冲击自回归,扩散模型正在改写下一代通用模型范式
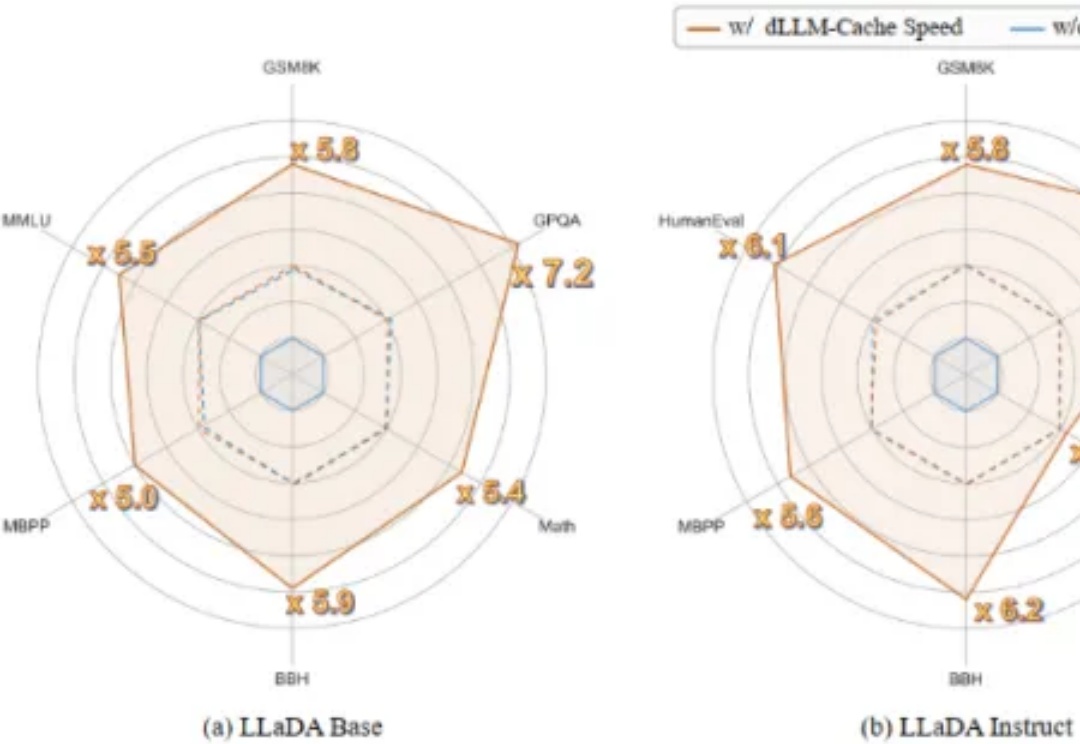
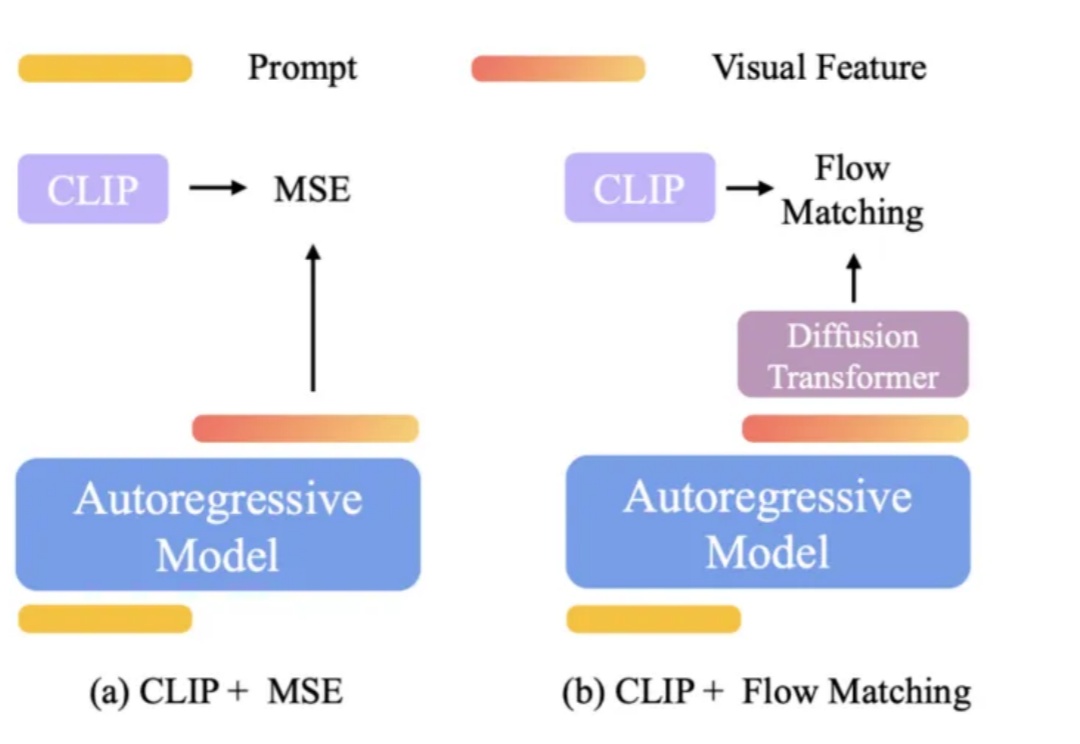
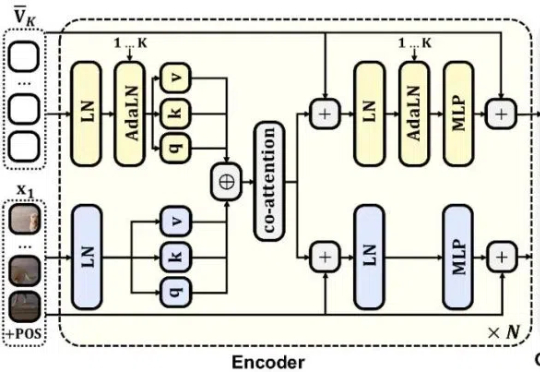
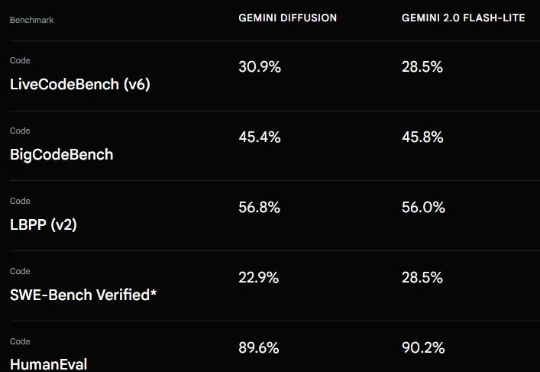
冲击自回归,扩散模型正在改写下一代通用模型范式上个月 21 号,Google I/O 2025 开发者大会可说是吸睛无数,各种 AI 模型、技术、工具、服务、应用让人目不暇接。在这其中,Gemini Diffusion 绝对算是最让人兴奋的进步之一。从名字看得出来,这是一个采用了扩散模型的 AI 模型,而这个模型却并非我们通常看到的扩散式视觉生成模型,而是一个地地道道的语言模型!
来自主题: AI技术研报
8700 点击 2025-06-04 14:04