自回归模型杀回图像生成!实现像素级精准控制,比Diffusion更高效可控
自回归模型杀回图像生成!实现像素级精准控制,比Diffusion更高效可控当下的AI图像生成领域,Diffusion模型无疑是绝对的王者,但在精准控制上却常常“心有余而力不足”。
来自主题: AI技术研报
10565 点击 2025-07-30 10:55
 搜索
搜索
当下的AI图像生成领域,Diffusion模型无疑是绝对的王者,但在精准控制上却常常“心有余而力不足”。

近年来,语言模型的显著进展主要得益于大规模文本数据的可获得性以及自回归训练方法的有效性。
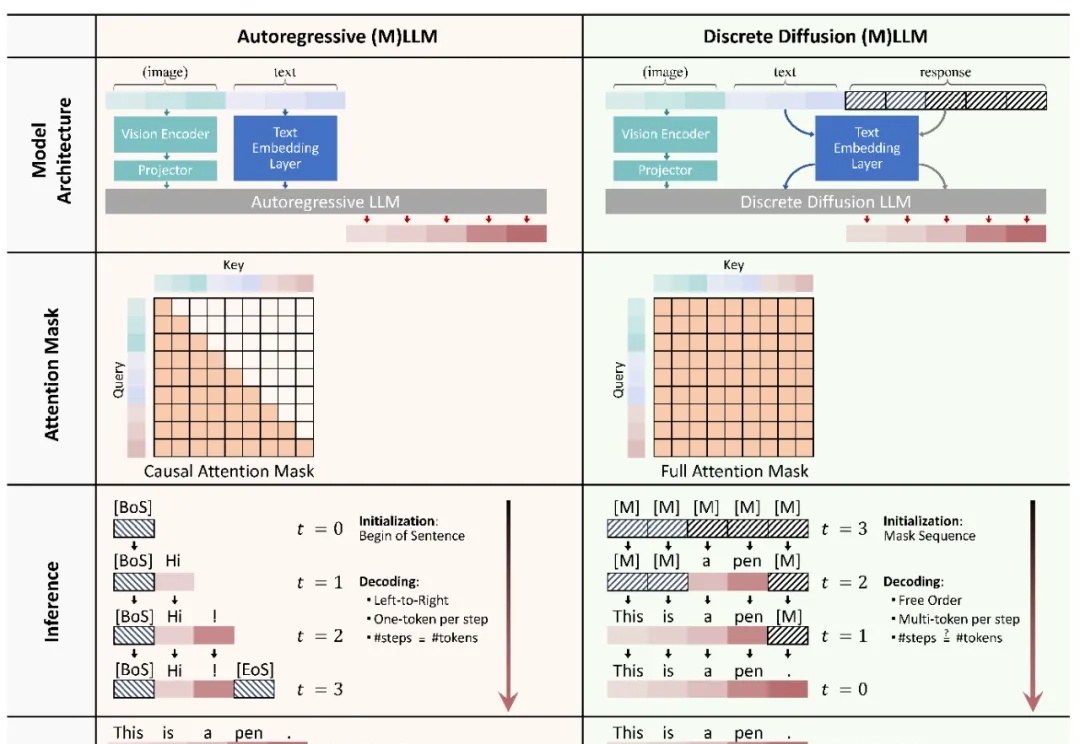
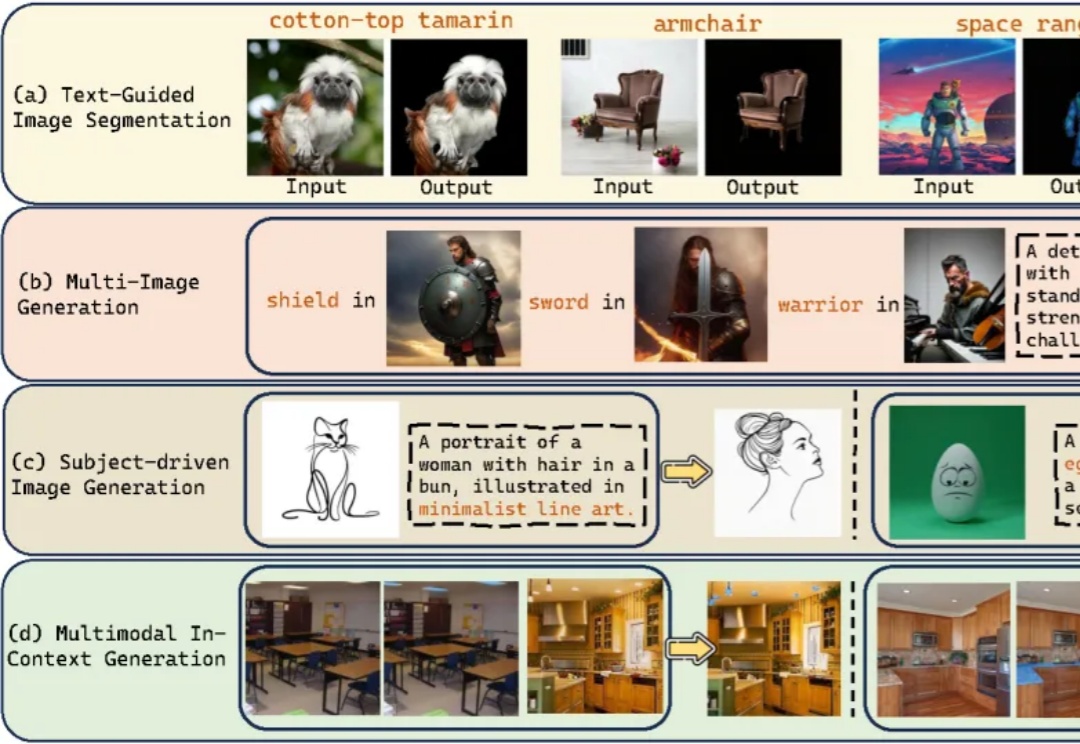
本文主要介绍 xML 团队的论文:Discrete Diffusion in Large Language and Multimodal Models: A Survey。
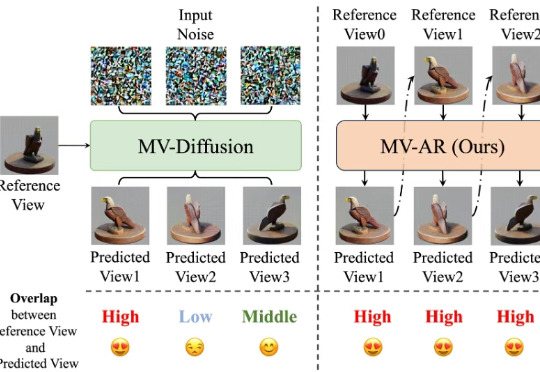
本文介绍并开发了一种自回归生成多视图图像的方法 MVAR 。其目的是确保在生成当前视图的过程中,模型能够从所有先前的视图中提取有效的引导信息,从而增强多视图的一致性。
