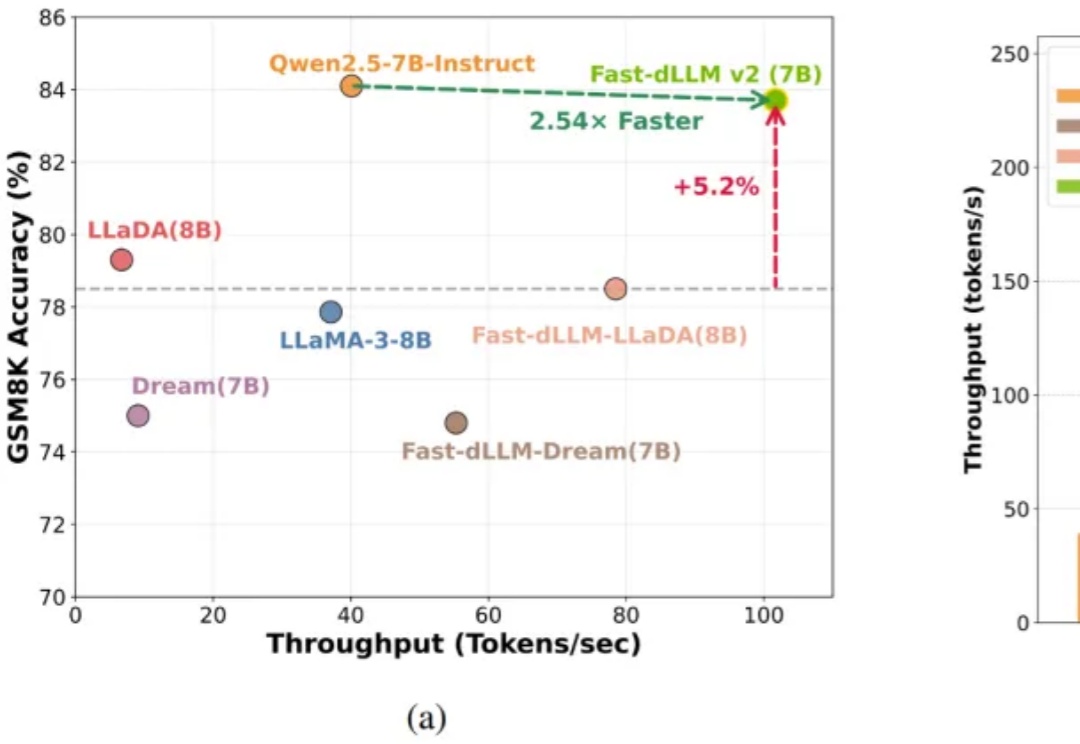
自回归(AR)大语言模型逐 token 顺序解码的范式限制了推理效率;扩散 LLM(dLLM)以并行生成见长,但过去难以稳定跑赢自回归(AR)模型,尤其是在 KV Cache 复用、和 可变长度 支持上仍存挑战。
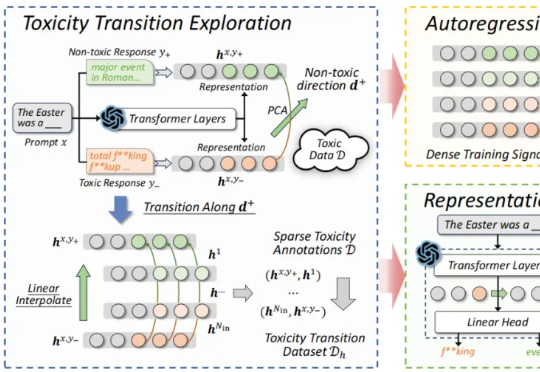
近期,来自北航等机构的研究提出了一种新的解决思路:自回归奖励引导表征编辑(ARGRE)框架。该方法首次在 LLM 的潜在表征空间中可视化了毒性从高到低的连续变化路径,实现了在测试阶段进行高效「解毒」。

近期,扩散语言模型备受瞩目,提供了一种不同于自回归模型的文本生成解决方案。为使模型能够在生成过程中持续修正与优化中间结果,西湖大学 MAPLE 实验室齐国君教授团队成功训练了具有「再掩码」能力的扩散语言模型(Remasking-enabled Diffusion Language Model, RemeDi 9B)。

扩散语言模型(Diffusion Language Models,DLM)一直以来都令研究者颇感兴趣,因为与必须按从左到右顺序生成的自回归模型(Autoregressive, AR)不同,DLM 能实现并行生成,这在理论上可以实现更快的生成速度,也能让模型基于前后文更好地理解生成语境。

挑战自回归的扩散语言模型刚刚迎来了一个新里程碑:蚂蚁集团和人大联合团队用 20T 数据,从零训练出了业界首个原生 MoE 架构扩散语言模型 LLaDA-MoE。该模型虽然激活参数仅 1.4B,但性能可以比肩参数更多的自回归稠密模型 Qwen2.5-3B,而且推理速度更快。这为扩散语言模型的技术可行性提供了关键验证。

AI图像编辑技术发展迅猛,扩散模型凭借强大的生成能力,成为行业主流。 但这类模型在实际应用中始终面临两大难题:一是“牵一发而动全身”,即便只想修改一个细节,系统也可能影响到整个画面;二是生成速度缓慢,难以满足实时交互的需求。