谁说扩散模型只能生成图像和视频?现在它们能高质量地写代码了,速度还比传统大模型更快!Inception Labs推出基于扩散技术的全新商业级大语言模型——Mercury。
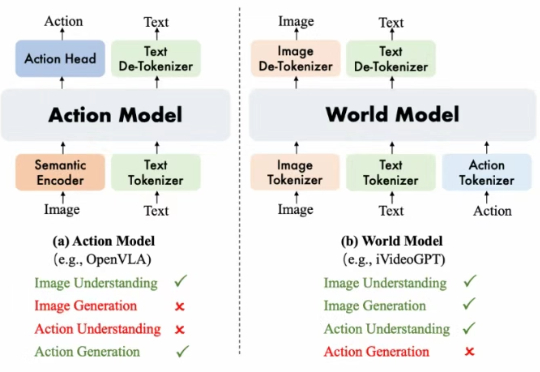
阿里巴巴达摩院提出了 WorldVLA, 首次将世界模型 (World Model) 和动作模型 (Action Model/VLA Model) 融合到了一个模型中。WorldVLA 是一个统一了文本、图片、动作理解和生成的全自回归模型。
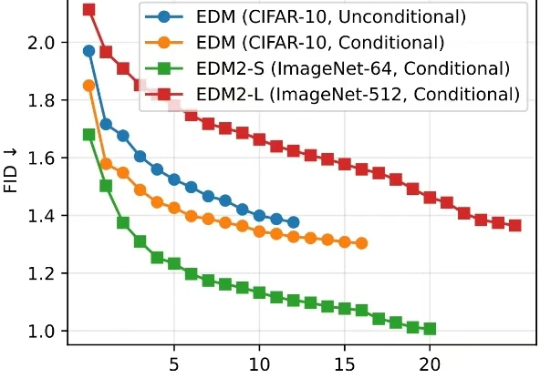
清华大学朱军教授团队与 NVIDIA Deep Imagination 研究组联合提出一种全新的视觉生成模型优化范式 —— 直接判别优化(DDO)。

扩散建模+自回归,打通文本生成任督二脉!这一次,来自康奈尔、CMU等机构的研究者,提出了前所未有的「混合体」——Eso-LM。有人惊呼:「自回归危险了。」

在A100上用310M模型,实现每秒超30帧自回归视频生成,同时画面还保持高质量!
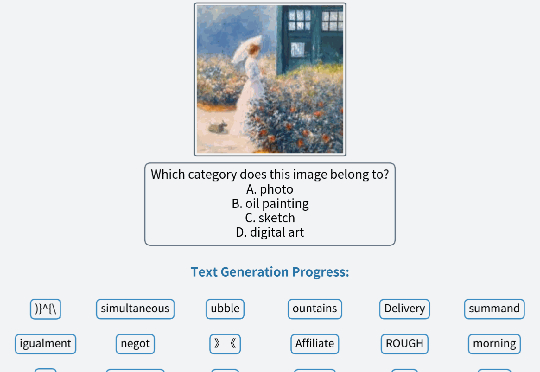
王劲,香港大学计算机系二年级博士生,导师为罗平老师。研究兴趣包括多模态大模型训练与评测、伪造检测等,有多项工作发表于 ICML、CVPR、ICCV、ECCV 等国际学术会议。